









基于Paddle复现残差连接网络ResNet
时间:2025-07-29 作者:游乐小编
ResNet有18、34等多种结构,仅残差块数量不同。其通过残差块解决深度神经网络“退化”问题,残差块含残差路径和恒等映射路径,有基础块和瓶颈块等类型。网络用平均池化得特征,卷积后接批归一化,易扩展。文中还给出Paddle复现代码,经训练,其泛化能力和准确率弱于DenseNet,或因层数少。

ResNet网络结构概览
可见有18,34,50,101,152layer种,这五种结构基本类似,只是堆叠的残差块数量不同,这里为了简单起见,采用18 layer作为演示
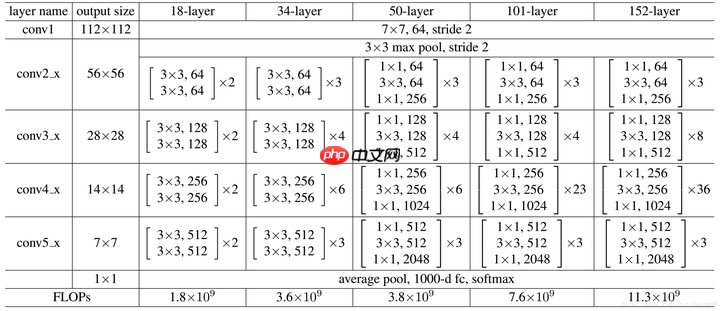
- 通过Average Pooling得到最终的特征,而不是通过全连接层;
- 每个卷积层之后都紧接着BatchNorm layer,为了简化,图中并没有标出;
ResNet结构非常容易修改和扩展,通过调整block内的channel数量以及堆叠的block数量,就可以很容易地调整网络的宽度和深度,来得到不同表达能力的网络,而不用过多地担心网络的“退化”问题,只要训练数据足够,逐步加深网络,就可以获得更好的性能表现。
ResNet网络解决了什么
ResNet可以解决深度神经网络中的“退化”问题!
我们知道,针对浅层网络,其模型性能会随着网络层的堆叠而逐渐变好。因为非线性层增多,特征提取能力越好,即模型拟合数据的能力越好。而模型退化指的是,给网络叠加更多的层后,分类准确率达到饱和,并且性能快速下降。

如上图所示,左右两张图分别表示plain网络(类似VGG构造的深度神经网络)和ResNet网络在ImageNet数据集上的误差。其中横坐标表示迭代次数,纵坐标表示误差,细线表示训练误差,粗线表示验证误差。
按照经验,我们知道模型越深,模型的性能会越好,误差理应越小。但是,如上左图所示,越深的plain网络误差反而越大。在训练集上越深的模型性能反而下降,可以排除过拟合。同时,batchnorm(BN)层的引入也基本解决了plain 网络梯度消失和梯度爆炸的问题。如果不是过拟合和梯度消失导致的,那么什么原因导致模型“退化”呢?
我们假设有一个浅层网络,我们通过堆积新层的方式来建立更深的网络。那么深层网络的解空间应该是包含浅层网络的解空间。如果让那些新增的层不做任何的学习,仅仅简单的复制浅层网络的特征,即新层做恒等映射(identity mapping)。那么,在这种情况下,深层网络应该和浅层网络的性能一样,也不应该出现“退化现象”。更好的解明明存在,为什么找不到?找到的反而是最差的解?
显然,这是个优化问题,反应出结构相似的模型,其优化难度是不一样的,且难度的增长并不是线性的,越深的模型越难以优化。
有两种解决思想。一种是调整求解方法,比如更好的初始化方式,更好的梯度下降算法等;另一种则是调整模型结构,让模型更易于优化。
ResNet的作者从后者入手,探求更好的模型结构。将堆叠的几层layer称之为一个block,对于某个block,其可以拟合的函数为F(x),如果期望的潜在映射为H(x),与其让F(x) 直接学习潜在的映射,不如去学习残差H(x)−x,即F(x):=H(x)−x,这样原本的前向路径上就变成了F(x)+x,用F(x)+x来拟合H(x)。作者认为这样可能更易于优化,因为相比于让F(x)学习潜在映射,让F(x)学习成0要更加容易。这样,对于冗余的block,只需F(x)→0就可以得到恒等映射,性能不减。
为什么残差学习更容易?从直觉上讲,学的东西越少越容易学习。残差学习只需要学习一个近似于0的东西,难度相对小点。从数学上讲,我们假设残差单元表示为:
如下图所示,F(x)+x构成的block称之为Residual Block,即残差块。多个相似的Residual Block串联构成ResNet。
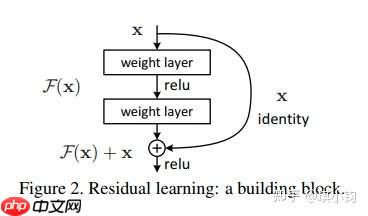
一个残差块有2条路径F(x)和x,F(x)路径拟合残差,不妨称之为残差路径,x路径为identity mapping恒等映射,称之为”shortcut”。图中的⊕为element-wise addition,要求参与运算的F(x)和x的尺寸要相同
不同的残差路径结构
在原论文中,残差路径可以大致分成2种,一种有bottleneck结构,即下图右中的1×1 卷积层,用于先降维再升维,主要出于降低计算复杂度的现实考虑,称之为“bottleneck block”,另一种没有bottleneck结构,如下图左所示,称之为“basic block”。basic block由2个3×3卷积层构成,bottleneck block由两个1×1卷积和1个3x3卷积层构成。
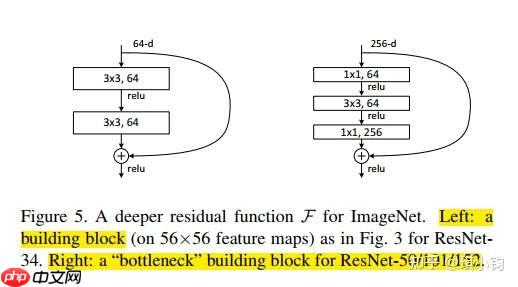
不同的恒等映射路径结构
shortcut路径大致也可以分成2种,取决于残差路径是否改变了feature map数量和尺寸,一种是将输入x原封不动地输出,另一种则需要经过1×1卷积来升维 or/and 降采样,主要作用是将输出与F(x)路径的输出保持shape一致,对网络性能的提升并不明显,两种结构如下图所示,
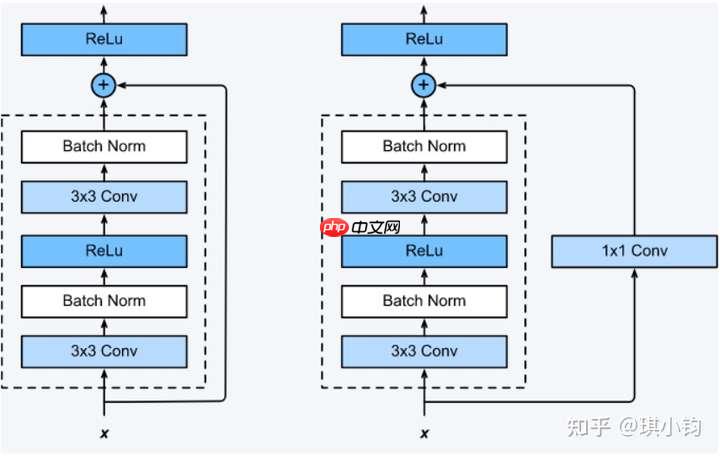
至于Residual Block之间的衔接,在原论文中,F(x)+x经过ReLU后直接作为下一个block的输入x。
Paddle复现代码部分
In [ ]
import timeimport paddleimport paddle.nn as nnimport paddle.nn.functional as F from paddle.vision.transforms import Compose, Resizefrom PIL import Imageimport matplotlib.pyplot as pltfrom collections import OrderedDictimport copyimport numpy as npimport paddle.fluid as fluidfrom paddle.vision import transforms as transformsfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Normalizefrom time import strftimefrom time import gmtime
定义残差块
这个残差块其实包含了这两种结构
In [ ]
#定义残差块class ResidualBlock(nn.Layer): def __init__(self, inchannel, outchannel, stride): super(ResidualBlock, self).__init__() self.left = nn.Sequential( nn.Conv2D(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias_attr=False), nn.BatchNorm2D(outchannel), nn.ReLU(), nn.Conv2D(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias_attr=False), nn.BatchNorm2D(outchannel) ) self.shortcut = nn.Sequential() if stride != 1 or inchannel != outchannel: # 使x的变化一致 使用与F相同的outchannel与stride self.shortcut = nn.Sequential( nn.Conv2D(inchannel, outchannel, kernel_size=1, stride=stride, bias_attr=False), nn.BatchNorm2D(outchannel) ) def forward(self, x): out = self.left(x) # 这里是直接加上去了,DenseNet是累起来的,相当于扩充了通道数 out += self.shortcut(x) out = F.relu(out) return out
ResNet网络
In [ ]
#resnet主体class ResNet(nn.Layer): def __init__(self, ResidualBlock, num_classes=10): super(ResNet, self).__init__() self.inchannel = 64 self.conv1 = nn.Sequential( nn.Conv2D(3, 64, kernel_size=3, stride=1, padding=1, bias_attr=False), nn.BatchNorm2D(64), nn.ReLU(), ) # 把函数传了进去 self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1) self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2) self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2) self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2) self.fc = nn.Linear(512, num_classes) def make_layer(self, block, channels, num_blocks, stride): # 堆叠的层数与num_blocks有关 strides = [stride] + [1] * (num_blocks - 1) layers = [] for stride in strides: layers.append(block(self.inchannel, channels, stride)) # 储存上次输出的通道数,以便一次输入回去 self.inchannel = channels return nn.Sequential(*layers) # 假设输入3*32*32 这样训练的快点哈哈 # 如果不用32*32,可以在开头几个conv中缩小尺寸 def forward(self, x): # 3*32*32 out = self.conv1(x) # 64*32*32 out = self.layer1(out) # 64*32*32 out = self.layer2(out) # 128*16*16 out = self.layer3(out) # 256*8*8 out = self.layer4(out) # 512*4*4 out = F.avg_pool2d(out,4) # 512*1*1 out = paddle.reshape(out,[out.shape[0], -1]) # x 1*1*512=512 out = self.fc(out) return out#定义resnet18def ResNet18(): return ResNet(ResidualBlock)
数据加载与增强
这里为了加快训练,略微修改了原论文中的模型结构,取消了部分卷积层,因为原论文是224*224输入的,这里的输入仅为32*32
In [ ]
transform_train = Compose([ transforms.RandomHorizontalFlip(prob=0.5), transforms.RandomVerticalFlip(prob=0.5), transforms.ColorJitter(brightness=0.5), transforms.ColorJitter(contrast=0.5), transforms.ColorJitter(saturation=0.5), transforms.ColorJitter(hue=0.3), transforms.Resize([32, 32]), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),])transform_test = Compose([ transforms.Resize([32, 32]), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),])LR = 0.001EPOCHES = 100BATCHSIZE = 150trainset=Cifar10(data_file=None, mode='train', transform=transform_train, download=True)testset=Cifar10(data_file=None, mode='test', transform=transform_test, download=True)trainloader = paddle.io.DataLoader(trainset, batch_size=BATCHSIZE, shuffle=True, num_workers=2)testloader = paddle.io.DataLoader(testset, batch_size=BATCHSIZE, shuffle=False, num_workers=2)
优化器与损失函数
In [ ]
resnet18 = ResNet18()optimizer = paddle.optimizer.Adam(learning_rate=LR,parameters=resnet18.parameters())loss_function = nn.CrossEntropyLoss()
训练过程
训练了20个epoch
这里加了个计时的功能,感觉不错,精确摸鱼时间
In [1]
for ep in range(EPOCHES): train_correct = 0 train_sum=0 epoch_used_time=0 epoch_ave_time=0 time_start=time.time() for i,(img, label) in enumerate(trainloader): optimizer.clear_grad() resnet18.train() out = resnet18(img) prediction = paddle.argmax(out, 1) pre_num = prediction.cpu().numpy() train_correct += (pre_num == label.cpu().numpy()).sum() train_sum+=BATCHSIZE loss = loss_function(out, label) loss.backward() optimizer.step() epoch_used_time+=(time.time()-time_start) time_start=time.time() # 加了个比较简陋的计时方式,显示训练剩余时间,以便估计摸鱼时间 used_t=strftime("%H:%M:%S", gmtime(epoch_used_time)) total_t=strftime("%H:%M:%S", gmtime((epoch_used_time/(i+1))*len(trainloader))) print(f"
Epoch:{str(ep)} Iter {train_sum}/{len(trainloader)*BATCHSIZE} Train ACC: {(train_correct/train_sum):.5} Used_Time:{used_t} / Total_Time:{total_t}",end="") print('') vote_correct = 0 test_sum=0 for img, label in testloader: resnet18.eval() out = resnet18(img) prediction = paddle.argmax(out, 1) pre_num = prediction.cpu().numpy() vote_correct += (pre_num == label.cpu().numpy()).sum() test_sum+=BATCHSIZE print(f"
Epoch:{str(ep)} Iter {test_sum}/{len(testloader)*BATCHSIZE} Test ACC: {(vote_correct/test_sum):.5}",end="") print('')训练结果展示
经过与DenseNet对比,发现其泛化能力与准确率确实弱于DenseNet
不过这可能是网络层数较少的缘故
DenseNet部分
https://aistudio.baidu.com/aistudio/projectdetail/3618847?shared=1
Epoch:1 Iter 50100/50100 Train ACC: 0.67275 Used_Time:00:00:37 / Total_Time:00:00:37
Epoch:1 Iter 10050/10050 Test ACC: 0.68965
Epoch:3 Iter 50100/50100 Train ACC: 0.75012 Used_Time:00:00:39 / Total_Time:00:00:39
Epoch:3 Iter 10050/10050 Test ACC: 0.73731
Epoch:19 Iter 50100/50100 Train ACC: 0.9289 Used_Time:00:00:38 / Total_Time:00:00:388
Epoch:19 Iter 10050/10050 Test ACC: 0.8415
Epoch:20 Iter 50100/50100 Train ACC: 0.93236 Used_Time:00:00:39 / Total_Time:00:00:39
Epoch:20 Iter 10050/10050 Test ACC: 0.83751
小编推荐:
热门推荐
更多 -

- 与八尺大人的夏天回忆汉化冷狐
- 剧情养成 | 6.1 MB
- 2025.01.16 | 和八尺大人的夏天回顾汉...
-

- 夏哈塔
- 休闲益智 | 121.65 MB
- 2024.08.16 | 游戏简介夏哈塔手游,带...
-

- 卡在墙上的女孩2
- 休闲益智 | 21 MB
- 2024.06.01 | 游戏简介卡在墙上的女孩2...
-

- 地下教育录冷狐
- 剧情养成 | 551.3 MB
- 2025.01.16 | re地下教ru育录是一款富...
-

- 3D工口医存档
- 角色扮演 | 15.2 MB
- 2024.01.06 | 手游描述 ...
-

- 触摸深睡巴比伦游戏汉化
- 剧情养成 | 244.4 MB
- 2025.01.16 | 触摸深睡巴比伦手游汉化...
-

- beastbeat2.5.1
- 休闲益智 | 121.65 MB
- 2024.07.19 | 游戏简介beastbeat2 5 ...
-

- 流氓先生
- 飞行射击 | 14.65 MB
- 2024.08.31 | 流氓先生是一款非常好玩...
-

- 3d工口医全解锁
- 角色扮演 | 15.2 MB
- 2024.01.06 | 手游描述 ...
-

- 流氓牛仔Vs外星人
- 动作冒险 | 132.47 MB
- 2024.11.30 | 手游描述 ...
-

- 神里绫华触摸模拟器桃子移植
- 剧情养成 | 109.5 MB
- 2025.01.16 | 神里绫华触摸模拟器是一...
-

- 3d工口医安卓中文
- 角色扮演 | 15.2 MB
- 2024.01.06 | 手游描述 ...
-

- 校园检查员
- 模拟经营 | 20 MB
- 2024.02.19 | 游戏简介校园检查员是一...
-

- 冷狐隶属洗脑孵化者直装
- 动作冒险 | 303.8 MB
- 2025.02.14 | 冷狐隶属洗脑RPG孵化者安...
-

- 椰羊甘雨触摸产奶过程
- 角色扮演 | 36.2 MB
- 2025.02.14 | 椰羊甘雨触摸产奶过程安...
热门文章
更多 -
- 神角技巧试炼岛高级宝箱在什么位置
-
2021-11-05 11:52
手游攻略
-

- 王者荣耀音乐扭蛋机活动内容奖励详解
-
2021-11-19 18:38
手游攻略
-
- 坎公骑冠剑11
-
2021-10-31 23:18
手游攻略
-

- 原神卡肉是什么意思
-
2022-06-03 14:46
游戏资讯
-

- 《臭作》之100%全完整攻略
-
2025-06-28 12:37
单机攻略