EPSANet:多尺度通道注意力机制
本文复现了EPSANet,其核心是高效金字塔注意力分割模块(EPSA)。该模块通过SPC获取多尺度特征图,经SE提取注意力、Softmax校准后加权输出。文中给出模块及网络完整代码,构建了EPSANet50等模型,并在Cifar10上与ResNet-50对比,显示其性能更优,泛化性强,适用于多种下游任务。

前言
Hi guy!我们这下又见面了,这次是来复现 EPSANet
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
关于注意力机制,实际上最近我比较关注enhance一类的文章,这篇论文也可以算是划分到enhance一类,先上性能图
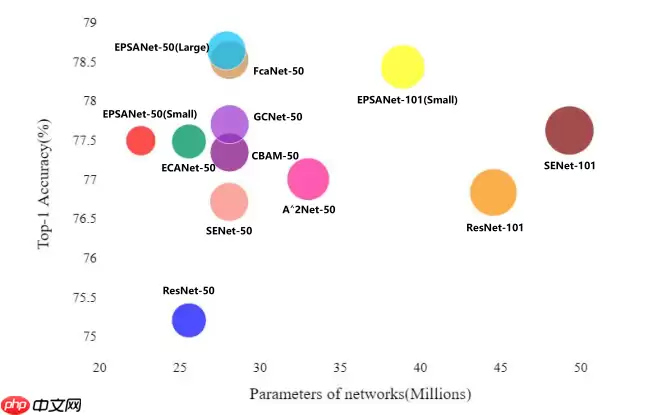
不得不说这个图做的还怪好看,可视化效果也蛮直观,性能还可以
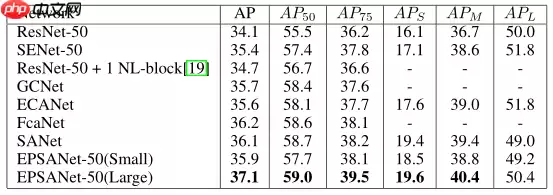
不仅是图像分类,而且在下游任务比如目标检测分割上,也展现了良好的性能
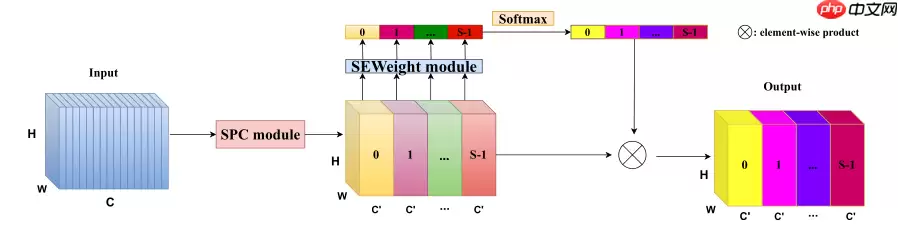
高效金字塔注意力分割模块(EPSA)
EPSA模块可以有效地提取更细粒度的多尺度空间信息,同时可以建立更长距离的通道依赖关系
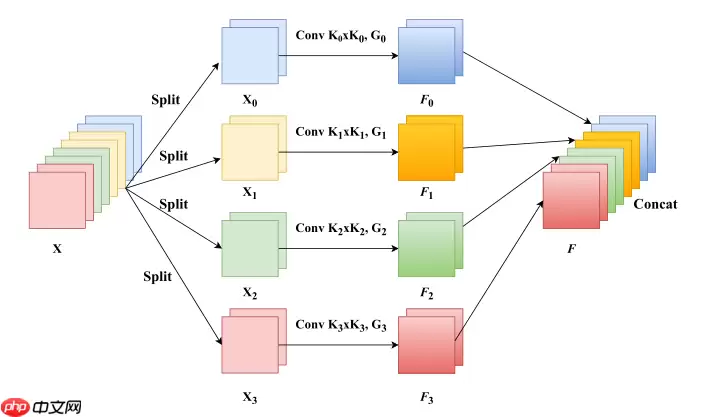
其中 SPC module 如下
PSA模块主要分四个步骤实现:
通过 Split And Concat(SPC)得到多尺度特征图用SE提取多尺度特征图中不同尺度的 attention用Softmax对attention进行重新校准对重新校准的权重和相应的特征图进行乘积输出得到一个多尺度特征信息注意力加权之后的特征图。该特征图多尺度信息表示能力更丰富。
In [1]import paddleimport paddle.nn as nnimport mathdef conv(in_planes, out_planes, kernel_size=3, stride=1, padding=1, dilation=1, groups=1): """standard convolution with padding""" return nn.Conv2D(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias_attr=False)def conv1x1(in_planes, out_planes, stride=1): """1x1 convolution""" return nn.Conv2D(in_planes, out_planes, kernel_size=1, stride=stride, bias_attr=False)class SEWeightModule(nn.Layer): def __init__(self, channels, reduction=16): super(SEWeightModule, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2D(1) self.fc1 = nn.Conv2D(channels, channels//reduction, kernel_size=1, padding=0) self.relu = nn.ReLU() self.fc2 = nn.Conv2D(channels//reduction, channels, kernel_size=1, padding=0) self.sigmoid = nn.Sigmoid() def forward(self, x): out = self.avg_pool(x) out = self.fc1(out) out = self.relu(out) out = self.fc2(out) weight = self.sigmoid(out) return weightclass PSAModule(nn.Layer): def __init__(self, inplans, planes, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]): super(PSAModule, self).__init__() self.conv_1 = conv(inplans, planes//4, kernel_size=conv_kernels[0], padding=conv_kernels[0]//2, stride=stride, groups=conv_groups[0]) self.conv_2 = conv(inplans, planes//4, kernel_size=conv_kernels[1], padding=conv_kernels[1]//2, stride=stride, groups=conv_groups[1]) self.conv_3 = conv(inplans, planes//4, kernel_size=conv_kernels[2], padding=conv_kernels[2]//2, stride=stride, groups=conv_groups[2]) self.conv_4 = conv(inplans, planes//4, kernel_size=conv_kernels[3], padding=conv_kernels[3]//2, stride=stride, groups=conv_groups[3]) self.se = SEWeightModule(planes // 4) self.split_channel = planes // 4 self.softmax = nn.Softmax(axis=1) def forward(self, x): # stage 1 batch_size = x.shape[0] x1 = self.conv_1(x) x2 = self.conv_2(x) x3 = self.conv_3(x) x4 = self.conv_4(x) feats = paddle.concat((x1, x2, x3, x4), axis=1) feats = feats.reshape([batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3]]) # stage 2 x1_se = self.se(x1) x2_se = self.se(x2) x3_se = self.se(x3) x4_se = self.se(x4) x_se = paddle.concat((x1_se, x2_se, x3_se, x4_se), axis=1) attention_vectors = x_se.reshape([batch_size, 4, self.split_channel, 1, 1]) attention_vectors = self.softmax(attention_vectors) # stage 3 # stage 4 feats_weight = feats * attention_vectors for i in range(4): x_se_weight_fp = feats_weight[:, i, :, :] if i == 0: out = x_se_weight_fp else: out = paddle.concat((x_se_weight_fp, out), axis=1) return out登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):登录后复制In [3]
# 验证 PSA psa = PSAModule(64, 64)x = paddle.randn([32, 64, 112, 112])y = psa(x)print(y)登录后复制
EPSANet
现在搭建一个EPSANet,它基于EPSA Block,从下图可以看出EPSA Block用PSA模块代替了ResNet Block的Conv 3x3卷积
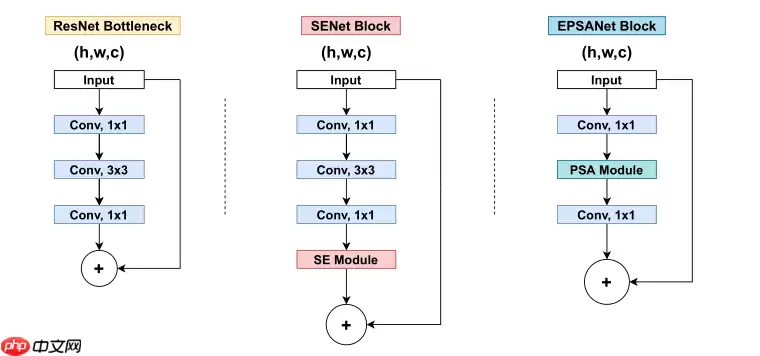
与ResNet-50对比
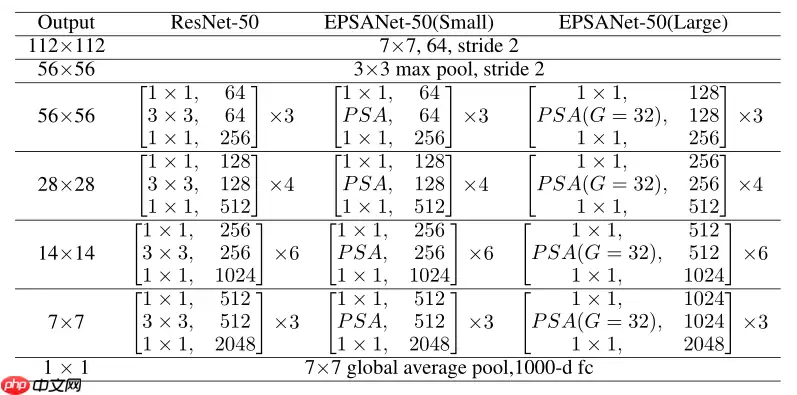
class EPSABlock(nn.Layer): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None, norm_layer=None, conv_kernels=[3, 5, 7, 9], conv_groups=[1, 4, 8, 16]): super(EPSABlock, self).__init__() if norm_layer is None: norm_layer = nn.BatchNorm2D self.conv1 = conv1x1(inplanes, planes) self.bn1 = norm_layer(planes) self.conv2 = PSAModule(planes, planes, stride=stride, conv_kernels=conv_kernels, conv_groups=conv_groups) self.bn2 = norm_layer(planes) self.conv3 = conv1x1(planes, planes * self.expansion) self.bn3 = norm_layer(planes * self.expansion) self.relu = nn.ReLU() self.downsample = downsample self.stride = stride def forward(self, x): identity = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: identity = self.downsample(x) out += identity out = self.relu(out) return outclass EPSANet(nn.Layer): def __init__(self, block, layers, num_classes=1000): super(EPSANet, self).__init__() self.inplanes = 64 self.conv1 = nn.Conv2D(3, 64, kernel_size=7, stride=2, padding=3, bias_attr=False) self.bn1 = nn.BatchNorm2D(64) self.relu = nn.ReLU() self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layers(block, 64, layers[0], stride=1) self.layer2 = self._make_layers(block, 128, layers[1], stride=2) self.layer3 = self._make_layers(block, 256, layers[2], stride=2) self.layer4 = self._make_layers(block, 512, layers[3], stride=2) self.avgpool = nn.AdaptiveAvgPool2D((1, 1)) self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.sublayers(): if isinstance(m, nn.Conv2D): n = m.weight.shape[2] * m.weight.shape[3] * m.weight.shape[0] normal_ = nn.initializer.Normal(std=math.sqrt(2. / n)) normal_(m.weight) def _make_layers(self, block, planes, num_blocks, stride=1): downsample = None if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( nn.Conv2D(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias_attr=False), nn.BatchNorm2D(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample)) self.inplanes = planes * block.expansion for i in range(1, num_blocks): layers.append(block(self.inplanes, planes)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.reshape([x.shape[0], -1]) x = self.fc(x) return x登录后复制
模型定义
In [5]def epsanet50(**kwarg): model = EPSANet(EPSABlock, [3, 4, 6, 3], **kwarg) return modeldef epsanet101(): model = EPSANet(EPSABlock, [3, 4, 23, 3], **kwarg) return model登录后复制
查看模型
In [6]paddle.Model(epsanet50()).summary((1,3,224,224))登录后复制
-------------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # ================================================================================ Conv2D-13 [[1, 3, 224, 224]] [1, 64, 112, 112] 9,408 BatchNorm2D-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 256 ReLU-3 [[1, 64, 112, 112]] [1, 64, 112, 112] 0 MaxPool2D-1 [[1, 64, 112, 112]] [1, 64, 56, 56] 0 Conv2D-15 [[1, 64, 56, 56]] [1, 64, 56, 56] 4,096 BatchNorm2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-5 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 Conv2D-16 [[1, 64, 56, 56]] [1, 16, 56, 56] 9,216 Conv2D-17 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,400 Conv2D-18 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,272 Conv2D-19 [[1, 64, 56, 56]] [1, 16, 56, 56] 5,184 AdaptiveAvgPool2D-3 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Conv2D-20 [[1, 16, 1, 1]] [1, 1, 1, 1] 17 ReLU-4 [[1, 1, 1, 1]] [1, 1, 1, 1] 0 Conv2D-21 [[1, 1, 1, 1]] [1, 16, 1, 1] 32 Sigmoid-3 [[1, 16, 1, 1]] [1, 16, 1, 1] 0 SEWeightModule-3 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Softmax-3 [[1, 4, 16, 1, 1]] [1, 4, 16, 1, 1] 0 PSAModule-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 BatchNorm2D-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 Conv2D-22 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-5 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 Conv2D-14 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 EPSABlock-1 [[1, 64, 56, 56]] [1, 256, 56, 56] 0 Conv2D-23 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384 BatchNorm2D-6 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-7 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 Conv2D-24 [[1, 64, 56, 56]] [1, 16, 56, 56] 9,216 Conv2D-25 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,400 Conv2D-26 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,272 Conv2D-27 [[1, 64, 56, 56]] [1, 16, 56, 56] 5,184 AdaptiveAvgPool2D-4 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Conv2D-28 [[1, 16, 1, 1]] [1, 1, 1, 1] 17 ReLU-6 [[1, 1, 1, 1]] [1, 1, 1, 1] 0 Conv2D-29 [[1, 1, 1, 1]] [1, 16, 1, 1] 32 Sigmoid-4 [[1, 16, 1, 1]] [1, 16, 1, 1] 0 SEWeightModule-4 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Softmax-4 [[1, 4, 16, 1, 1]] [1, 4, 16, 1, 1] 0 PSAModule-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 BatchNorm2D-7 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 Conv2D-30 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-8 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 EPSABlock-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 Conv2D-31 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384 BatchNorm2D-9 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-9 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 Conv2D-32 [[1, 64, 56, 56]] [1, 16, 56, 56] 9,216 Conv2D-33 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,400 Conv2D-34 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,272 Conv2D-35 [[1, 64, 56, 56]] [1, 16, 56, 56] 5,184 AdaptiveAvgPool2D-5 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Conv2D-36 [[1, 16, 1, 1]] [1, 1, 1, 1] 17 ReLU-8 [[1, 1, 1, 1]] [1, 1, 1, 1] 0 Conv2D-37 [[1, 1, 1, 1]] [1, 16, 1, 1] 32 Sigmoid-5 [[1, 16, 1, 1]] [1, 16, 1, 1] 0 SEWeightModule-5 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Softmax-5 [[1, 4, 16, 1, 1]] [1, 4, 16, 1, 1] 0 PSAModule-5 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 BatchNorm2D-10 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 Conv2D-38 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-11 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 EPSABlock-3 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 Conv2D-40 [[1, 256, 56, 56]] [1, 128, 56, 56] 32,768 BatchNorm2D-13 [[1, 128, 56, 56]] [1, 128, 56, 56] 512 ReLU-11 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-41 [[1, 128, 56, 56]] [1, 32, 28, 28] 36,864 Conv2D-42 [[1, 128, 56, 56]] [1, 32, 28, 28] 25,600 Conv2D-43 [[1, 128, 56, 56]] [1, 32, 28, 28] 25,088 Conv2D-44 [[1, 128, 56, 56]] [1, 32, 28, 28] 20,736 AdaptiveAvgPool2D-6 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Conv2D-45 [[1, 32, 1, 1]] [1, 2, 1, 1] 66 ReLU-10 [[1, 2, 1, 1]] [1, 2, 1, 1] 0 Conv2D-46 [[1, 2, 1, 1]] [1, 32, 1, 1] 96 Sigmoid-6 [[1, 32, 1, 1]] [1, 32, 1, 1] 0 SEWeightModule-6 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Softmax-6 [[1, 4, 32, 1, 1]] [1, 4, 32, 1, 1] 0 PSAModule-6 [[1, 128, 56, 56]] [1, 128, 28, 28] 0 BatchNorm2D-14 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 Conv2D-47 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-15 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 Conv2D-39 [[1, 256, 56, 56]] [1, 512, 28, 28] 131,072 BatchNorm2D-12 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 EPSABlock-4 [[1, 256, 56, 56]] [1, 512, 28, 28] 0 Conv2D-48 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536 BatchNorm2D-16 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-13 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-49 [[1, 128, 28, 28]] [1, 32, 28, 28] 36,864 Conv2D-50 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,600 Conv2D-51 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,088 Conv2D-52 [[1, 128, 28, 28]] [1, 32, 28, 28] 20,736 AdaptiveAvgPool2D-7 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Conv2D-53 [[1, 32, 1, 1]] [1, 2, 1, 1] 66 ReLU-12 [[1, 2, 1, 1]] [1, 2, 1, 1] 0 Conv2D-54 [[1, 2, 1, 1]] [1, 32, 1, 1] 96 Sigmoid-7 [[1, 32, 1, 1]] [1, 32, 1, 1] 0 SEWeightModule-7 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Softmax-7 [[1, 4, 32, 1, 1]] [1, 4, 32, 1, 1] 0 PSAModule-7 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 BatchNorm2D-17 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 Conv2D-55 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-18 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 EPSABlock-5 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-56 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536 BatchNorm2D-19 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-15 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-57 [[1, 128, 28, 28]] [1, 32, 28, 28] 36,864 Conv2D-58 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,600 Conv2D-59 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,088 Conv2D-60 [[1, 128, 28, 28]] [1, 32, 28, 28] 20,736 AdaptiveAvgPool2D-8 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Conv2D-61 [[1, 32, 1, 1]] [1, 2, 1, 1] 66 ReLU-14 [[1, 2, 1, 1]] [1, 2, 1, 1] 0 Conv2D-62 [[1, 2, 1, 1]] [1, 32, 1, 1] 96 Sigmoid-8 [[1, 32, 1, 1]] [1, 32, 1, 1] 0 SEWeightModule-8 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Softmax-8 [[1, 4, 32, 1, 1]] [1, 4, 32, 1, 1] 0 PSAModule-8 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 BatchNorm2D-20 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 Conv2D-63 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-21 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 EPSABlock-6 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-64 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536 BatchNorm2D-22 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-17 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-65 [[1, 128, 28, 28]] [1, 32, 28, 28] 36,864 Conv2D-66 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,600 Conv2D-67 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,088 Conv2D-68 [[1, 128, 28, 28]] [1, 32, 28, 28] 20,736 AdaptiveAvgPool2D-9 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Conv2D-69 [[1, 32, 1, 1]] [1, 2, 1, 1] 66 ReLU-16 [[1, 2, 1, 1]] [1, 2, 1, 1] 0 Conv2D-70 [[1, 2, 1, 1]] [1, 32, 1, 1] 96 Sigmoid-9 [[1, 32, 1, 1]] [1, 32, 1, 1] 0 SEWeightModule-9 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Softmax-9 [[1, 4, 32, 1, 1]] [1, 4, 32, 1, 1] 0 PSAModule-9 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 BatchNorm2D-23 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 Conv2D-71 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-24 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 EPSABlock-7 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-73 [[1, 512, 28, 28]] [1, 256, 28, 28] 131,072 BatchNorm2D-26 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024 ReLU-19 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-74 [[1, 256, 28, 28]] [1, 64, 14, 14] 147,456 Conv2D-75 [[1, 256, 28, 28]] [1, 64, 14, 14] 102,400 Conv2D-76 [[1, 256, 28, 28]] [1, 64, 14, 14] 100,352 Conv2D-77 [[1, 256, 28, 28]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-10 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-78 [[1, 64, 1, 1]] [1, 4, 1, 1] 260 ReLU-18 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-79 [[1, 4, 1, 1]] [1, 64, 1, 1] 320 Sigmoid-10 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-10 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-10 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-10 [[1, 256, 28, 28]] [1, 256, 14, 14] 0 BatchNorm2D-27 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 Conv2D-80 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-28 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 Conv2D-72 [[1, 512, 28, 28]] [1, 1024, 14, 14] 524,288 BatchNorm2D-25 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 EPSABlock-8 [[1, 512, 28, 28]] [1, 1024, 14, 14] 0 Conv2D-81 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-29 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-21 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-82 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-83 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-84 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-85 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-11 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-86 [[1, 64, 1, 1]] [1, 4, 1, 1] 260 ReLU-20 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-87 [[1, 4, 1, 1]] [1, 64, 1, 1] 320 Sigmoid-11 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-11 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-11 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-11 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-30 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 Conv2D-88 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-31 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 EPSABlock-9 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-89 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-32 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-23 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-90 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-91 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-92 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-93 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-12 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-94 [[1, 64, 1, 1]] [1, 4, 1, 1] 260 ReLU-22 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-95 [[1, 4, 1, 1]] [1, 64, 1, 1] 320 Sigmoid-12 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-12 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-12 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-12 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-33 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 Conv2D-96 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-34 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 EPSABlock-10 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-97 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-35 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-25 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-98 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-99 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-100 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-101 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-13 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-102 [[1, 64, 1, 1]] [1, 4, 1, 1] 260 ReLU-24 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-103 [[1, 4, 1, 1]] [1, 64, 1, 1] 320 Sigmoid-13 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-13 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-13 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-13 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-36 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 Conv2D-104 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-37 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 EPSABlock-11 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-105 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-38 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-27 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-106 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-107 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-108 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-109 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-14 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-110 [[1, 64, 1, 1]] [1, 4, 1, 1] 260 ReLU-26 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-111 [[1, 4, 1, 1]] [1, 64, 1, 1] 320 Sigmoid-14 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-14 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-14 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-14 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-39 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 Conv2D-112 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-40 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 EPSABlock-12 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-113 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-41 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-29 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-114 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-115 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-116 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-117 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-15 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-118 [[1, 64, 1, 1]] [1, 4, 1, 1] 260 ReLU-28 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-119 [[1, 4, 1, 1]] [1, 64, 1, 1] 320 Sigmoid-15 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-15 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-15 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-15 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-42 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 Conv2D-120 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-43 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 EPSABlock-13 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-122 [[1, 1024, 14, 14]] [1, 512, 14, 14] 524,288 BatchNorm2D-45 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048 ReLU-31 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 Conv2D-123 [[1, 512, 14, 14]] [1, 128, 7, 7] 589,824 Conv2D-124 [[1, 512, 14, 14]] [1, 128, 7, 7] 409,600 Conv2D-125 [[1, 512, 14, 14]] [1, 128, 7, 7] 401,408 Conv2D-126 [[1, 512, 14, 14]] [1, 128, 7, 7] 331,776 AdaptiveAvgPool2D-16 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Conv2D-127 [[1, 128, 1, 1]] [1, 8, 1, 1] 1,032 ReLU-30 [[1, 8, 1, 1]] [1, 8, 1, 1] 0 Conv2D-128 [[1, 8, 1, 1]] [1, 128, 1, 1] 1,152 Sigmoid-16 [[1, 128, 1, 1]] [1, 128, 1, 1] 0 SEWeightModule-16 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Softmax-16 [[1, 4, 128, 1, 1]] [1, 4, 128, 1, 1] 0 PSAModule-16 [[1, 512, 14, 14]] [1, 512, 7, 7] 0 BatchNorm2D-46 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 Conv2D-129 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576 BatchNorm2D-47 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 Conv2D-121 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 2,097,152 BatchNorm2D-44 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 EPSABlock-14 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 0 Conv2D-130 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576 BatchNorm2D-48 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-33 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 Conv2D-131 [[1, 512, 7, 7]] [1, 128, 7, 7] 589,824 Conv2D-132 [[1, 512, 7, 7]] [1, 128, 7, 7] 409,600 Conv2D-133 [[1, 512, 7, 7]] [1, 128, 7, 7] 401,408 Conv2D-134 [[1, 512, 7, 7]] [1, 128, 7, 7] 331,776 AdaptiveAvgPool2D-17 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Conv2D-135 [[1, 128, 1, 1]] [1, 8, 1, 1] 1,032 ReLU-32 [[1, 8, 1, 1]] [1, 8, 1, 1] 0 Conv2D-136 [[1, 8, 1, 1]] [1, 128, 1, 1] 1,152 Sigmoid-17 [[1, 128, 1, 1]] [1, 128, 1, 1] 0 SEWeightModule-17 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Softmax-17 [[1, 4, 128, 1, 1]] [1, 4, 128, 1, 1] 0 PSAModule-17 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 BatchNorm2D-49 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 Conv2D-137 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576 BatchNorm2D-50 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 EPSABlock-15 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 Conv2D-138 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576 BatchNorm2D-51 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-35 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 Conv2D-139 [[1, 512, 7, 7]] [1, 128, 7, 7] 589,824 Conv2D-140 [[1, 512, 7, 7]] [1, 128, 7, 7] 409,600 Conv2D-141 [[1, 512, 7, 7]] [1, 128, 7, 7] 401,408 Conv2D-142 [[1, 512, 7, 7]] [1, 128, 7, 7] 331,776 AdaptiveAvgPool2D-18 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Conv2D-143 [[1, 128, 1, 1]] [1, 8, 1, 1] 1,032 ReLU-34 [[1, 8, 1, 1]] [1, 8, 1, 1] 0 Conv2D-144 [[1, 8, 1, 1]] [1, 128, 1, 1] 1,152 Sigmoid-18 [[1, 128, 1, 1]] [1, 128, 1, 1] 0 SEWeightModule-18 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Softmax-18 [[1, 4, 128, 1, 1]] [1, 4, 128, 1, 1] 0 PSAModule-18 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 BatchNorm2D-52 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 Conv2D-145 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576 BatchNorm2D-53 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 EPSABlock-16 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 AdaptiveAvgPool2D-19 [[1, 2048, 7, 7]] [1, 2048, 1, 1] 0 Linear-1 [[1, 2048]] [1, 1000] 2,049,000 ================================================================================Total params: 22,614,835Trainable params: 22,508,595Non-trainable params: 106,240--------------------------------------------------------------------------------Input size (MB): 0.57Forward/backward pass size (MB): 272.07Params size (MB): 86.27Estimated Total Size (MB): 358.91--------------------------------------------------------------------------------登录后复制
{'total_params': 22614835, 'trainable_params': 22508595}登录后复制在Cifar10数据集上进行对比
如下图所示,我们对比EPSANet-50和Paddle最新ResNet-50,看看他们谁的性能更好
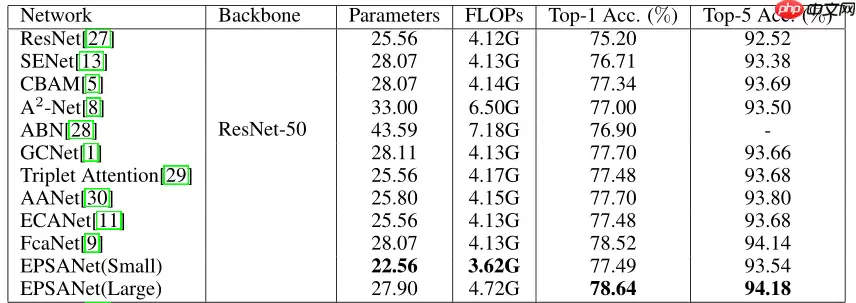
数据准备
In [7]import paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10paddle.set_device('gpu')#数据准备transform = T.Compose([ T.Resize(size=(224,224)), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],data_format='HWC'), T.ToTensor()])train_dataset = Cifar10(mode='train', transform=transform)val_dataset = Cifar10(mode='test', transform=transform)登录后复制Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz Begin to downloadDownload finished登录后复制
模型准备
In [8]# ResNet-50 vs EPSANet-50resnet50=paddle.Model(paddle.vision.models.resnet50(num_classes=10))epsanet50=paddle.Model(epsanet50(num_classes=10))登录后复制
开始训练
In [9]# ResNet-50resnet50.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001, parameters=resnet50.parameters()), loss=paddle.nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy())visualdl=paddle.callbacks.VisualDL(log_dir='resnet50_log') # 开启训练可视化resnet50.fit( train_data=train_dataset, eval_data=val_dataset, batch_size=64, epochs=10, verbose=1, callbacks=[visualdl] )登录后复制In [10]
# EPSANet-50epsanet50.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001, parameters=epsanet50.parameters()), loss=paddle.nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy())visualdl=paddle.callbacks.VisualDL(log_dir='epsanet50_log') # 开启训练可视化epsanet50.fit( train_data=train_dataset, eval_data=val_dataset, batch_size=64, epochs=10, verbose=1, callbacks=[visualdl] )登录后复制
训练可视化
训练集上性能对比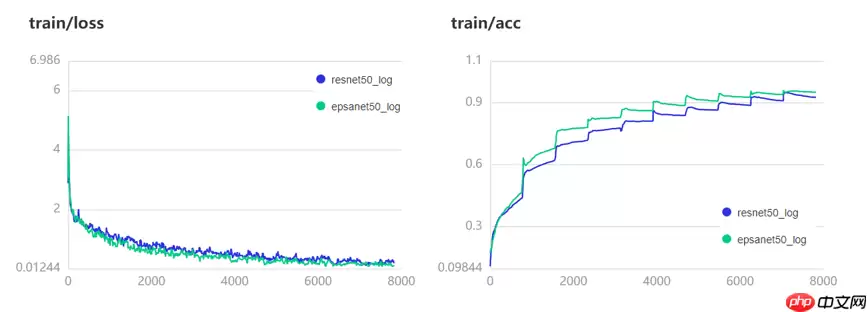
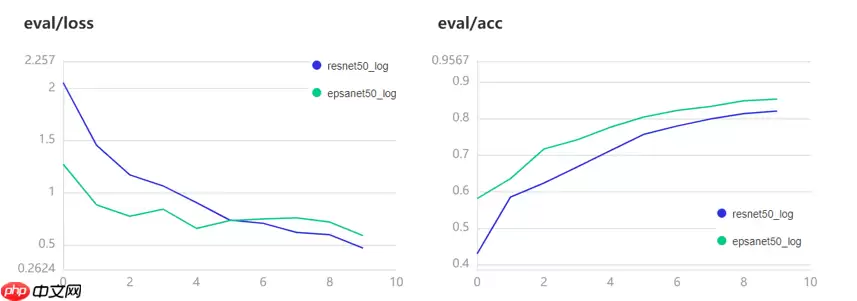
总结
PSA注意力模块实现了最好的性能,超越了当前其它注意力模块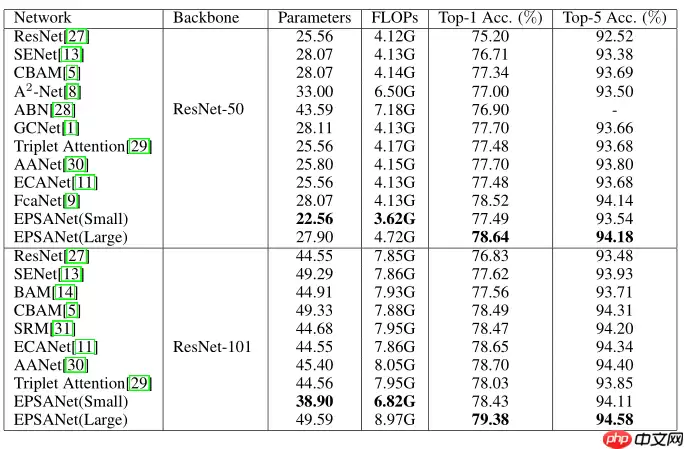
相关攻略

Pywinrm 通过Windows远程管理(WinRM)协议,让Python能够像操作本地一样执行远程Windows命令,真正打通了跨平台管理的最后一公里。 在混合IT环境中,Linux机器管理Wi

早些时候,聊过 Python 领域那场惊心动魄的供应链攻击。当时我就感叹,虽然我们 JavaScript 开发者对这类套路烂熟于心,但亲眼目睹这种规模的“投毒”还是头一次。 早些时候,聊过 Pyth

Toga 是 BeeWare 家族的核心成员,号称“写一次,跑遍所有平台”,而且用的是系统原生控件,不是那种一看就是网页套壳的界面 。 写了这么多年 Python,你是不是也想过:要是能一套代码跑

异常处理的核心:让错误在正确的地方被有效处理。正确的地方,就是别在底层就把异常吞了,也别在顶层还抛裸奔的 Exception。 异常处理写得好,半夜不用起来改 bug。1 你是不是也这么干过?tr

1 Skills机制概述 提起OpenClaw的Skills机制,不少人可能会把它想象成传统意义上的可执行插件。其实,它的内涵要更精妙一些。 简单说,Skills本质上是一套基于提示驱动的能力扩展机制。它并不是一个可以独立“跑”起来的程序模块,而是通过一份结构化描述文件(核心就是那个SKILL m
热门专题







热门推荐

加密货币行业翘首以盼的监管里程碑,终于有了实质性进展。美国证券交易委员会(SEC)主席保罗·阿特金斯(Paul Atkins)近日证实,那份允许加密项目在早期获得注册豁免权的“安全港”框架提案,已经正式送抵白宫,进入了最终审查阶段。 在范德堡大学与区块链协会联合举办的数字资产峰会上,阿特金斯透露了这

微策略Strategy报告:第一季录得144 6亿美元浮亏 再斥资约3 3亿美元买进4871枚比特币 市场震荡的威力有多大?看看Strategy的最新季报就明白了。根据其最新向美国证管会(SEC)提交的8-K报告,受市场剧烈波动影响,这家公司所持的比特币在第一季度录得了一笔惊人的数字——144 6亿

稳定币巨头Tether的动向,向来是加密世界的风向标。这不,它向Web3基础设施的版图扩张,又迈出了关键一步。公司执行长Paolo Ardoino在社交平台X上透露,其工程团队正在全力“烹制”一个新项目——去中心化搜索引擎 “Hypersearch”。这个消息一出,立刻引发了行业的广泛猜想。 采用D

基地位于Coinbase旗下以太坊Layer2网络Base的Seamless Protocol,日前正式宣告了服务的终结。这个曾经吸引了超过20万用户的原生DeFi借贷协议,在运营不到三年后,终究没能跑赢时间。它主打的核心产品是Integrated Leverage Markets(ILMs)——一

PAAL代币揭秘:深度解析Web3社区治理的核心钥匙 在去中心化自治组织的浪潮中,谁真正掌握了项目的话语权?PAAL代币提供了一套系统化的答案。它不仅是生态内流转的价值媒介,更是开启链上治理大门的核心凭证。通过持有并质押PAAL代币,用户能够对协议升级、资金分配乃至战略方向等关键事务投出决定性的一票