最近邻算法(kNN)详解
本文介绍kNN算法,其通过计算不同特征值距离分类样本。以电影分类为例说明原理,还讲解用Numpy实现该算法的步骤,包括数据预处理、模型训练等,也提及超参数搜索函数,最后展示了用sklearn封装好的方法实现,以及相关笔记内容。

原理介绍
简言之,kNN算法计算不同特征值之间的距离对样本进行分类。
OK,说完结论,懂的可以直接看代码部分了,如果不能理解的请听我娓娓道来~现在有这么一组数据
上面6个样本(电影)分别给出其特征(打斗镜头、拥抱镜头)和标签(电影类型)信息,现在给定一个新的样本,我们想知道这部电影的类型。由于是2维数据,我们可以用平面直角坐标系表示。
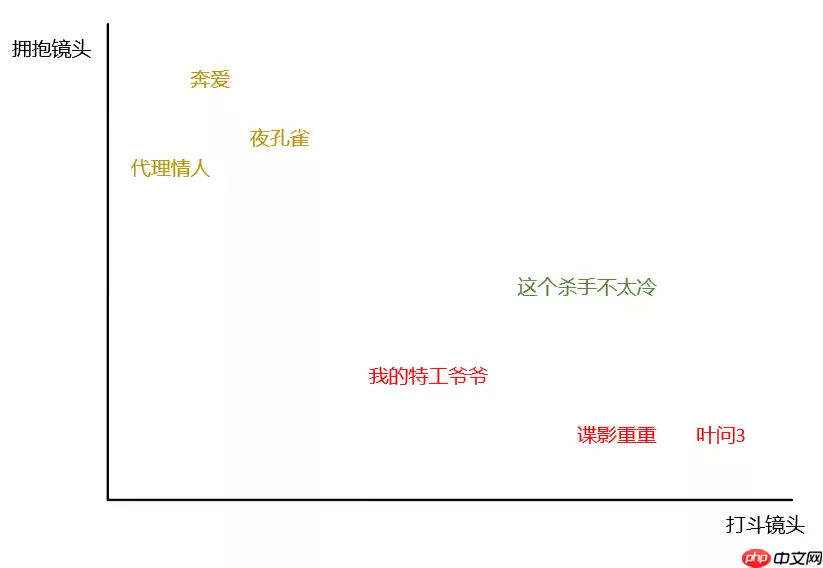
绿色的点是未知的,红色的黄色的点是已知的。kNN要做的就是计算未知的点到所有已知点的距离,根据距离进行排序。
D谍影重重=(49−57)2+(6−2)2≈8.94
D叶问3=(49−65)2+(6−2)2≈16.49
D我的特工爷爷=(49−21)2+(6−4)2≈28.07
D奔爱=(49−4)2+(6−46)2≈60.21
D夜孔雀=(49−8)2+(6−39)2≈52.63
D代理情人=(49−2)2+(6−38)2≈56.86
排序后的数据如下,
我们在kNN算法中经常会听到说当k=3时、当k=5时...这里的k指的就是样本数。在这个例子中,当k=3时,前三个样本出现最多的电影类型是动作片,因此《这个杀手不太冷》样本也应该归为动作片。同样的,当k=5时,前5个样本出现最多的电影类型也是动作片(53>52),因此样本也属于动作片。
上面提到的是2维数据,但是我们现实中处理的样本可能有3个甚至更多特征,我们无法用视觉来抽象这些特征,但是计算方法还是一样的,只不过根号里做差的数变多了而已。
代码实现——Numpy
机器学习算法的一般流程可以归为三步。
数据预处理加载数据交叉验证归一化模型训练模型验证机器学习的任务就是从海量数据中找到有价值的信息, 所以在使用算法之前,我们要对数据进行预处理。
In [17]# 1. 加载莺尾花数据集from sklearn import datasetsiris = datasets.load_iris()X = iris.datay = iris.target登录后复制
如果我们查看y标签信息会发现,它的前50个值为0,51—100的值为1,后50个值为2,如果直接交叉验证,取到的测试集数据可能都是label值为2的样本,这并不是我们想要的。所以在这之前,我们需要先对样本打乱顺序。zip()能将可迭代的对象打包成元组,利用 * 操作符可以将元组解压为列表。
In [18]# 2. 实现交叉验证import numpy as npdef train_test_split(X, y, ratio=0.3): # 乱序 data = list(zip(X, y)) np.random.shuffle(data) X, y = zip(*data) # 切割 boundary_X = int((1-ratio) * len(X)) boundary_y = int((1-ratio) * len(y)) # 将boundary_X和boundary_y之前的作为训练集 x_train = np.array(X[: boundary_X]) x_test = np.array(X[boundary_X:]) y_train = np.array(y[: boundary_y]) y_test = np.array(y[boundary_y:]) return x_train, x_test, y_train, y_testx_train, x_test, y_train, y_test = train_test_split(X, y)登录后复制
归一化主要有两种形式:0-1均匀分布和标准正态分布。
In [19]# 3. 归一化def normalization(data): return (data - data.min()) / (data.max() - data.min()) def standardization(data): return (data - data.mean()) / data.std()x_train = standardization(x_train)x_test = standardization(x_test)登录后复制
kNN的“模型训练”有点不同于一般的模型训练过程,它们可能需要求一些参数,而kNN是计算未知点到已知点的距离。从严格意义上来说,这并不算是训练。
In [20]# 4. 距离计算from collections import Counterclass KNNClassifier: def __init__(self, k): self._k = k self._X_train = None self._y_train = None def fit(self, X_train, y_train): self._X_train = X_train self._y_train = y_train # 预测X_predict样本的分类结果,这里的X_predict用的是交叉验证中的测试集 def predict(self, X_predict): return np.array([self._predict(x) for x in X_predict]) def _predict(self, x): # 计算输入样本_X_train到所有已知数据的距离 distances = np.sqrt(np.sum((self._X_train - x)**2, axis=1)) # 记录distances中前k个小的数对应的类别的出现次数 votes = Counter(self._y_train[np.argpartition(distances, self._k)[: self._k]]) # most_common(n)可以打印n个出现最多次元素的值和次数 predict_y = votes.most_common(1)[0][0] return predict_y # 计算准确率 def score(self, X_test, label): y_predict = self.predict(X_test) n_sample = len(label) right_sample = 0 for i, e in enumerate(label): if y_predict[i] == e: right_sample += 1 return right_sample / n_sampleknn = KNNClassifier(k=3)knn.fit(x_train, y_train)knn.score(x_test, y_test)登录后复制
0.9555555555555556登录后复制
超参数搜索函数
kNN的参数不止是k,距离模式distype也是它的参数。对于k和distype这两种参数的组合,可能会有很多不同的结果,不妨设计一个超参数搜索函数来优化k和distype。
In [21]class KNNClassifierSuper(KNNClassifier): def __init__(self, k, distype): super().__init__(k) self.distype = distype def _predict(self, x): assert self.distype in ["1", "2", "3"], "Error distance type!" if self.distype == "1": distances = np.sum(abs(self._X_train - x), axis=1) elif self.distype == "2": distances = np.sqrt(np.sum((self._X_train - x)**2, axis=1)) else: distances = np.max(abs(self._X_train - x), axis=1) votes = Counter(self._y_train[np.argpartition(distances, self._k)[: self._k]]) predict_y = votes.most_common(1)[0][0] return predict_y# ManhattanDistance —— "1"# EuclideanDistance —— "2"# ChebyshevDistance —— "3"for k in range(3, 15, 2): for distype in range(1, 4): knn = KNNClassifierSuper(k, str(distype)) knn.fit(x_train, y_train) print("k = {} distype = {} score = {}".format( k, distype, knn.score(x_test, y_test)))登录后复制 k = 3distype = 1score = 0.9555555555555556k = 3distype = 2score = 0.9555555555555556k = 3distype = 3score = 0.9777777777777777k = 5distype = 1score = 0.9777777777777777k = 5distype = 2score = 0.9777777777777777k = 5distype = 3score = 0.9777777777777777k = 7distype = 1score = 0.9777777777777777k = 7distype = 2score = 0.9777777777777777k = 7distype = 3score = 1.0k = 9distype = 1score = 0.9555555555555556k = 9distype = 2score = 0.9777777777777777k = 9distype = 3score = 1.0k = 11distype = 1score = 0.9777777777777777k = 11distype = 2score = 0.9555555555555556k = 11distype = 3score = 0.9777777777777777k = 13distype = 1score = 0.9777777777777777k = 13distype = 2score = 1.0k = 13distype = 3score = 0.9333333333333333登录后复制
代码实现——sklearn
上面我们用Numpy实现了交叉验证、归一化、距离计算等方法,这些在sklearn中都已经为我们封装好了。
In [31]from sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn import preprocessingfrom sklearn.neighbors import KNeighborsClassifier# 加载莺尾花数据iris = datasets.load_iris()X, y = iris.data, iris.target# 交叉验证x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.4)# 归一化x_train = preprocessing.scale(x_train)x_test = preprocessing.scale(x_test)# 距离计算 + 超参数搜索函数# p = 1 manhattan_distance # p = 2 euclidean_distance# arbitrary p minkowski_distance for k in range(3, 14, 2): for p in range(1, 5): knn = KNeighborsClassifier(n_neighbors=k, p=p) knn.fit(x_train, y_train) print("k = {} p = {} score = {}".format( k, p, knn.score(x_test, y_test)))登录后复制 k = 3p = 1score = 0.9666666666666667k = 3p = 2score = 0.9833333333333333k = 3p = 3score = 0.9666666666666667k = 3p = 4score = 0.9666666666666667k = 5p = 1score = 0.9666666666666667k = 5p = 2score = 0.9833333333333333k = 5p = 3score = 0.9833333333333333k = 5p = 4score = 0.9833333333333333k = 7p = 1score = 0.9833333333333333k = 7p = 2score = 0.9833333333333333k = 7p = 3score = 0.9833333333333333k = 7p = 4score = 0.9833333333333333k = 9p = 1score = 0.9666666666666667k = 9p = 2score = 0.95k = 9p = 3score = 0.9666666666666667k = 9p = 4score = 0.9666666666666667k = 11p = 1score = 0.9666666666666667k = 11p = 2score = 0.95k = 11p = 3score = 0.9333333333333333k = 11p = 4score = 0.9333333333333333k = 13p = 1score = 0.9666666666666667k = 13p = 2score = 0.95k = 13p = 3score = 0.9166666666666666k = 13p = 4score = 0.9166666666666666登录后复制
笔记
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()ndarray计算的时候尽量用np的属性(np.sum()而不是sum)
ValueError: kth(=3) out of bounds (1)
计算距离的时候np.sum()需要指定axis=1,不然会直接对多维数组进行sum得到一个数值,在np.argpartition会出错。
np.sum()如果不指定axis是无法广播的,会直接返回数值
axis一种较好的理解方式是把他看成消除器。对于shape为(2L, 3L, 4L)的数组arr,np.sum(arr, axis=0)会返回shape为(3L, 4L)的数组,np.sum(arr, axis=1) 会返回shape为(2L, 4L)的数组,np.sum(arr, axis=0)会返回shape为(2L, 3L)的数组。
相关攻略

在Excel中合并单元格内容,可使用&符号、CONCATENATE或TEXTJOIN函数。&适合简单拼接,CONCATENATE可合并多个值,TEXTJOIN能忽略空值且更灵活。根据实际需求与Excel版本选择方法,可有效提升数据处理效率。

在Excel中固定前三行可提升数据查看效率。主要方法包括:使用“冻结窗格”功能并选择“冻结首三行”;先选中前三行再执行“冻结窗格”;或通过快捷键Alt+W+F+F快速实现。固定后,前三行将始终显示在顶部,方便浏览下方数据时对照表头。

清晰醒目的表头能提升Excel表格的专业性与数据处理效率。通过调整列宽确保内容完整显示,应用样式使表头醒目突出。冻结窗格可使表头在滚动时始终可见,而启用筛选功能则能快速查询和分类数据。这些技巧共同助力表格管理更加井井有条。

使用情景 进入年中,职场人士普遍面临一项关键任务:准备半年度工作总结PPT。这份材料不仅是上半年工作的梳理,更是向领导和团队展示个人价值、项目成效与团队势能的核心载体。一份逻辑清晰、重点突出、呈现专业的总结,能够有效提振团队士气,为下半年工作指明方向。 然而,将庞杂的工作内容转化为结构严谨、观点鲜明

文档背景颜色影响视觉效果与信息传递效率。在WPS中可通过“页面布局”设置背景色。不同行业需求各异,如金融领域适合深色背景,创意行业常用亮色。合理运用背景色能提升专业性、优化阅读体验并强化品牌识别,是高效沟通的辅助工具。
热门专题







热门推荐

Binance币安 欧易OKX Huobi火币 访问币安(Binance)官网时,平台会根据用户所在地区进行智能跳转,这是为了满足不同区域的合规要求。目前,全球通用的主站官方域名是 binance com,记住这个地址,通常是最直接、最安全的访问起点。 如何正确访问币安官网 操作其实很简单:在浏览器

BNB突破1000美元:长期持有者为何坚定不离场? 当BNB价格成功站上1000美元大关,市场并未出现预期中的大规模获利了结潮。相反,众多长期持有者选择了继续坚守。这一现象背后,并非简单的市场情绪驱动,而是基于一套由代币经济模型、生态活力、传统资本流入及政策风险缓解共同构成的复合价值逻辑。本文将深度

标普500创新高,但以比特币计价却暴跌88%:重新审视资产估值坐标系 当市场为标普500指数屡创新高而欢呼时,一个颠覆性的视角正在引发深思。如果我们将计价单位从美元切换为比特币,这幅繁荣图景将彻底改写。数据显示,自2020年以来,标普500指数以美元计价上涨了106%,表现稳健;然而,若以比特币作为

交易的基石——两大内核分析流派 在探讨具体的买卖时机之前,有必要先理清驱动市场波动的两套底层逻辑:基本面分析与技术分析。这两者,好比是导航的地图和罗盘,各有侧重,却又相辅相成。 1 基本面分析:评估“真实价值” 这一流派的核心,是探究资产的内在价值。它关注三个层面: 项目质量: 这个项目究竟要解决

如何利用AI技术提升文档处理效率,快速生成专业报告和PPT 在内容爆炸的时代,文档处理的速度与质量,直接决定了商业决策和项目推进的效率。过去,一份专业报告或一份精心设计的PPT,背后往往意味着团队数日乃至数周的伏案工作。但如今,情况正在发生根本性的转变。行业观察显示,利用AI技术优化文档工作流,正从