









[AI达人特训营]印度vs津巴布韦!板球比赛语义分割
时间:2025-07-29 作者:游乐小编
本文对印度与津巴布韦板球比赛场景进行语义分割研究,使用U-Net、PP-LiteSeg和SegFormer三个模型。数据集含9个类别,经解压、重命名等预处理后用于训练。评估显示,PP-LiteSeg效果最佳,mIoU达0.7751,SegFormer次之,U-Net表现稍弱,最后还进行了模型部署。
![[AI达人特训营]印度vs津巴布韦!板球比赛语义分割 - 游乐网](https://www.youleyou.com/uploadfile/2025/0729/20250729121920249.jpg)
印度vs津巴布韦!板球比赛语义分割
在本次板球分割任务中,我先后使用了三个模型来比较语义分割的效果,分别是U-Net、PP-LiteSeg和SegFormer。在实际检测中,PP-LiteSeg模型的预测效果还是不错的,整体情况如下:
| 模型名称 | mIoU | Acc | Kappa | Dice |
|---|---|---|---|---|
| U-Net | 0.5752 | 0.9700 | 0.9065 | 0.6856 |
| PP-LiteSeg | 0.7751 | 0.9865 | 0.9594 | 0.8632 |
| SegFormer | 0.7669 | 0.9877 | 0.9625 | 0.8593 |
一、项目背景
语义分割是指从图像中提取特征信息,并将这些特征信息转换为对应的类别。这些类别可以是人、汽车、花朵、家具等。在计算机视觉和机器学习领域,语义分割是一个热门的研究方向,因为它在自动驾驶、室内导航、虚拟现实/增强现实等应用中有着广泛的应用。在这些应用中,我们需要准确地将图像中的每个像素映射到一个特定的类别中,以便更好地理解和处理图像。例如,在本项目中,我们可以使用语义分割模型将板球比赛场景分为击球手,投球手,检票口守门员,外野手,球,裁判员,检票口,地面和背景共9个类别。
二、数据集介绍
该数据集来自公开媒体的印度和津巴布韦之间的比赛,每 298 帧拍摄 12 帧,并替换其中的一些模糊的帧和异常值。该数据集适用于训练有关体育分析的检测模型,不过更偏向于板球。 该数据集包含9个类别:击球手,投球手,检票口守门员,外野手,球,裁判员,检票口,地面和背景。
部分数据如下:
![[AI达人特训营]印度vs津巴布韦!板球比赛语义分割 - 游乐网](https://www.youleyou.com/uploadfile/2025/0729/20250729121920934.jpg)
三、数据预处理
Step01: 解压数据集
ERROR1:
/bin/bash: -c: 行 0: 未预期的符号 `(' 附近有语法错误/bin/bash: -c: 行 0: `unzip /home/aistudio/data/data192893/archive (1).zip -d /home/aistudio/work/' SOLUTION1: 重命名文件夹 archive(1).zip -> archive.zip
In [ ]
!unzip /home/aistudio/data/data192893/archive.zip -d /home/aistudio/work/
Step02: 重命名文件夹。www.acmeai.tech ODataset 4 - Cricket Semantic Segmentation -> cricket
Step03: 分开不同后缀的文件。
在/home/aistudio/work目录下新建images、jsons、labels和save文件夹。
- images:原始图像。
- labels:标注文件。
在本次项目中只需要用到images和labels两个文件夹。
In [5]
!mv /home/aistudio/work/cricket/images/*.png___fuse.png /home/aistudio/work/labels/!mv /home/aistudio/work/cricket/images/*.png___pixel.json /home/aistudio/work/jsons/!mv /home/aistudio/work/cricket/images/*.png___save.png /home/aistudio/work/save/!mv /home/aistudio/work/cricket/images/*.png /home/aistudio/work/images/
Step04: 修改文件后缀名。
In [ ]
%cd /home/aistudio/work/labels/!rename 's/.png___fuse.png/.png/' ./*
四、代码实现
4.1 环境配置
从Github下载PaddleSeg代码。
In [ ]
%cd /home/aistudio/!git clone https://github.com/PaddlePaddle/PaddleSeg
执行如下命令,从源码编译安装PaddleSeg包。大家对于PaddleSeg/paddleseg目录下的修改,都会立即生效,无需重新安装。
In [ ]
%cd /home/aistudio/PaddleSeg/!pip install -r requirements.txt!pip install -v -e .
4.2 数据准备
Step01: 将数据集移动到/home/aistudio/PaddleSeg/data/cricket目录下。
首先要在/home/aistudio/PaddleSeg目录下新建data和cricket文件夹。
In [8]
!mv /home/aistudio/work/images /home/aistudio/PaddleSeg/data/cricket/!mv /home/aistudio/work/labels /home/aistudio/PaddleSeg/data/cricket/
In [ ]
%cd /home/aistudio/PaddleSeg/data/cricket/images/!rename 's/ (/\_/' ./*!rename 's/).png/.png/' ./*%cd /home/aistudio/PaddleSeg/data/cricket/labels/!rename 's/ (/\_/' ./*!rename 's/).png/.png/' ./*
Step02: 将彩色标注图转换成灰度标注图
首先找到各个类别对应的RGB像素值,结果如下所示:
- Background:#916041 对应RGB (145,96,65)
- Ground:#e2d5de 对应RGB (226,213,222)
- Bowler:#0018fd 对应RGB (0,24,253)
- Batsmen:#b07a53 对应RGB (176,122,83)
- Wicket Keeper:#8fdfa9 对应RGB (143,223,169)
- Umpire:#e20959 对应RGB (226,9,89)
- Fielder:#c2fe6b 对应RGB (194,254,107)
- Ball:#5e8d38 对应RGB (94,141,56)
- Wicket:#1e472a 对应RGB (30,71,42)
然后,实现RGB像素值到灰度值的映射关系。
In [ ]
import osimport numpy as npfrom PIL import Imagefrom tqdm import tqdmOrigin_SegmentationClass_path = "/home/aistudio/PaddleSeg/data/cricket/labels"Out_SegmentationClass_path = "/home/aistudio/PaddleSeg/data/cricket/mask"# 对应关系Origin_Point_Value = np.array([[145, 96, 65], [226, 213, 222], [0, 24, 253], [176, 122, 83], [143, 223, 169], [226, 9, 89], [194, 254, 107], [94, 141, 56], [30, 71, 42]])Out_Point_Value = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8])if __name__ == "__main__": if not os.path.exists(Out_SegmentationClass_path): os.makedirs(Out_SegmentationClass_path) # png_names = os.listdir(Origin_SegmentationClass_path) # 获得图片的文件名 print("正在遍历全部标签。") for png_name in tqdm(png_names): if png_name == ".ipynb_checkpoints": continue png = Image.open(os.path.join(Origin_SegmentationClass_path, png_name)) # RGB w, h = png.size png = np.array(png, np.uint8) # h, w, c out_png = np.zeros([h, w]) # 灰度 h, w for map_idx, rgb in enumerate(Origin_Point_Value): idx = np.where( (png[..., 0] == rgb[0]) & (png[..., 1] == rgb[1]) & (png[..., 2] == rgb[2])) out_png[idx] = map_idx # print("out_png:", out_png.shape) out_png = Image.fromarray(np.array(out_png, np.uint8)) # 再次转化为Image进行保存 out_png.save(os.path.join(Out_SegmentationClass_path, png_name)) # 统计输出,各个像素点的值的个数 print("正在统计输出的图片每个像素点的数量。") classes_nums = np.zeros([256], np.int32) for png_name in tqdm(png_names): if png_name == ".ipynb_checkpoints": continue png_file_name = os.path.join(Out_SegmentationClass_path, png_name) if not os.path.exists(png_file_name): raise ValueError("未检测到标签图片%s,请查看具体路径下文件是否存在以及后缀是否为png。" % (png_file_name)) png = np.array(Image.open(png_file_name), np.uint8) classes_nums += np.bincount(np.reshape(png, [-1]), minlength=256) print("打印像素点的值与数量。") print('-' * 37) print("| %15s | %15s |" % ("Key", "Value")) print('-' * 37) for i in range(256): if classes_nums[i] > 0: print("| %15s | %15s |" % (str(i), str(classes_nums[i]))) print('-' * 37) 最后,为了判断转换的结果是否正确,我们可以使用PaddleSeg提供的转换工具,将灰度标注图转换成伪彩色标注图。
In [ ]
!python tools/data/gray2pseudo_color.py /home/aistudio/PaddleSeg/data/cricket/mask /home/aistudio/PaddleSeg/data/cricket/output
处理结果如下:
- 左上:板球比赛原图。
- 右上:板球比赛原标注图。
- 左下:转换得到的训练用的灰度标注图
- 右下:通过PaddleSeg的转换工具得到的伪彩色标注图,用于判断转换结果是否正确。
![[AI达人特训营]印度vs津巴布韦!板球比赛语义分割 - 游乐网](https://www.youleyou.com/uploadfile/2025/0729/20250729121921661.jpg)
Step03: 切分数据。
In [ ]
%cd /home/aistudio/PaddleSeg/!python tools/data/split_dataset_list.py /home/aistudio/PaddleSeg/data/cricket images mask --format "png" "png" --split 0.7 0.3 0
4.3 模型训练
PP-LiteSeg
PP-LiteSeg提出三个创新模块:
- 解码模块(FLD)调整解码模块中通道数,平衡编码模块和解码模块的计算量。
- 注意力融合模块(UAFM)加强特征表示。
- 简易金字塔池化模块(SPPM)减小中间特征图的通道数、移除跳跃连接。
![[AI达人特训营]印度vs津巴布韦!板球比赛语义分割 - 游乐网](https://www.youleyou.com/uploadfile/2025/0729/20250729121921648.jpg)
准备好配置文件后,我们使用tools/train.py脚本进行模型训练。
In [ ]
!python tools/train.py --config configs/pp_liteseg/pp_liteseg_stdc2_cityscapes_1024x512_scale1.0_160k.yml --save_dir output/pp_liteseg --save_interval 2000 --num_workers 2 --do_eval --use_vdl
如果训练中断,我们可以恢复训练,避免从头开始训练。通过给train.py脚本设置resume_model输入参数,加载中断前最近一次保存的模型信息,恢复训练。
In [ ]
!python tools/train.py --config configs/pp_liteseg/pp_liteseg_stdc2_cityscapes_1024x512_scale1.0_160k.yml --save_dir output/pp_liteseg --save_interval 2000 --resume_model output/pp_liteseg/iter_52000 --num_workers 2 --do_eval --use_vdl
损失函数如下:
![[AI达人特训营]印度vs津巴布韦!板球比赛语义分割 - 游乐网](https://www.youleyou.com/uploadfile/2025/0729/20250729121921592.jpg)
U-Net
U-Net网络结构因为形似字母“U”而得名,最早是在医学影像的细胞分割任务中提出,结构简单适合处理小数量级的数据集。比较于FCN网络的像素相加,U-Net是对通道进行concat操作,保留上下文信息的同时,加强了它们之间的语义联系。整体是一个Encode-Decode的结构,如下图所示。
- 知识点1:下采样Encode包括conv和max pool,上采样Decode包括up-conv和conv。
- 知识点2:U-Net特点在于灰色箭头,利用通道融合使上下文信息紧密联系起来。
![[AI达人特训营]印度vs津巴布韦!板球比赛语义分割 - 游乐网](https://www.youleyou.com/uploadfile/2025/0729/20250729121921187.jpg)
In [ ]
!python tools/train.py --config configs/unet/unet_cityscapes_1024x512_160k.yml --save_dir output/unet --save_interval 2000 --num_workers 2 --do_eval --use_vdl
In [ ]
!python tools/train.py --config configs/unet/unet_cityscapes_1024x512_160k.yml --save_dir output/unet --save_interval 2000 --resume_model output/unet/iter_56000 --num_workers 2 --do_eval --use_vdl
SegFormer
SegFormer是一种将Transformer和轻量级的MLP相结合的语义分割框架。该框架的优势在于:
- 知识点1:层次化的transformer编码器/MiT,生成不同尺度特征;
- 知识点2:轻量的全MLP解码器,融合不同层级特征。
![[AI达人特训营]印度vs津巴布韦!板球比赛语义分割 - 游乐网](https://www.youleyou.com/uploadfile/2025/0729/20250729121921794.jpg)
In [ ]
!python tools/train.py --config configs/segformer/segformer_b5_cityscapes_1024x512_160k.yml --save_dir output/segformer --save_interval 2000 --num_workers 2 --do_eval --use_vdl
In [ ]
!python tools/train.py --config configs/segformer/segformer_b5_cityscapes_1024x512_160k.yml --save_dir output/segformer --save_interval 2000 --resume_model output/segformer/iter_34000 --num_workers 2 --do_eval --use_vdl
恢复训练中,大家可能会遇到一个问题,那就是日志文件是分割开的,接下来我们可以通过以下代码合并日志文件。
- 将所有的x.log文件拷贝到一个logs目录下。
- 将代码中的target_dir设置为上一步logs的根目录,运行后,会生成一个与logs同级的目录merge,merge下的x.log文件即包含了完整训练数据。
- 可视化。
In [ ]
import osfrom visualdl import LogReader, LogWriterdef trans_vdlrecords_to_txt(vdl_file_path): txt_path = vdl_file_path.replace('.log', '.txt') reader = LogReader(file_path=vdl_file_path) tags = reader.get_tags() scalar = tags.get('scalar') if scalar is not None: fo = open(txt_path, "w") fo.write(f'tags:{tags}') for tag in scalar: fo.write(f'
------------{tag}------------
') data = reader.get_data('scalar', tag) fo.write(f'The Last One is {str(data[-1])}') fo.write(str(data)) fo.close()def merge_vdlrecords(vdl_file_path, last_step_dict, writer=None): reader = LogReader(file_path=vdl_file_path) tags = reader.get_tags() scalar = tags.get('scalar') if scalar is not None: print(f'tags:{tags}') data = None for tag in scalar: data = reader.get_data('scalar', tag) for e in data: curr_last_step = last_step_dict[tag] if tag in last_step_dict else -1 if e.id > curr_last_step: writer.add_scalar(tag=tag, step=e.id, value=e.value) last_step_dict[tag] = data[-1].id print(f'{vdl_file_path} {tag} last_id is {last_step_dict[tag]}') return last_step_dictdef do_merge(target_dir): logdir = target_dir + '/merge' writer = LogWriter(logdir=logdir) last_step_dict = {} print('called1') try: for path, dir_list, file_list in os.walk(target_dir + '/logs'): print('called2', file_list) file_list.sort() for file_name in file_list: if file_name.endswith('.log'): log_path = os.path.join(path, file_name) print(log_path) last_step = merge_vdlrecords(log_path, last_step_dict, writer) except Exception as err: print(f'error {erro}') finally: writer.close()def do_trans(_dir): for path, dir_list, file_list in os.walk(_dir): for file_name in file_list: if file_name.endswith('.log'): log_path = os.path.join(path, file_name) print(log_path) trans_vdlrecords_to_txt(log_path)if __name__ == '__main__': target_dir = '/home/aistudio/PaddleSeg/output/segformer/' do_merge(target_dir) 4.4 模型评估
训练完成后,大家可以使用评估脚本tools/val.py来评估模型的精度,即对配置文件中的验证数据集进行测试。
PP-LiteSeg
In [ ]
!python tools/val.py --config configs/pp_liteseg/pp_liteseg_stdc2_cityscapes_1024x512_scale1.0_160k.yml --model_path output/pp_liteseg/best_model/model.pdparams
指标如下:
- [EVAL] #Images: 89 mIoU: 0.7751 Acc: 0.9865 Kappa: 0.9594 Dice: 0.8632
- [EVAL] Class IoU: [0.9485 0.9878 0.7535 0.8408 0.7275 0.9158 0.7254 0.4405 0.6366]
- [EVAL] Class Precision: [0.9588 0.9972 0.9282 0.9318 0.8178 0.9601 0.7737 0.6414 0.7756]
- [EVAL] Class Recall: [0.9888 0.9906 0.8001 0.8959 0.8682 0.952 0.9208 0.5845 0.7803]
U-Net
In [ ]
!python tools/val.py --config configs/unet/unet_cityscapes_1024x512_160k.yml --model_path output/unet/best_model/model.pdparams
指标如下:
- [EVAL] #Images: 89 mIoU: 0.5752 Acc: 0.9700 Kappa: 0.9065 Dice: 0.6856
- [EVAL] Class IoU: [0.8739 0.9779 0.5385 0.6238 0.4768 0.7272 0.4314 0. 0.5272]
- [EVAL] Class Precision: [0.985 0.9806 0.8682 0.7056 0.5954 0.7795 0.5945 0. 0.7845]
- [EVAL] Class Recall: [0.8857 0.9972 0.5864 0.8433 0.7053 0.9156 0.6113 0. 0.6165]
SegFormer
In [ ]
!python tools/val.py --config configs/segformer/segformer_b5_cityscapes_1024x512_160k.yml --model_path output/segformer/best_model/model.pdparams
指标如下:
- [EVAL] #Images: 89 mIoU: 0.7669 Acc: 0.9877 Kappa: 0.9625 Dice: 0.8593
- [EVAL] Class IoU: [0.959 0.991 0.6543 0.8017 0.7272 0.915 0.6649 0.4981 0.6908]
- [EVAL] Class Precision: [0.9877 0.9943 0.8839 0.863 0.8486 0.9723 0.7471 0.6818 0.8416]
- [EVAL] Class Recall: [0.9706 0.9967 0.7158 0.9186 0.8356 0.9395 0.8581 0.6491 0.7941]
4.5 模型预测
我们可以通过tools/predict.py脚本是来进行可视化预测,命令格式如下所示。
In [ ]
!python tools/predict.py --config configs/pp_liteseg/pp_liteseg_stdc2_cityscapes_1024x512_scale1.0_160k.yml --model_path output/pp_liteseg/best_model/model.pdparams --image_path data/cricket/images --save_dir output/result
部分可视化结果如下:
![[AI达人特训营]印度vs津巴布韦!板球比赛语义分割 - 游乐网](https://www.youleyou.com/uploadfile/2025/0729/20250729121922658.jpg)
当分割目标比较清晰的时候,分割效果还是很好的;但当分割目标较小时,分割效果还有待加强。
4.6 模型导出
执行如下命令,导出预测模型,保存在output/inference_model目录。
In [ ]
!python tools/export.py --config configs/pp_liteseg/pp_liteseg_stdc2_cityscapes_1024x512_scale1.0_160k.yml --model_path output/pp_liteseg/best_model/model.pdparams --save_dir output/inference_model
4.7 FastDeploy快速部署
环境准备: 本项目的部署环节主要用到的套件为飞桨部署工具FastDeploy,因此我们先安装FastDeploy。
In [ ]
!pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
部署模型:
导入飞桨部署工具FastDepoy包,创建Runtimeoption,具体实现如下代码所示。
In [1]
import fastdeploy as fdimport cv2import os
In [2]
def build_option(device='cpu', use_trt=False): option = fd.RuntimeOption() if device.lower() == "gpu": option.use_gpu() if use_trt: option.use_trt_backend() option.set_trt_input_shape("x", [1, 3, 1080, 1920]) option.set_trt_input_shape("scale_factor", [1, 2]) return option 配置模型路径,创建Runtimeoption,指定部署设备和后端推理引擎,代码实现如下所示。
In [ ]
# 配置模型路径model_path = '/home/aistudio/PaddleSeg/output/inference_model'image_path = '/home/aistudio/PaddleSeg/data/cricket/images/2024-08-24_134.png'model_file = os.path.join(model_path, "model.pdmodel")params_file = os.path.join(model_path, "model.pdiparams")config_file = os.path.join(model_path, "deploy.yaml")# 创建RuntimeOptionruntime_option = build_option(device='gpu', use_trt=False)# 创建PPYOLOE模型model = fd.vision.segmentation.PaddleSegModel(model_file, params_file, config_file, runtime_option=runtime_option)# 预测图片检测结果im = cv2.imread(image_path)result = model.predict(im.copy())print(result)# 预测结果可视化vis_im = fd.vision.vis_segmentation(im, result, weight=0.5)cv2.imwrite("/home/aistudio/work/visualized_result.jpg", vis_im)print("Visualized result save in ./visualized_result.jpg") 结果如下:
![[AI达人特训营]印度vs津巴布韦!板球比赛语义分割 - 游乐网](https://www.youleyou.com/uploadfile/2025/0729/20250729121922773.jpg)
5. 总结提高
在本次板球分割任务中,我先后使用了三个模型来比较语义分割的效果,分别是U-Net、PP-LiteSeg和SegFormer。整体情况如下:
| 模型名称 | mIoU | Acc | Kappa | Dice |
|---|---|---|---|---|
| U-Net | 0.5752 | 0.9700 | 0.9065 | 0.6856 |
| PP-LiteSeg | 0.7751 | 0.9865 | 0.9594 | 0.8632 |
| SegFormer | 0.7669 | 0.9877 | 0.9625 | 0.8593 |
小编推荐:
热门推荐
更多 -

- 与八尺大人的夏天回忆汉化冷狐
- 剧情养成 | 6.1 MB
- 2025.01.16 | 和八尺大人的夏天回顾汉...
-

- 夏哈塔
- 休闲益智 | 121.65 MB
- 2024.08.16 | 游戏简介夏哈塔手游,带...
-

- 卡在墙上的女孩2
- 休闲益智 | 21 MB
- 2024.06.01 | 游戏简介卡在墙上的女孩2...
-

- 地下教育录冷狐
- 剧情养成 | 551.3 MB
- 2025.01.16 | re地下教ru育录是一款富...
-

- 3D工口医存档
- 角色扮演 | 15.2 MB
- 2024.01.06 | 手游描述 ...
-

- 触摸深睡巴比伦游戏汉化
- 剧情养成 | 244.4 MB
- 2025.01.16 | 触摸深睡巴比伦手游汉化...
-

- beastbeat2.5.1
- 休闲益智 | 121.65 MB
- 2024.07.19 | 游戏简介beastbeat2 5 ...
-

- 流氓先生
- 飞行射击 | 14.65 MB
- 2024.08.31 | 流氓先生是一款非常好玩...
-

- 3d工口医全解锁
- 角色扮演 | 15.2 MB
- 2024.01.06 | 手游描述 ...
-

- 流氓牛仔Vs外星人
- 动作冒险 | 132.47 MB
- 2024.11.30 | 手游描述 ...
-

- 神里绫华触摸模拟器桃子移植
- 剧情养成 | 109.5 MB
- 2025.01.16 | 神里绫华触摸模拟器是一...
-

- 3d工口医安卓中文
- 角色扮演 | 15.2 MB
- 2024.01.06 | 手游描述 ...
-

- 校园检查员
- 模拟经营 | 20 MB
- 2024.02.19 | 游戏简介校园检查员是一...
-

- 冷狐隶属洗脑孵化者直装
- 动作冒险 | 303.8 MB
- 2025.02.14 | 冷狐隶属洗脑RPG孵化者安...
-

- 椰羊甘雨触摸产奶过程
- 角色扮演 | 36.2 MB
- 2025.02.14 | 椰羊甘雨触摸产奶过程安...
热门文章
更多 -
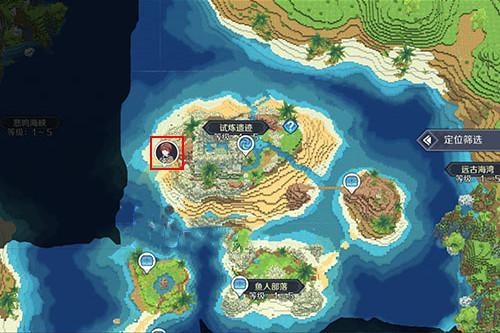
- 神角技巧试炼岛高级宝箱在什么位置
-
2021-11-05 11:52
手游攻略
-

- 王者荣耀音乐扭蛋机活动内容奖励详解
-
2021-11-19 18:38
手游攻略
-
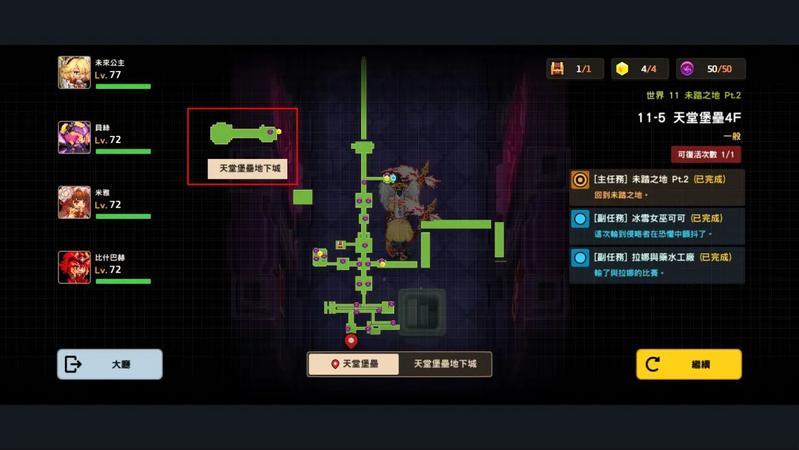
- 坎公骑冠剑11
-
2021-10-31 23:18
手游攻略
-

- 原神卡肉是什么意思
-
2022-06-03 14:46
游戏资讯
-

- 《臭作》之100%全完整攻略
-
2025-06-28 12:37
单机攻略