利用情感分析选择年夜饭
本文围绕自然语言处理中的情感分析展开,先介绍NLP基本开发流程和原理,说明文本分类通用步骤及词向量表示原因。接着讲解词向量到句子向量的方法、相关神经网络,最后以年夜饭评论为例,用PaddlePaddle和PaddleNLP构建LSTM模型完成情感分析,包括数据处理、模型搭建、训练及预测等过程。

自然语言处理——情感分析
目标任务
本项目将会先分解说明nlp的基本开发流程和原理,然后通过 构建LSTM算法来完成情感分析
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
基本概念
把需要的文本先转换成词向量然后通过模型构建不断学习促使机器学会有关内容
主要的分类场景有:分词、词性标注、地名、机构名、快递单信息抽签、搜索、视频文章推荐、智能客服、对话、低质量文章识别……
什么是情感分析
通过一个自然语句的输入分析,这一句话的情感,可以分为正向、负向、中性
文本分类通用步骤
输入:一个自然语言的句子
通过:分词阶段
生成:词向量
接入:一个任务网络(分类器)
计算机处理的二进制的数据,只有用向量(张量)表示才能够跟好的处理
原理介绍
第一步:输入一个自然语言
第二步:切词(或者切字)
第三步:转换成ID(根据词语在词汇表的位置也就是id)
第四步:生成数组(在id位置是1其他位置是0)
注:按照图中的情况进行假设词汇表的长度是5w,那么3个词生成的数组就是(3,5w)
第五步:上面的数组乘以数组(数组的维度是词汇表长度*5的矩阵)
第六步:生成一个新的矩阵(句子长度 * 词向量的长度)
以图为例子: 3个词每一个词用5维的向量表示
第六步:批量处理
如下图:128个数据进行统一的处理就生成了一个3 * 5* 128的三维Tensor,Tensor的大小就是(128, 5, 3)[在里面句子的长度要相等长的要截断,短的要补齐]
第七步:通过黑盒得到一个句子向量(句子的长度这个维度被抹除了)
词向量到句子向量
加权平均法:
把单个的词向量加起来就是句子向量
序列建模法:
针对加权法的缺点改进的建模方法
预训练模型法
循环神经网络RNN
RNN的关键点:词向量从左往右逐词处理,不断的挑整网络。
每个时刻调用的是同一个网络
循环神经网络—长短时记忆网络LSTM
里面也是依次逐词处理的网络
里面涉及了历史记忆和历史的遗忘值,有就计算,没有就不管
全连接层、线性分类分类器
全连接层顾名思义:输入层和隐藏层逐个连接
实践
快来选一顿好吃的年夜饭:看看如何自定义数据集,实现文本分类中的情感分析任务
情感分析是自然语言处理领域一个老生常谈的任务。句子情感分析目的是为了判别说者的情感倾向,比如在某些话题上给出的的态度明确的观点,或者反映的情绪状态等。情感分析有着广泛应用,比如电商评论分析、舆情分析等。

环境介绍
PaddlePaddle框架,AI Studio平台已经默认安装最新版2.0。
PaddleNLP,深度兼容框架2.0,是飞桨框架2.0在NLP领域的最佳实践。
这里使用的是beta版本,马上也会发布rc版哦。AI Studio平台后续会默认安装PaddleNLP,在此之前可使用如下命令安装。
In [1]# 下载paddlenlp!pip install --upgrade paddlenlp==2.0.0b4 -i https://pypi.org/simple登录后复制
查看安装的版本
In [2]import paddleimport paddlenlpprint(paddle.__version__, paddlenlp.__version__)登录后复制
2.0.1 2.0.0b4登录后复制
PaddleNLP和Paddle框架是什么关系?

Paddle框架是基础底座,提供深度学习任务全流程API。PaddleNLP基于Paddle框架开发,适用于NLP任务。
PaddleNLP中数据处理、数据集、组网单元等API未来会沉淀到框架paddle.text中。
代码中继承 class TSVDataset(paddle.io.Dataset)使用飞桨完成深度学习任务的通用流程
数据集和数据处理
paddle.io.Dataset
paddle.io.DataLoader
paddlenlp.data
组网和网络配置
paddle.nn.Embedding
paddlenlp.seq2vec paddle.nn.Linear
paddle.tanh
paddle.nn.CrossEntropyLoss paddle.metric.Accuracy paddle.optimizer
model.prepare
网络训练和评估
model.fit
model.evaluate
预测 model.predict
In [3]import numpy as npfrom functools import partialimport paddle.nn as nnimport paddle.nn.functional as Fimport paddlenlp as ppnlpfrom paddlenlp.data import Pad, Stack, Tuplefrom paddlenlp.datasets import MapDatasetWrapperfrom utils import load_vocab, convert_example登录后复制
数据集和数据处理
自定义数据集
映射式(map-style)数据集需要继承paddle.io.Dataset
__getitem__: 根据给定索引获取数据集中指定样本,在 paddle.io.DataLoader 中需要使用此函数通过下标获取样本。
__len__: 返回数据集样本个数, paddle.io.BatchSampler 中需要样本个数生成下标序列。
验证集:验证模型在训练过程中的表现,通过负反馈调整模型
测试集:看模型最后的表现。
个人理解:训练集:上课;验证集:周考,月考;测试集:期末考
通过SelfDefinedDataset.get_datasets对数据集进行处理得到paddle.io.Dataset类型的结果
class SelfDefinedDataset(paddle.io.Dataset): # 继承paddle.io.Dataset生成数据集 def __init__(self, data): super(SelfDefinedDataset, self).__init__() self.data = data def __getitem__(self, idx): return self.data[idx] def __len__(self): return len(self.data) def get_labels(self): return ["0", "1"]def txt_to_list(file_name): res_list = [] for line in open(file_name): res_list.append(line.strip().split('\t')) return res_listtrainlst = txt_to_list('train.txt')devlst = txt_to_list('dev.txt')testlst = txt_to_list('test.txt')train_ds, dev_ds, test_ds = SelfDefinedDataset.get_datasets([trainlst, devlst, testlst])登录后复制 In [5]# 查看数据长什么样label_list = train_ds.get_labels()print(label_list)for i in range(10): print (train_ds[i])登录后复制
['0', '1']['赢在心理,输在出品!杨枝太酸,三文鱼熟了,酥皮焗杏汁杂果可以换个名(九唔搭八)', '0']['服务一般,客人多,服务员少,但食品很不错', '1']['東坡肉竟然有好多毛,問佢地點解,佢地仲話係咁架\ue107\ue107\ue107\ue107\ue107\ue107\ue107冇天理,第一次食東坡肉有毛,波羅包就幾好食', '0']['父亲节去的,人很多,口味还可以上菜快!但是结账的时候,算错了没有打折,我也忘记拿清单了。说好打8折的,收银员没有打,人太多一时自己也没有想起。不知道收银员忘记,还是故意那钱露入自己qian包。。', '0']['吃野味,吃个新鲜,你当然一定要来广州吃鹿肉啦*价格便宜,量好足,', '1']['味道几好服务都五错推荐鹅肝乳鸽飞鱼', '1']['作为老字号,水准保持算是不错,龟岗分店可能是位置问题,人不算多,基本不用等位,自从抢了券,去过好几次了,每次都可以打85以上的评分,算是可以了~粉丝煲每次必点,哈哈,鱼也不错,还会来帮衬的,楼下还可以免费停车!', '1']['边到正宗啊?味味都咸死人啦,粤菜讲求鲜甜,五知点解感多人话好吃。', '0']['环境卫生差,出品垃圾,冇下次,不知所为', '0']['和苑真是精致粤菜第一家,服务菜品都一流', '1']登录后复制
数据处理
为了将原始数据处理成模型可以读入的格式,本项目将对数据作以下处理:
首先使用jieba切词,之后将jieba切完后的单词映射词表中单词id。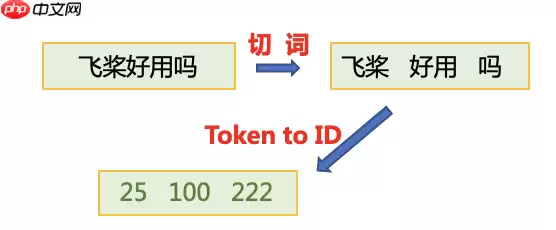
其中用到了PaddleNLP中关于数据处理的API。PaddleNLP提供了许多关于NLP任务中构建有效的数据pipeline的常用API
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
In [6]# 下载词汇表文件word_dict.txt,用于构造词-id映射关系。# !wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt# 加载词表vocab = load_vocab('./senta_word_dict.txt')for k, v in vocab.items(): print(k, v) break登录后复制 [PAD] 0登录后复制
构造dataloder
下面的create_data_loader函数用于创建运行和预测时所需要的DataLoader对象。
paddle.io.DataLoader返回一个迭代器,该迭代器根据batch_sampler指定的顺序迭代返回dataset数据。异步加载数据。
batch_sampler:DataLoader通过 batch_sampler 产生的mini-batch索引列表来 dataset 中索引样本并组成mini-batch
collate_fn:指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是prepare_input函数,对产生的数据进行pad操作,并返回实际长度等。
In [7]# Reads data and generates mini-batches.def create_dataloader(dataset, trans_function=None, mode='train', batch_size=1, pad_token_id=0, batchify_fn=None): if trans_function: dataset = dataset.apply(trans_function, lazy=True) # return_list 数据是否以list形式返回 # collate_fn 指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是`prepare_input`函数,对产生的数据进行pad操作,并返回实际长度等。 dataloader = paddle.io.DataLoader( dataset, return_list=True, batch_size=batch_size, collate_fn=batchify_fn) return dataloader# python中的偏函数partial,把一个函数的某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。trans_function = partial( convert_example, vocab=vocab, unk_token_id=vocab.get('[UNK]', 1), is_test=False)# 将读入的数据batch化处理,便于模型batch化运算。# batch中的每个句子将会padding到这个batch中的文本最大长度batch_max_seq_len。# 当文本长度大于batch_max_seq时,将会截断到batch_max_seq_len;当文本长度小于batch_max_seq时,将会padding补齐到batch_max_seq_len.batchify_fn = lambda samples, fn=Tuple( Pad(axis=0, pad_val=vocab['[PAD]']), # input_ids Stack(dtype="int64"), # seq len Stack(dtype="int64") # label): [data for data in fn(samples)]train_loader = create_dataloader( train_ds, trans_function=trans_function, batch_size=128, mode='train', batchify_fn=batchify_fn)dev_loader = create_dataloader( dev_ds, trans_function=trans_function, batch_size=128, mode='validation', batchify_fn=batchify_fn)test_loader = create_dataloader( test_ds, trans_function=trans_function, batch_size=128, mode='test', batchify_fn=batchify_fn)登录后复制 模型搭建
使用LSTMencoder搭建一个BiLSTM模型用于进行句子建模,得到句子的向量表示。
然后接一个线性变换层,完成二分类任务。
paddle.nn.Embedding组建word-embedding层ppnlp.seq2vec.LSTMEncoder组建句子建模层paddle.nn.Linear构造二分类器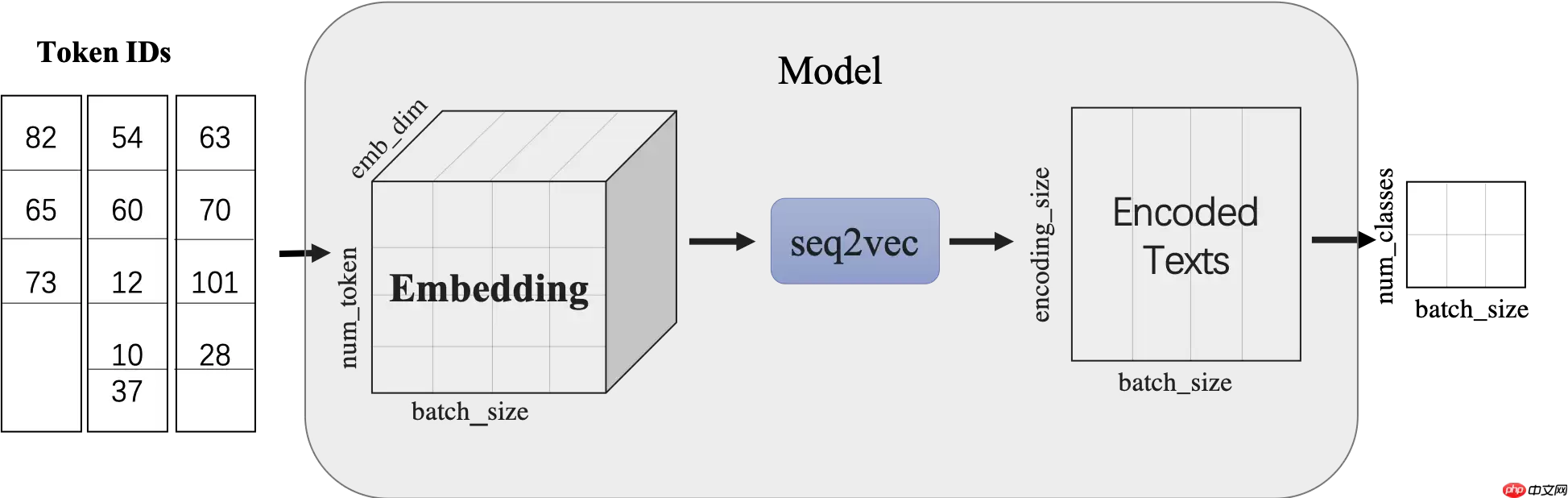
除LSTM外,seq2vec还提供了许多语义表征方法,详细可参考:seq2vec介绍In [8]
class LSTMModel(nn.Layer): def __init__(self, vocab_size, num_classes, emb_dim=128, padding_idx=0, lstm_hidden_size=198, direction='forward', lstm_layers=1, dropout_rate=0, pooling_type=None, fc_hidden_size=96): super().__init__() # 首先将输入word id 查表后映射成 word embedding self.embedder = nn.Embedding( num_embeddings=vocab_size, embedding_dim=emb_dim, padding_idx=padding_idx) # 将word embedding经过LSTMEncoder变换到文本语义表征空间中 self.lstm_encoder = ppnlp.seq2vec.RNNEncoder( emb_dim, lstm_hidden_size, num_layers=lstm_layers, direction=direction, dropout=dropout_rate, pooling_type=pooling_type) # LSTMEncoder.get_output_dim()方法可以获取经过encoder之后的文本表示hidden_size self.fc = nn.Linear(self.lstm_encoder.get_output_dim(), fc_hidden_size) # 最后的分类器 self.output_layer = nn.Linear(fc_hidden_size, num_classes) def forward(self, text, seq_len): # text shape: (batch_size, num_tokens) # print('input :', text.shape) # Shape: (batch_size, num_tokens, embedding_dim) embedded_text = self.embedder(text) # print('after word-embeding:', embedded_text.shape) # Shape: (batch_size, num_tokens, num_directions*lstm_hidden_size) # num_directions = 2 if direction is 'bidirectional' else 1 text_repr = self.lstm_encoder(embedded_text, sequence_length=seq_len) # print('after lstm:', text_repr.shape) # Shape: (batch_size, fc_hidden_size) fc_out = paddle.tanh(self.fc(text_repr)) # print('after Linear classifier:', fc_out.shape) # Shape: (batch_size, num_classes) logits = self.output_layer(fc_out) # print('output:', logits.shape) # probs 分类概率值 probs = F.softmax(logits, axis=-1) # print('output probability:', probs.shape) return probsmodel= LSTMModel( len(vocab), len(label_list), direction='bidirectional', padding_idx=vocab['[PAD]'])model = paddle.Model(model)登录后复制 模型配置和训练
模型配置
In [9]optimizer = paddle.optimizer.Adam( parameters=model.parameters(), learning_rate=5e-5)loss = paddle.nn.CrossEntropyLoss()metric = paddle.metric.Accuracy()model.prepare(optimizer, loss, metric)登录后复制 In [10]
# 设置visualdl路径log_dir = './visualdl'callback = paddle.callbacks.VisualDL(log_dir=log_dir)登录后复制
模型训练
训练过程中会输出loss、acc等信息。这里设置了10个epoch,在训练集上准确率约97%。

model.fit(train_loader, dev_loader, epochs=10, save_dir='./checkpoints', save_freq=5, callbacks=callback)登录后复制
The loss value printed in the log is the current step, and the metric is the average value of previous step.Epoch 1/10登录后复制
Building prefix dict from the default dictionary ...登录后复制
2024-03-21 13:02:03,274 - DEBUG - Building prefix dict from the default dictionary ...Dumping model to file cache /tmp/jieba.cache2024-03-21 13:02:04,016 - DEBUG - Dumping model to file cache /tmp/jieba.cacheLoading model cost 0.798 seconds.2024-03-21 13:02:04,073 - DEBUG - Loading model cost 0.798 seconds.Prefix dict has been built successfully.2024-03-21 13:02:04,075 - DEBUG - Prefix dict has been built successfully./opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and登录后复制
step 10/125 - loss: 0.7010 - acc: 0.4813 - 216ms/stepstep 20/125 - loss: 0.6931 - acc: 0.5043 - 151ms/stepstep 30/125 - loss: 0.6910 - acc: 0.5154 - 129ms/stepstep 40/125 - loss: 0.6890 - acc: 0.5174 - 117ms/stepstep 50/125 - loss: 0.6860 - acc: 0.5197 - 110ms/stepstep 60/125 - loss: 0.6942 - acc: 0.5180 - 105ms/stepstep 70/125 - loss: 0.6905 - acc: 0.5180 - 102ms/stepstep 80/125 - loss: 0.6869 - acc: 0.5222 - 100ms/stepstep 90/125 - loss: 0.6870 - acc: 0.5398 - 98ms/stepstep 100/125 - loss: 0.6823 - acc: 0.5445 - 97ms/stepstep 110/125 - loss: 0.6776 - acc: 0.5452 - 96ms/stepstep 120/125 - loss: 0.6747 - acc: 0.5577 - 95ms/stepstep 125/125 - loss: 0.6774 - acc: 0.5620 - 93ms/stepsave checkpoint at /home/aistudio/checkpoints/0Eval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.6720 - acc: 0.6695 - 84ms/stepstep 20/84 - loss: 0.6739 - acc: 0.6648 - 69ms/stepstep 30/84 - loss: 0.6749 - acc: 0.6620 - 65ms/stepstep 40/84 - loss: 0.6735 - acc: 0.6637 - 62ms/stepstep 50/84 - loss: 0.6778 - acc: 0.6620 - 61ms/stepstep 60/84 - loss: 0.6721 - acc: 0.6638 - 61ms/stepstep 70/84 - loss: 0.6746 - acc: 0.6664 - 60ms/stepstep 80/84 - loss: 0.6749 - acc: 0.6652 - 59ms/stepstep 84/84 - loss: 0.6649 - acc: 0.6647 - 57ms/stepEval samples: 10646Epoch 2/10step 10/125 - loss: 0.6739 - acc: 0.6898 - 113ms/stepstep 20/125 - loss: 0.6524 - acc: 0.7191 - 100ms/stepstep 30/125 - loss: 0.6025 - acc: 0.7500 - 95ms/stepstep 40/125 - loss: 0.5736 - acc: 0.7623 - 92ms/stepstep 50/125 - loss: 0.4809 - acc: 0.7683 - 91ms/stepstep 60/125 - loss: 0.4591 - acc: 0.7763 - 90ms/stepstep 70/125 - loss: 0.4734 - acc: 0.7831 - 91ms/stepstep 80/125 - loss: 0.4487 - acc: 0.7861 - 92ms/stepstep 90/125 - loss: 0.5213 - acc: 0.7900 - 94ms/stepstep 100/125 - loss: 0.5303 - acc: 0.7891 - 96ms/stepstep 110/125 - loss: 0.4789 - acc: 0.7930 - 99ms/stepstep 120/125 - loss: 0.4611 - acc: 0.7969 - 101ms/stepstep 125/125 - loss: 0.4887 - acc: 0.7984 - 99ms/stepEval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.5155 - acc: 0.8523 - 96ms/stepstep 20/84 - loss: 0.4754 - acc: 0.8484 - 80ms/stepstep 30/84 - loss: 0.5009 - acc: 0.8469 - 76ms/stepstep 40/84 - loss: 0.4709 - acc: 0.8500 - 73ms/stepstep 50/84 - loss: 0.4760 - acc: 0.8497 - 71ms/stepstep 60/84 - loss: 0.4576 - acc: 0.8479 - 70ms/stepstep 70/84 - loss: 0.4642 - acc: 0.8493 - 69ms/stepstep 80/84 - loss: 0.4890 - acc: 0.8485 - 68ms/stepstep 84/84 - loss: 0.4549 - acc: 0.8494 - 66ms/stepEval samples: 10646Epoch 3/10step 10/125 - loss: 0.5171 - acc: 0.8313 - 123ms/stepstep 20/125 - loss: 0.4559 - acc: 0.8297 - 112ms/stepstep 30/125 - loss: 0.4608 - acc: 0.8344 - 108ms/stepstep 40/125 - loss: 0.4628 - acc: 0.8424 - 105ms/stepstep 50/125 - loss: 0.4640 - acc: 0.8470 - 105ms/stepstep 60/125 - loss: 0.3650 - acc: 0.8522 - 103ms/stepstep 70/125 - loss: 0.4364 - acc: 0.8560 - 103ms/stepstep 80/125 - loss: 0.4144 - acc: 0.8560 - 103ms/stepstep 90/125 - loss: 0.4244 - acc: 0.8583 - 103ms/stepstep 100/125 - loss: 0.4586 - acc: 0.8584 - 103ms/stepstep 110/125 - loss: 0.4421 - acc: 0.8598 - 104ms/stepstep 120/125 - loss: 0.4119 - acc: 0.8621 - 104ms/stepstep 125/125 - loss: 0.3894 - acc: 0.8623 - 102ms/stepEval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.4168 - acc: 0.8977 - 96ms/stepstep 20/84 - loss: 0.4086 - acc: 0.9012 - 78ms/stepstep 30/84 - loss: 0.4200 - acc: 0.9000 - 72ms/stepstep 40/84 - loss: 0.3959 - acc: 0.9014 - 70ms/stepstep 50/84 - loss: 0.4019 - acc: 0.9022 - 69ms/stepstep 60/84 - loss: 0.4229 - acc: 0.9014 - 68ms/stepstep 70/84 - loss: 0.4447 - acc: 0.9001 - 67ms/stepstep 80/84 - loss: 0.4186 - acc: 0.9011 - 66ms/stepstep 84/84 - loss: 0.4398 - acc: 0.9015 - 64ms/stepEval samples: 10646Epoch 4/10step 10/125 - loss: 0.4333 - acc: 0.8930 - 131ms/stepstep 20/125 - loss: 0.4103 - acc: 0.8926 - 113ms/stepstep 30/125 - loss: 0.3948 - acc: 0.9000 - 109ms/stepstep 40/125 - loss: 0.4312 - acc: 0.9045 - 107ms/stepstep 50/125 - loss: 0.4069 - acc: 0.9020 - 106ms/stepstep 60/125 - loss: 0.4027 - acc: 0.9049 - 104ms/stepstep 70/125 - loss: 0.4955 - acc: 0.9011 - 104ms/stepstep 80/125 - loss: 0.3805 - acc: 0.8979 - 103ms/stepstep 90/125 - loss: 0.3931 - acc: 0.8979 - 104ms/stepstep 100/125 - loss: 0.3674 - acc: 0.8988 - 104ms/stepstep 110/125 - loss: 0.3908 - acc: 0.8998 - 104ms/stepstep 120/125 - loss: 0.3746 - acc: 0.9027 - 104ms/stepstep 125/125 - loss: 0.3734 - acc: 0.9037 - 102ms/stepEval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.3905 - acc: 0.9266 - 97ms/stepstep 20/84 - loss: 0.3848 - acc: 0.9320 - 82ms/stepstep 30/84 - loss: 0.3714 - acc: 0.9336 - 76ms/stepstep 40/84 - loss: 0.3695 - acc: 0.9361 - 77ms/stepstep 50/84 - loss: 0.3676 - acc: 0.9372 - 75ms/stepstep 60/84 - loss: 0.3807 - acc: 0.9380 - 74ms/stepstep 70/84 - loss: 0.3835 - acc: 0.9377 - 73ms/stepstep 80/84 - loss: 0.3630 - acc: 0.9379 - 73ms/stepstep 84/84 - loss: 0.4244 - acc: 0.9383 - 70ms/stepEval samples: 10646Epoch 5/10step 10/125 - loss: 0.4770 - acc: 0.9094 - 124ms/stepstep 20/125 - loss: 0.3861 - acc: 0.9227 - 112ms/stepstep 30/125 - loss: 0.3744 - acc: 0.9318 - 106ms/stepstep 40/125 - loss: 0.3799 - acc: 0.9361 - 104ms/stepstep 50/125 - loss: 0.3660 - acc: 0.9391 - 103ms/stepstep 60/125 - loss: 0.3525 - acc: 0.9428 - 101ms/stepstep 70/125 - loss: 0.3703 - acc: 0.9446 - 100ms/stepstep 80/125 - loss: 0.3534 - acc: 0.9438 - 100ms/stepstep 90/125 - loss: 0.3415 - acc: 0.9451 - 100ms/stepstep 100/125 - loss: 0.3525 - acc: 0.9451 - 100ms/stepstep 110/125 - loss: 0.3530 - acc: 0.9462 - 100ms/stepstep 120/125 - loss: 0.3838 - acc: 0.9477 - 99ms/stepstep 125/125 - loss: 0.3552 - acc: 0.9478 - 97ms/stepEval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.3792 - acc: 0.9492 - 99ms/stepstep 20/84 - loss: 0.3733 - acc: 0.9488 - 80ms/stepstep 30/84 - loss: 0.3702 - acc: 0.9500 - 74ms/stepstep 40/84 - loss: 0.3499 - acc: 0.9525 - 71ms/stepstep 50/84 - loss: 0.3756 - acc: 0.9519 - 70ms/stepstep 60/84 - loss: 0.3550 - acc: 0.9522 - 69ms/stepstep 70/84 - loss: 0.3693 - acc: 0.9521 - 67ms/stepstep 80/84 - loss: 0.3517 - acc: 0.9520 - 66ms/stepstep 84/84 - loss: 0.4341 - acc: 0.9524 - 63ms/stepEval samples: 10646Epoch 6/10step 10/125 - loss: 0.3712 - acc: 0.9469 - 128ms/stepstep 20/125 - loss: 0.3570 - acc: 0.9543 - 115ms/stepstep 30/125 - loss: 0.3519 - acc: 0.9576 - 108ms/stepstep 40/125 - loss: 0.3670 - acc: 0.9576 - 104ms/stepstep 50/125 - loss: 0.3500 - acc: 0.9587 - 103ms/stepstep 60/125 - loss: 0.3303 - acc: 0.9605 - 103ms/stepstep 70/125 - loss: 0.3565 - acc: 0.9610 - 102ms/stepstep 80/125 - loss: 0.3389 - acc: 0.9604 - 102ms/stepstep 90/125 - loss: 0.3361 - acc: 0.9602 - 102ms/stepstep 100/125 - loss: 0.3479 - acc: 0.9597 - 101ms/stepstep 110/125 - loss: 0.3415 - acc: 0.9599 - 101ms/stepstep 120/125 - loss: 0.3643 - acc: 0.9613 - 101ms/stepstep 125/125 - loss: 0.3519 - acc: 0.9610 - 99ms/stepsave checkpoint at /home/aistudio/checkpoints/5Eval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.3761 - acc: 0.9484 - 101ms/stepstep 20/84 - loss: 0.3602 - acc: 0.9520 - 83ms/stepstep 30/84 - loss: 0.3653 - acc: 0.9526 - 78ms/stepstep 40/84 - loss: 0.3450 - acc: 0.9549 - 75ms/stepstep 50/84 - loss: 0.3758 - acc: 0.9553 - 75ms/stepstep 60/84 - loss: 0.3358 - acc: 0.9564 - 74ms/stepstep 70/84 - loss: 0.3652 - acc: 0.9557 - 72ms/stepstep 80/84 - loss: 0.3458 - acc: 0.9563 - 70ms/stepstep 84/84 - loss: 0.3526 - acc: 0.9570 - 67ms/stepEval samples: 10646Epoch 7/10step 10/125 - loss: 0.3576 - acc: 0.9531 - 129ms/stepstep 20/125 - loss: 0.3430 - acc: 0.9641 - 116ms/stepstep 30/125 - loss: 0.3442 - acc: 0.9661 - 110ms/stepstep 40/125 - loss: 0.3624 - acc: 0.9648 - 106ms/stepstep 50/125 - loss: 0.3434 - acc: 0.9659 - 105ms/stepstep 60/125 - loss: 0.3276 - acc: 0.9684 - 103ms/stepstep 70/125 - loss: 0.3427 - acc: 0.9692 - 102ms/stepstep 80/125 - loss: 0.3296 - acc: 0.9683 - 101ms/stepstep 90/125 - loss: 0.3288 - acc: 0.9681 - 101ms/stepstep 100/125 - loss: 0.3370 - acc: 0.9675 - 101ms/stepstep 110/125 - loss: 0.3326 - acc: 0.9679 - 101ms/stepstep 120/125 - loss: 0.3567 - acc: 0.9689 - 101ms/stepstep 125/125 - loss: 0.3450 - acc: 0.9682 - 99ms/stepEval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.3743 - acc: 0.9547 - 101ms/stepstep 20/84 - loss: 0.3683 - acc: 0.9547 - 83ms/stepstep 30/84 - loss: 0.3621 - acc: 0.9552 - 77ms/stepstep 40/84 - loss: 0.3402 - acc: 0.9568 - 73ms/stepstep 50/84 - loss: 0.3642 - acc: 0.9572 - 71ms/stepstep 60/84 - loss: 0.3561 - acc: 0.9576 - 70ms/stepstep 70/84 - loss: 0.3590 - acc: 0.9569 - 68ms/stepstep 80/84 - loss: 0.3467 - acc: 0.9563 - 67ms/stepstep 84/84 - loss: 0.4090 - acc: 0.9570 - 64ms/stepEval samples: 10646Epoch 8/10step 10/125 - loss: 0.3474 - acc: 0.9578 - 118ms/stepstep 20/125 - loss: 0.3465 - acc: 0.9641 - 104ms/stepstep 30/125 - loss: 0.3451 - acc: 0.9667 - 102ms/stepstep 40/125 - loss: 0.3570 - acc: 0.9658 - 100ms/stepstep 50/125 - loss: 0.3404 - acc: 0.9680 - 100ms/stepstep 60/125 - loss: 0.3243 - acc: 0.9698 - 99ms/stepstep 70/125 - loss: 0.3353 - acc: 0.9709 - 98ms/stepstep 80/125 - loss: 0.3346 - acc: 0.9704 - 98ms/stepstep 90/125 - loss: 0.3228 - acc: 0.9703 - 98ms/stepstep 100/125 - loss: 0.3342 - acc: 0.9701 - 98ms/stepstep 110/125 - loss: 0.3223 - acc: 0.9710 - 98ms/stepstep 120/125 - loss: 0.3479 - acc: 0.9721 - 98ms/stepstep 125/125 - loss: 0.3624 - acc: 0.9718 - 97ms/stepEval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.3666 - acc: 0.9523 - 104ms/stepstep 20/84 - loss: 0.3573 - acc: 0.9563 - 87ms/stepstep 30/84 - loss: 0.3554 - acc: 0.9570 - 81ms/stepstep 40/84 - loss: 0.3370 - acc: 0.9588 - 77ms/stepstep 50/84 - loss: 0.3662 - acc: 0.9592 - 74ms/stepstep 60/84 - loss: 0.3248 - acc: 0.9612 - 72ms/stepstep 70/84 - loss: 0.3667 - acc: 0.9603 - 71ms/stepstep 80/84 - loss: 0.3448 - acc: 0.9604 - 69ms/stepstep 84/84 - loss: 0.3349 - acc: 0.9613 - 66ms/stepEval samples: 10646Epoch 9/10step 10/125 - loss: 0.3650 - acc: 0.9594 - 121ms/stepstep 20/125 - loss: 0.3495 - acc: 0.9637 - 114ms/stepstep 30/125 - loss: 0.3436 - acc: 0.9669 - 109ms/stepstep 40/125 - loss: 0.3573 - acc: 0.9674 - 106ms/stepstep 50/125 - loss: 0.3390 - acc: 0.9694 - 104ms/stepstep 60/125 - loss: 0.3239 - acc: 0.9714 - 103ms/stepstep 70/125 - loss: 0.3281 - acc: 0.9729 - 102ms/stepstep 80/125 - loss: 0.3261 - acc: 0.9729 - 101ms/stepstep 90/125 - loss: 0.3198 - acc: 0.9734 - 100ms/stepstep 100/125 - loss: 0.3306 - acc: 0.9729 - 100ms/stepstep 110/125 - loss: 0.3193 - acc: 0.9737 - 101ms/stepstep 120/125 - loss: 0.3468 - acc: 0.9745 - 100ms/stepstep 125/125 - loss: 0.3413 - acc: 0.9743 - 99ms/stepEval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.3647 - acc: 0.9539 - 99ms/stepstep 20/84 - loss: 0.3593 - acc: 0.9578 - 79ms/stepstep 30/84 - loss: 0.3548 - acc: 0.9589 - 74ms/stepstep 40/84 - loss: 0.3333 - acc: 0.9598 - 73ms/stepstep 50/84 - loss: 0.3658 - acc: 0.9605 - 71ms/stepstep 60/84 - loss: 0.3247 - acc: 0.9617 - 70ms/stepstep 70/84 - loss: 0.3626 - acc: 0.9610 - 69ms/stepstep 80/84 - loss: 0.3414 - acc: 0.9614 - 67ms/stepstep 84/84 - loss: 0.3232 - acc: 0.9621 - 65ms/stepEval samples: 10646Epoch 10/10step 10/125 - loss: 0.3456 - acc: 0.9641 - 122ms/stepstep 20/125 - loss: 0.3336 - acc: 0.9711 - 111ms/stepstep 30/125 - loss: 0.3376 - acc: 0.9737 - 108ms/stepstep 40/125 - loss: 0.3581 - acc: 0.9732 - 104ms/stepstep 50/125 - loss: 0.3378 - acc: 0.9742 - 102ms/stepstep 60/125 - loss: 0.3228 - acc: 0.9757 - 101ms/stepstep 70/125 - loss: 0.3313 - acc: 0.9767 - 99ms/stepstep 80/125 - loss: 0.3334 - acc: 0.9762 - 99ms/stepstep 90/125 - loss: 0.3175 - acc: 0.9764 - 99ms/stepstep 100/125 - loss: 0.3304 - acc: 0.9762 - 99ms/stepstep 110/125 - loss: 0.3193 - acc: 0.9767 - 99ms/stepstep 120/125 - loss: 0.3469 - acc: 0.9773 - 99ms/stepstep 125/125 - loss: 0.3359 - acc: 0.9770 - 97ms/stepEval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.3624 - acc: 0.9578 - 95ms/stepstep 20/84 - loss: 0.3622 - acc: 0.9609 - 78ms/stepstep 30/84 - loss: 0.3528 - acc: 0.9620 - 74ms/stepstep 40/84 - loss: 0.3319 - acc: 0.9633 - 73ms/stepstep 50/84 - loss: 0.3561 - acc: 0.9639 - 71ms/stepstep 60/84 - loss: 0.3247 - acc: 0.9654 - 70ms/stepstep 70/84 - loss: 0.3520 - acc: 0.9647 - 69ms/stepstep 80/84 - loss: 0.3471 - acc: 0.9647 - 67ms/stepstep 84/84 - loss: 0.3202 - acc: 0.9653 - 64ms/stepEval samples: 10646save checkpoint at /home/aistudio/checkpoints/final登录后复制
启动VisualDL查看训练过程可视化结果
启动步骤:
1、切换到本界面左侧「可视化」2、日志文件路径选择 'visualdl'3、点击「启动VisualDL」后点击「打开VisualDL」,即可查看可视化结果: Accuracy和Loss的实时变化趋势如下: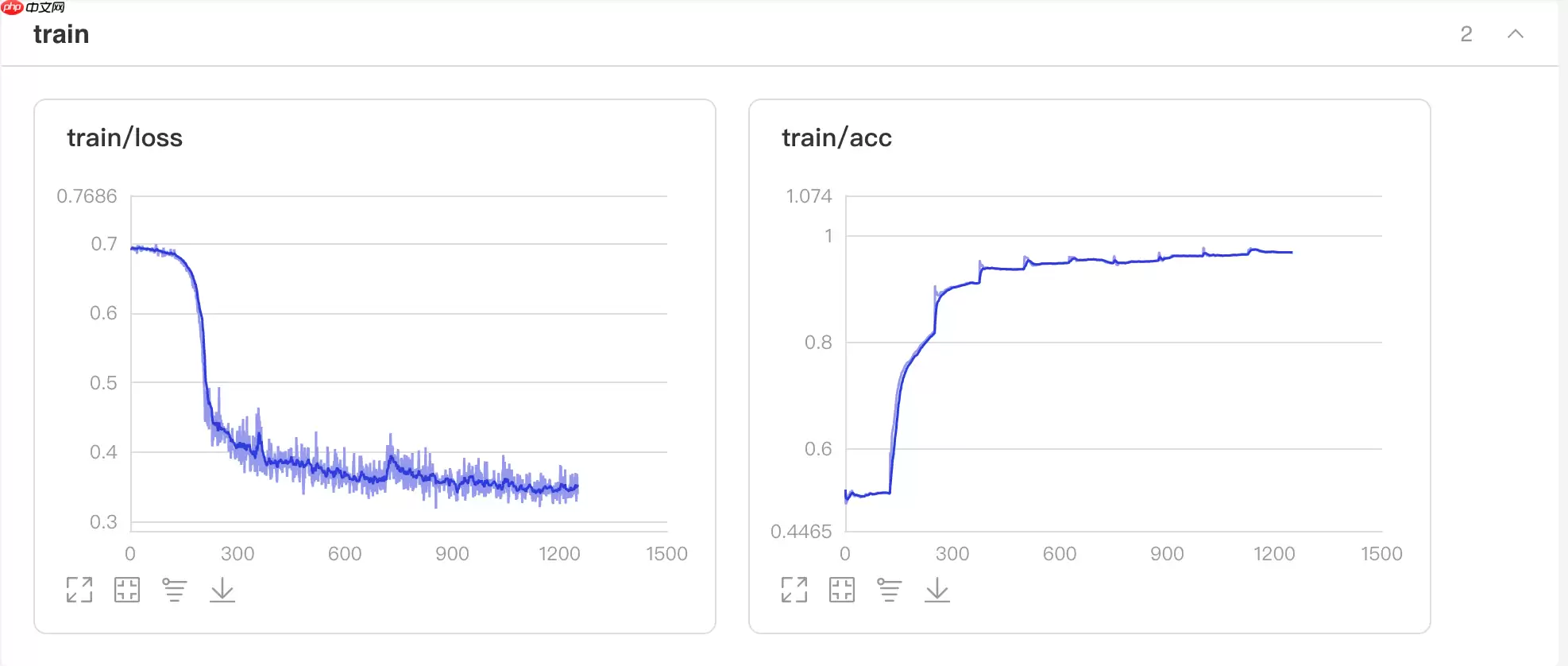 In [12]
In [12]results = model.evaluate(dev_loader)print("Finally test acc: %.5f" % results['acc'])登录后复制 Eval begin...The loss value printed in the log is the current batch, and the metric is the average value of previous step.step 10/84 - loss: 0.3624 - acc: 0.9578 - 95ms/stepstep 20/84 - loss: 0.3622 - acc: 0.9609 - 79ms/stepstep 30/84 - loss: 0.3528 - acc: 0.9620 - 74ms/stepstep 40/84 - loss: 0.3319 - acc: 0.9633 - 71ms/stepstep 50/84 - loss: 0.3561 - acc: 0.9639 - 69ms/stepstep 60/84 - loss: 0.3247 - acc: 0.9654 - 67ms/stepstep 70/84 - loss: 0.3520 - acc: 0.9647 - 66ms/stepstep 80/84 - loss: 0.3471 - acc: 0.9647 - 65ms/stepstep 84/84 - loss: 0.3202 - acc: 0.9653 - 63ms/stepEval samples: 10646Finally test acc: 0.96534登录后复制
预测
In [13]label_map = {0: 'negative', 1: 'positive'}results = model.predict(test_loader, batch_size=128)[0]predictions = []for batch_probs in results: # 映射分类label idx = np.argmax(batch_probs, axis=-1) idx = idx.tolist() labels = [label_map[i] for i in idx] predictions.extend(labels)# 看看预测数据前5个样例分类结果for idx, data in enumerate(test_ds.data[:10]): print('Data: {} \t Label: {}'.format(data[0], predictions[idx]))登录后复制 Predict begin...step 42/42 [==============================] - ETA: 4s - 106ms/st - ETA: 3s - 103ms/st - ETA: 3s - 102ms/st - ETA: 3s - 104ms/st - ETA: 3s - 100ms/st - ETA: 2s - 97ms/step - ETA: 2s - 93ms/ste - ETA: 2s - 90ms/ste - ETA: 2s - 87ms/ste - ETA: 1s - 85ms/ste - ETA: 1s - 83ms/ste - ETA: 1s - 81ms/ste - ETA: 1s - 79ms/ste - ETA: 1s - 78ms/ste - ETA: 0s - 77ms/ste - ETA: 0s - 77ms/ste - ETA: 0s - 76ms/ste - ETA: 0s - 75ms/ste - ETA: 0s - 73ms/ste - ETA: 0s - 71ms/ste - 68ms/step Predict samples: 5353Data: 楼面经理服务态度极差,等位和埋单都差,楼面小妹还挺好 Label: negativeData: 欺负北方人没吃过鲍鱼是怎么着?简直敷衍到可笑的程度,团购连青菜都是两人份?!难吃到死,菜色还特别可笑,什么时候粤菜的小菜改成拍黄瓜了?!把团购客人当sha子,可这满大厅的sha子谁还会再来?! Label: negativeData: 如果大家有时间而且不怕麻烦的话可以去这里试试,点一个饭等左2个钟,没错!是两个钟!期间催了n遍都说马上到,结果?呵呵。乳鸽的味道,太咸,可能不新鲜吧……要用重口味盖住异味。上菜超级慢!中途还搞什么表演,麻烦有人手的话就上菜啊,表什么演?!?!要大家饿着看表演吗?最后结账还算错单,我真心服了……有一种店叫不会有下次,大概就是指它吧 Label: negativeData: 偌大的一个大厅就一个人点菜,点菜速度超级慢,菜牌上多个菜停售,连续点了两个没标停售的菜也告知没有,粥上来是凉的,榴莲酥火大了,格格肉超级油腻而且咸?????? Label: negativeData: 泥撕雞超級好吃!!!吃了一個再叫一個還想打包的節奏! Label: positiveData: 作为地道的广州人,从小就跟着家人在西关品尝各式美食,今日带着家中长辈来这个老字号泮溪酒家真实失望透顶,出品差、服务差、洗手间邋遢弥漫着浓郁尿骚味、丢广州人的脸、丢广州老字号的脸。 Label: negativeData: 辣味道很赞哦!猪肚鸡一直是我们的最爱,每次来都必点,服务很给力,环境很好,值得分享哦!西洋菜 Label: positiveData: 第一次吃到這麼脏的火鍋:吃着吃著吃出一條尾指粗的黑毛毛蟲——惡心!脏!!!第一次吃到這麼無誠信的火鍋服務:我們呼喚人員時,某女部長立即使服務員迅速取走蟲所在的碗,任我們多次叫「放下」論理,她們也置若罔聞轉身將蟲毁屍滅跡,還嘻皮笑臉辯稱只是把碗換走,態度行為惡劣——jian詐!毫無誠信!!爛!!!當然還有剛坐下時的情形:第一次吃到這樣的火鍋:所有肉食熟食都上桌了,鍋底遲遲沒上,足足等了半小時才姍姍來遲;---差!!第一次吃到這樣的火鍋:1元雞鍋、1碟6塊小牛肉、1碟小腐皮、1碟5塊裝的普通肥牛、1碟數片的細碎牛肚結帳便2百多元;---不值!!以下省略千字差評......白云路的稻香是最差、最失禮的稻香,天河城、華廈的都比它好上過萬倍!!白云路的稻香是史上最差的餐廳!!! Label: negativeData: 文昌鸡份量很少且很咸,其他菜味道很一般!服务态度差差差!还要10%的服务费、 Label: negativeData: 这个 的评价真是越来越不可信了,搞不懂为什么这么多好评。真的是很一般,不要迷信什么哪里回来的大厨吧。环境和出品若是当作普通茶餐厅来看待就还说得过去,但是价格又不是茶餐厅的价格,这就很尴尬了。。服务也是有待提高。 Label: negative登录后复制
这里只采用了一个基础的模型,就得到了较高的的准确率。
可以试试预训练模型,能得到更好的效果!参考如何通过预训练模型Fine-tune下游任务
首先就是先处理数据,把文本转换成词向量,接着构造神经网络 ,进行训练,调整 网络模型,最后获得一个比较好的结果
相关攻略

常见报错解析:“Access Not Configured”故障排除指南 许多开发者和团队成员在使用OpenClaw集成飞书时,都曾遭遇过一个典型的中断提示:“access not configured”(访问未配置)。该提示会明确显示您的飞书账户ID及一组唯一的配对验证码,并指出需要联系机器人所有

OpenClaw 常用指令大全与使用详解 openclaw status:此命令是查看OpenClaw系统整体健康状态的核心指令,执行后即获取服务运行状况的全面报告,是日常运维的首要诊断工具。 openclaw gateway restart:在修改网关配置后,必须运行此指令以重启网关服务,使配置文

如何通过 OpenClaw 实现 Chrome 浏览器自动化操控 在软件开发与自动化测试领域,持续学习是常态。本文旨在详细介绍如何利用 OpenClaw 连接并控制一个已开启的 Chrome 浏览器实例,实现点击、文本输入、文件上传、页面滚动、屏幕截图以及执行 JavaScript 等自动化操作。整
项目概述 你是否希望将强大的 AI 助手带入日常聊天?本教程将指导你完成搭建流程,让你能在 QQ 上直接调用 OpenClaw 智能助手,实现无门槛的 AI 对话体验。 架构说明 ┌─────────────┐ ┌──────────────┐ ┌─────────────┐ │ QQ 用户 │ ─

一 下载并安装Node js,全程保持默认设置 首先,请前往Node js官方网站的下载中心:https: nodejs org zh-cn download。根据您的操作系统(Windows Mac Linux)下载对应的安装程序。运行安装向导时,整个过程非常简单,您只需连续点击“下一步”按钮
热门专题







热门推荐

OPPO A6k手机重磅发布:天玑6300处理器、高清LCD直屏、7000mAh超大电池,售价仅1999元起 OPPO旗下广受欢迎的A系列再添实力新机。近日,备受期待的OPPO A6k正式上市发售。这款新品搭载了备受好评的天玑6300八核处理器,并配备了一块容量高达7000mAh的耐用长寿电池,成为

速览 在《红色沙漠》的广阔世界中,数量丰富的支线任务与主线剧情共同构筑了沉浸式的冒险体验。其中,“熔化锁链的火焰”任务作为瑟金斯家族剧情线的关键环节,其触发机制与主线进程紧密相连。任务并非随时可用,玩家需将主线故事推进到特定阶段后,任务才会自动添加至任务日志。本篇攻略将为你详解此支线任务的接取条件与

《异种航员2》运动机制深度解析 在《异种航员2》(Xenonauts 2)的策略战斗中,对“时间单位”(TU)的高效运用是取胜的核心。每个士兵的移动、射击乃至战术配合,都依赖于玩家对TU的精确规划。操作上手简单:选中单位后,直接使用鼠标左键点击目的地方格,系统便会清晰显示移动所需消耗的时间单位,帮助

速览 在《异种航员2》(Xenonauts 2)的战局中,掌握“战术规避”与精通“火力输出”同等关键。游戏全新设计的掩体系统,是提升你作战小队生存几率的战略性核心。简言之,战场上绝大多数可见的物体都能转化为你的战术屏障。无论是散落的木箱、残缺的矮墙,还是茂密的灌木丛与坚实的建筑物,巧妙地利用它们,就

速览 在开放世界大作《红色沙漠》中,庞大的支线任务系统为玩家提供了丰富的探索体验。其中,“超凡建造物”任务是阿方索家族势力任务线中的重要一环。要成功接取此任务,玩家必须首先完成其前置任务【枪械名门】。在此之后,任务的下一步关键操作是前往游戏中标注的特定建筑地点进行互动调查——这本质上是一个用于快速移