基于PaddlePaddle搭建儿童X光胸部肺炎分类项目
该项目基于ResNet50网络对儿童胸片进行肺炎和正常二分类。先解压数据并生成训练、验证、测试列表,创建数据集并可视化。修改网络以获取最后卷积层输出用于类激活图。用Paddle高层API训练,评估得测试集准确率96.39%,并绘制混淆矩阵、ROC曲线(Normal AUC和Pneumonia AUC)及类激活图展示模型效果。

背景
这个项目是一个典型二分类任务,只是一个和医疗有关的项目。是基于resenet50网络进行分类。 这个项目增加训练完成后一些指标计算和展示,例如ACC,混淆矩阵,AUC,类激活图等(类激活图是参考大佬FutureSI的项目)
解压数据,生成数据列表
这个数据是一个公开数据,每张图片都是儿童的胸片。里面有两个类别一个是肺炎,一个正常的胸片。
In [ ]!unzip -o data/data103760/data.zip -d /home/aistudio/work登录后复制In [80]
label = {'pneumonia_':1,'normal_':0}import osfrom PIL import Imageimport randomrandom.seed(2024)dataset_path = '/home/aistudio/work/data'trainf = open(os.path.join(dataset_path, 'train_list.txt'), 'w')valf = open(os.path.join(dataset_path, 'val_list.txt'), 'w')testf = open(os.path.join(dataset_path, 'test_list.txt'), 'w')for key,value in label.items(): img_dir = os.path.join(dataset_path, key) imgs_name = os.listdir(img_dir) random.shuffle(imgs_name) for idx, name in enumerate(imgs_name): img_path = os.path.join(img_dir, name) if idx % 10 == 0: valf.write((img_path + ' ' + str(value) + '\n')) elif idx % 9 == 0: testf.write((img_path + ' ' + str(value) + '\n')) else: trainf.write((img_path + ' ' + str(value) + '\n'))trainf.close()valf.close()testf.close()print('finished!')登录后复制finished!登录后复制
创建Dataset 并可视化数据
In [81]from paddle.vision.transforms import Compose,Transpose, BrightnessTransform,Resize,Normalize,RandomHorizontalFlip,RandomRotation,ContrastTransform,RandomCropfrom paddle.io import DataLoader, Datasetimport cv2import numpy as nptrain_transform = Compose([RandomRotation(degrees=10),#随机旋转0到10度 RandomHorizontalFlip(),#随机翻转 ContrastTransform(0.1),#随机调整图片的对比度 BrightnessTransform(0.1),#随机调整图片的亮度 Resize(size=(240,240)),#调整图片大小为240,240 RandomCrop(size=(224,224)),#从240大小中随机裁剪出224 Normalize(mean=[127.5, 127.5, 127.5],std=[127.5, 127.5, 127.5],data_format='HWC'),#归一化 Transpose()])#对‘HWC’转换成‘CHW’val_transform = Compose([ Resize(size=(224,224)), Normalize(mean=[127.5, 127.5, 127.5],std=[127.5, 127.5, 127.5],data_format='HWC'), Transpose()])# 定义DataSetclass XChestDateset(Dataset): def __init__(self, txt_path, transform=None,mode='train'): super(XChestDateset, self).__init__() self.mode = mode self.data_list = [] self.transform = transform if mode == 'train': self.data_list = np.loadtxt(txt_path, dtype='str') elif mode == 'valid': self.data_list = np.loadtxt(txt_path, dtype='str') elif mode == 'test': self.data_list = np.loadtxt(txt_path, dtype='str') def __getitem__(self, idx): img_path = self.data_list[idx][0] img = cv2.imread(img_path) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) if self.transform: img = self.transform(img) return img, int(self.data_list[idx][1]) def __len__(self): return self.data_list.shape[0]train_txt = 'work/data/train_list.txt'val_txt = 'work/data/val_list.txt'BATCH_SIZE = 16trn_dateset = XChestDateset(train_txt,train_transform, 'train')train_loader = DataLoader(trn_dateset, shuffle=True, batch_size=BATCH_SIZE )val_dateset = XChestDateset(val_txt, val_transform,'valid')valid_loader = DataLoader(val_dateset, shuffle=False, batch_size=BATCH_SIZE)登录后复制In [82]
#可视化经过 数据增强后的胸片import matplotlib.pyplot as plt def imshow(img): img = np.transpose(img, (1,2,0)) img = img*127.5 + 127.5 #反归一化,还原图片 img = img.astype(np.int32) plt.imshow(img)dataiter = iter(train_loader)images, labels = dataiter.next()num = images.shape[0]row = 4fig = plt.figure(figsize=(14,14))for idx in range(num): ax = fig.add_subplot(row,int(num/row), idx+1, xticks=[], yticks=[]) imshow(images[idx]) if labels[idx]: ax.set_title('pneumonia') else: ax.set_title('normal')登录后复制登录后复制登录后复制
创建RestNet50 网络
这个restNet50 网络代码是飞桨最新教程提供的代码
但是要最后生成类激活图就要稍微修改代码。
根据大佬FutureSI提到Grad-CAM 梯度加权的类激活热图原理中,需要获取网络最后一个卷积层输出的特征图,然后计算它的梯度。所以网络设计的时候需要提供一个方法,用来获取最后一个卷积层的输出
代码修改部分如下:
""" 以全局池化层为界,self.conv_layer用来存放所有卷积层。self.last_layer 用来全局池化层后面的全连接层 """ self.conv_layer = nn.Sequential(self.conv, self.pool2d_max,*self.bottleneck_block_list) last_layer = [ paddle.nn.AdaptiveAvgPool2D(output_size=1), nn.Flatten(1, -1), nn.Linear(in_features=2048, out_features=class_dim), ] self.last_layer = nn.Sequential(*last_layer) """ 这是原来的代码,用以上的代码代替。其实就是单纯组合了一下,没有增加新的层 """ # 在c5的输出特征图上使用全局池化 # self.pool2d_avg = paddle.nn.AdaptiveAvgPool2D(output_size=1) # 创建全连接层,输出大小为类别数目,经过残差网络的卷积和全局池化后, # 卷积特征的维度是[B,2048,1,1],故最后一层全连接的输入维度是2048 # self.out = nn.Linear(in_features=2048, out_features=class_dim) def forward(self, inputs): # y = self.conv(inputs) # y = self.pool2d_max(y) # for bottleneck_block in self.bottleneck_block_list: # y = bottleneck_block(y) # y = self.pool2d_avg(y) # y = paddle.reshape(y, [y.shape[0], -1]) # y = self.out(y) """ 上面是原来的代码,用下面的两行代替(就是上面的代码组装起来而已。。。) """ conv = self.conv_layer(inputs) y = self.last_layer(conv) return y登录后复制In [83]
# -*- coding:utf-8 -*-# ResNet模型代码import numpy as npimport paddleimport paddle.nn as nnimport paddle.nn.functional as F# ResNet中使用了BatchNorm层,在卷积层的后面加上BatchNorm以提升数值稳定性# 定义卷积批归一化块class ConvBNLayer(paddle.nn.Layer): def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act=None): """ num_channels, 卷积层的输入通道数 num_filters, 卷积层的输出通道数 stride, 卷积层的步幅 groups, 分组卷积的组数,默认groups=1不使用分组卷积 """ super(ConvBNLayer, self).__init__() # 创建卷积层 self._conv = nn.Conv2D( in_channels=num_channels, out_channels=num_filters, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, groups=groups, bias_attr=False) # 创建BatchNorm层 self._batch_norm = paddle.nn.BatchNorm2D(num_filters) self.act = act def forward(self, inputs): y = self._conv(inputs) y = self._batch_norm(y) if self.act == 'leaky': y = F.leaky_relu(x=y, negative_slope=0.1) elif self.act == 'relu': y = F.relu(x=y) return y# 定义残差块# 每个残差块会对输入图片做三次卷积,然后跟输入图片进行短接# 如果残差块中第三次卷积输出特征图的形状与输入不一致,则对输入图片做1x1卷积,将其输出形状调整成一致class BottleneckBlock(paddle.nn.Layer): def __init__(self, num_channels, num_filters, stride, shortcut=True): super(BottleneckBlock, self).__init__() # 创建第一个卷积层 1x1 self.conv0 = ConvBNLayer( num_channels=num_channels, num_filters=num_filters, filter_size=1, act='relu') # 创建第二个卷积层 3x3 self.conv1 = ConvBNLayer( num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=stride, act='relu') # 创建第三个卷积 1x1,但输出通道数乘以4 self.conv2 = ConvBNLayer( num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None) # 如果conv2的输出跟此残差块的输入数据形状一致,则shortcut=True # 否则shortcut = False,添加1个1x1的卷积作用在输入数据上,使其形状变成跟conv2一致 if not shortcut: self.short = ConvBNLayer( num_channels=num_channels, num_filters=num_filters * 4, filter_size=1, stride=stride) self.shortcut = shortcut self._num_channels_out = num_filters * 4 def forward(self, inputs): y = self.conv0(inputs) conv1 = self.conv1(y) conv2 = self.conv2(conv1) # 如果shortcut=True,直接将inputs跟conv2的输出相加 # 否则需要对inputs进行一次卷积,将形状调整成跟conv2输出一致 if self.shortcut: short = inputs else: short = self.short(inputs) y = paddle.add(x=short, y=conv2) y = F.relu(y) return y# 定义ResNet模型class ResNet(paddle.nn.Layer): def __init__(self, layers=50, class_dim=2): """ layers, 网络层数,可以是50, 101或者152 class_dim,分类标签的类别数 """ super(ResNet, self).__init__() self.layers = layers supported_layers = [50, 101, 152] assert layers in supported_layers, \ "supported layers are {} but input layer is {}".format(supported_layers, layers) if layers == 50: #ResNet50包含多个模块,其中第2到第5个模块分别包含3、4、6、3个残差块 depth = [3, 4, 6, 3] elif layers == 101: #ResNet101包含多个模块,其中第2到第5个模块分别包含3、4、23、3个残差块 depth = [3, 4, 23, 3] elif layers == 152: #ResNet152包含多个模块,其中第2到第5个模块分别包含3、8、36、3个残差块 depth = [3, 8, 36, 3] # 残差块中使用到的卷积的输出通道数 num_filters = [64, 128, 256, 512] # ResNet的第一个模块,包含1个7x7卷积,后面跟着1个最大池化层 self.conv = ConvBNLayer( num_channels=3, num_filters=64, filter_size=7, stride=2, act='relu') self.pool2d_max = nn.MaxPool2D( kernel_size=3, stride=2, padding=1) # ResNet的第二到第五个模块c2、c3、c4、c5 self.bottleneck_block_list = [] num_channels = 64 for block in range(len(depth)): shortcut = False for i in range(depth[block]): bottleneck_block = self.add_sublayer( 'bb_%d_%d' % (block, i), BottleneckBlock( num_channels=num_channels, num_filters=num_filters[block], stride=2 if i == 0 and block != 0 else 1, # c3、c4、c5将会在第一个残差块使用stride=2;其余所有残差块stride=1 shortcut=shortcut)) num_channels = bottleneck_block._num_channels_out self.bottleneck_block_list.append(bottleneck_block) shortcut = True """ 以全局池化层为界,self.conv_layer用来存放所有卷积层。self.last_layer 用来全局池化层后面的全连接层 """ self.conv_layer = nn.Sequential(self.conv, self.pool2d_max,*self.bottleneck_block_list) last_layer = [ paddle.nn.AdaptiveAvgPool2D(output_size=1), nn.Flatten(1, -1), nn.Linear(in_features=2048, out_features=class_dim), ] self.last_layer = nn.Sequential(*last_layer) """ 这是原来的代码,用以上的代码代替。其实就是单纯组合了一下,没有增加新的层 """ # 在c5的输出特征图上使用全局池化 # self.pool2d_avg = paddle.nn.AdaptiveAvgPool2D(output_size=1) # 创建全连接层,输出大小为类别数目,经过残差网络的卷积和全局池化后, # 卷积特征的维度是[B,2048,1,1],故最后一层全连接的输入维度是2048 # self.out = nn.Linear(in_features=2048, out_features=class_dim) def forward(self, inputs): # y = self.conv(inputs) # y = self.pool2d_max(y) # for bottleneck_block in self.bottleneck_block_list: # y = bottleneck_block(y) # y = self.pool2d_avg(y) # y = paddle.reshape(y, [y.shape[0], -1]) # y = self.out(y) """ 上面是原来的代码,用下面的两行代替(就是上面的代码组装起来而已。。。) """ conv = self.conv_layer(inputs) y = self.last_layer(conv) return y登录后复制使用Paddle 高层API 进行网络训练
In [84]from paddle.regularizer import L2Decayfrom paddle.nn import CrossEntropyLossfrom paddle.metric import AccuracyBATCH_SIZE = 16 EPOCHS = 30 #训练次数decay_steps = int(len(trn_dateset)/BATCH_SIZE * EPOCHS)train_loader = DataLoader(trn_dateset, shuffle=True, batch_size=BATCH_SIZE )valid_loader = DataLoader(val_dateset, shuffle=False, batch_size=BATCH_SIZE)model = paddle.Model(ResNet( class_dim=2))base_lr = 0.0125lr = paddle.optimizer.lr.PolynomialDecay(base_lr, power=0.9, decay_steps=decay_steps, end_lr=0.0)# 定义优化器optimizer = paddle.optimizer.Momentum(learning_rate=lr, momentum=0.9, weight_decay=L2Decay(1e-4), parameters=model.parameters())# 进行训练前准备model.prepare(optimizer, CrossEntropyLoss(), Accuracy(topk=(1, 5)))# 启动训练model.fit(train_loader, valid_loader, epochs=EPOCHS, batch_size=BATCH_SIZE, eval_freq =5,#多少epoch 进行验证 save_freq = 5,#多少epoch 进行模型保存 log_freq =30,#多少steps 打印训练信息 save_dir='/home/aistudio/checkpoint')登录后复制In [85]
#对验证集进行验证,查看验证集得分model.evaluate(valid_loader, log_freq=30, verbose=2)登录后复制
Eval begin...step 30/32 - loss: 0.1032 - acc_top1: 0.9563 - acc_top5: 1.0000 - 64ms/stepstep 32/32 - loss: 0.8956 - acc_top1: 0.9559 - acc_top5: 1.0000 - 63ms/stepEval samples: 499登录后复制
{'loss': [0.8956491], 'acc_top1': 0.9559118236472945, 'acc_top5': 1.0}登录后复制对测试集进行预测,计算准确率等指标并绘制混淆矩阵和ROC曲线
In [ ]import cv2from PIL import Imageimport matplotlib.pyplot as pltimport numpy as npfrom sklearn.preprocessing import label_binarizeimport paddlefrom sklearn.metrics import accuracy_score,recall_score,precision_score,f1_score,confusion_matrixmodel_path = 'checkpoint/final.pdparams'model = ResNet( class_dim=2)para_state_dict = paddle.load(model_path)model.set_dict(para_state_dict)model.eval()test_txt = 'work/data/test_list.txt'test_dataset = XChestDateset(test_txt,val_transform, 'test')test_loader = DataLoader(test_dataset, shuffle=True, batch_size=1 )dataiter = iter(test_loader)y_score = list()pre_label = list()true_label = list()for images, labels in dataiter: true_label.append(labels.numpy()[0]) out = model(images) y_score.append(out.numpy()[0]) out = np.argmax(out.numpy()) pre_label.append(out)登录后复制In [ ]
#绘制混淆矩阵from sklearn.metrics import confusion_matrixfrom sklearn.metrics import classification_reportimport seaborn as snsconfusion = confusion_matrix(true_label, pre_label)#计算混淆矩阵plt.figure(figsize=(7,7))sns.heatmap(confusion,cmap='Blues_r',annot=True,fmt='.20g',annot_kws={'size':20,'weight':'bold', })#绘制混淆矩阵plt.xlabel('Predict')plt.ylabel('True')plt.show()print("混淆矩阵为:\n{}".format(confusion))print("\n计算各项指标:")print(classification_report(true_label, pre_label,digits=4))登录后复制/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/seaborn/matrix.py:69: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations mask = np.zeros(data.shape, np.bool)/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/seaborn/matrix.py:79: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations dtype=np.bool)/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:101: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead ret = np.asscalar(ex)登录后复制
登录后复制
混淆矩阵为:[[124 11] [ 7 356]]计算各项指标: precision recall f1-score support 0 0.9466 0.9185 0.9323 135 1 0.9700 0.9807 0.9753 363 accuracy 0.9639 498 macro avg 0.9583 0.9496 0.9538 498weighted avg 0.9637 0.9639 0.9637 498登录后复制In [ ]
#绘制ROC曲线from sklearn.metrics import roc_curve, roc_auc_score,aucplt.figure(figsize=(8,8))kind = {"normal":0,'pneumonia':1}y_score = np.array(y_score)fpr , tpr ,threshold = roc_curve(true_label, y_score[:,kind['normal']], pos_label=kind['normal'])roc_auc = auc(fpr,tpr) ###计算auc的fpr1 , tpr1 ,threshold = roc_curve(true_label, y_score[:,kind['pneumonia']], pos_label=kind['pneumonia'])roc_auc1 = auc(fpr1,tpr1) ###计算auc的plt.plot(fpr, tpr,marker='o', markersize=5,label='Normal')plt.plot(fpr1, tpr1,marker='*', markersize=5,label='Pneumonia')plt.title("Normal AUC:{:.4f}, Pneumonia AUC:{:.4f}".format( roc_auc,roc_auc1))plt.xlabel('FPR')plt.ylabel('TPR')plt.legend(loc=4)plt.show()登录后复制登录后复制
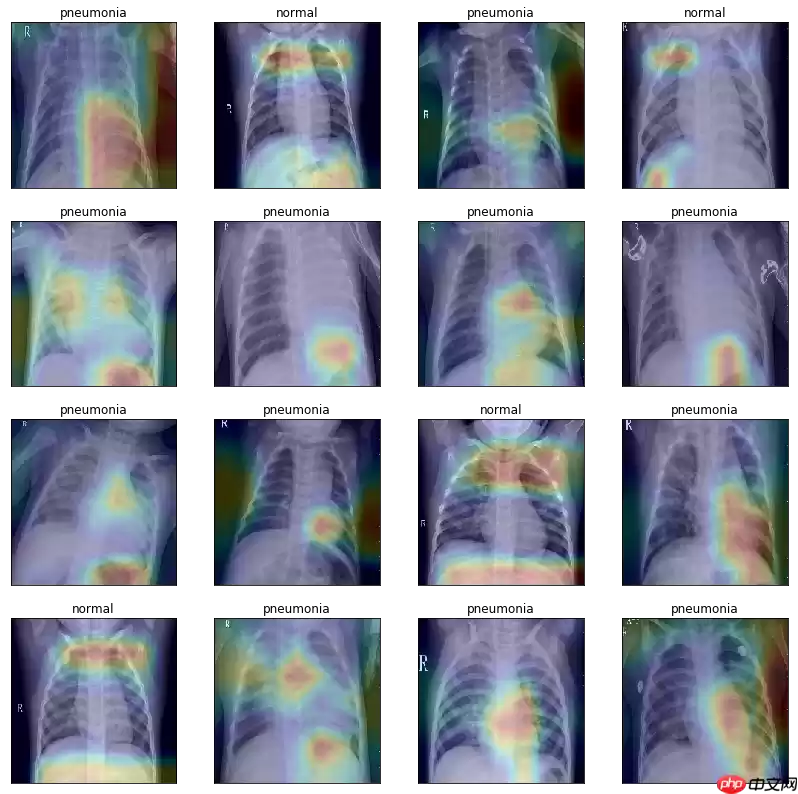
绘制类激活图,可视化模型效果
In [86]# 获取 Grad-CAM 类激活热图def get_gradcam(model, data, label, class_dim=2): conv = model.conv_layer(data) # 得到模型最后一个卷积层的特征图 predict = model.last_layer(conv) # 得到前向计算的结果 label = paddle.reshape(label, [-1]) predict_one_hot = paddle.nn.functional.one_hot(label, class_dim) * predict # 将模型输出转化为one-hot向量 score = paddle.mean(predict_one_hot) # 得到预测结果中概率最高的那个分类的值 score.backward() # 反向传播计算梯度 grad_map = conv.grad # 得到目标类别的loss对最后一个卷积层输出的特征图的梯度 grad = paddle.mean(paddle.to_tensor(grad_map), (2, 3), keepdim=True) # 对特征图的梯度进行GAP(全局平局池化) gradcam = paddle.sum(grad * conv, axis=1) # 将最后一个卷积层输出的特征图乘上从梯度求得权重进行各个通道的加和 gradcam = paddle.maximum(gradcam, paddle.to_tensor(0.)) # 进行ReLU操作,小于0的值设为0 for j in range(gradcam.shape[0]): gradcam[j] = gradcam[j] / paddle.max(gradcam[j]) # 分别归一化至[0, 1] return gradcam# 将 Grad-CAM 叠加在原图片上显示激活热图的效果def show_gradcam(model, data, label, class_dim=2, pic_size=224): gradcams = get_gradcam(model, data, label,class_dim=class_dim) for i in range(data.shape[0]): img = (data[i].numpy() *127.5 +127.5).astype('uint8').transpose([1, 2, 0]) # 归一化至[0,255]区间,形状:[h,w,c] heatmap = cv2.resize(gradcams[i].numpy() * 255., (data.shape[2], data.shape[3])).astype('uint8') # 调整热图尺寸与图片一致、归一化 heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET) # 将热图转化为“伪彩热图”显示模式 superimposed_img = cv2.addWeighted(heatmap, .2, img, .8, 1.) # 将特图叠加到原图片上 return superimposed_imgmodel_path = 'checkpoint/final.pdparams'model = ResNet( class_dim=2)para_state_dict = paddle.load(model_path)model.set_dict(para_state_dict)model.eval()test_txt = 'work/data/test_list.txt'test_dataset = XChestDateset(test_txt,val_transform, 'test')test_loader = DataLoader(test_dataset, shuffle=True, batch_size=16 )dataiter = iter(test_loader)images, labels = dataiter.next()num = images.shape[0]row = 4fig = plt.figure(figsize=(14,14))for idx in range(num): ax = fig.add_subplot(row,int(num/row), idx+1, xticks=[], yticks=[]) image = paddle.unsqueeze(images[idx], axis=0) heat_map = show_gradcam(model, image, labels[idx], class_dim=2) heat_map = cv2.cvtColor(heat_map, cv2.COLOR_BGR2RGB) plt.imshow(heat_map) if labels[idx]: ax.set_title('pneumonia') else: ax.set_title('normal')登录后复制/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/varbase_patch_methods.py:373: UserWarning: Warning:tensor.grad will return the tensor value of the gradient. warnings.warn(warning_msg)登录后复制
登录后复制登录后复制
相关攻略

零基础学习Python可从安装环境开始。前往官网下载最新稳定版,安装时勾选添加PATH选项。验证安装后,创建 py文件并写入print()函数输出文本。通过命令行运行文件,观察输出结果。理解代码按顺序执行,注意括号与引号的正确使用。初期不必死记语法,通过修改代码并运行来建立动手反馈的实践感。

Trae的AI功能深度适配FastAPI与Flask框架。针对FastAPI,它能精准识别异步架构与类型注解,提供模型定义、路由补全及异步数据库建议;在Flask中,则侧重理解装饰器链、请求上下文与ORM操作,辅助完成权限控制与数据库提交等典型模式。此外,Trae具备跨框架语义索引能力,可感知项目结构、依赖变更与工具函数调用,提升开发效率。

Trae在Python数据分析与机器学习项目中主要通过四种方式提供支持:利用Auto模式自动生成并执行端到端分析脚本;通过AgentCLI命令行自动化机器学习建模流程;对现有代码进行智能调试与优化;借助语音交互快速构建数据处理函数。这些功能覆盖了从需求描述到代码生成、模型构建及代码优化的全流程。

在Python编程中,你是否也曾编写过类似的统计代码? 统计词频 count = {} for word in words: if word in count: count[word] += 1 else: count[word] = 1 实际上,这种高频的计数需求,完全可以通过Python内置

Trae稳定支持Python3 10至3 13版本,3 9及以下版本无法运行。Python3 14处于实验性支持阶段,核心功能可能受限。当存在多个3 10以上版本时,Trae优先选择虚拟环境中的解释器,其次为最高系统版本。此外,Trae仅兼容64位Python解释器,不支持32位架构。
热门专题







热门推荐

公安部就电子数据取证规则公开征求意见,拟将网络安全等行政案件纳入适用范围,并规范取证流程与核心概念。新规特别明确了获取密码、调取通讯内容等特殊程序,需经严格审批并保障当事人权利。配套法律文书也同步优化,以构建更规范且注重权利保障的取证体系。

理想L9和LIvis的定价策略刚掀起波澜,小鹏GX的最终价格就给出了更猛烈的回应——从近40万元的预售价直降至27万元起。用小鹏产品矩阵负责人吴安飞的话说,这叫“9系的产品,8系的价格”。 这12万元的下调,效果堪称立竿见影。发布会次日,小鹏集团港股股价一度大涨超8%。更关键的是市场订单:上市12小

5月21日,环塔拉力赛新疆且末赛段大营迎来了一位备受瞩目的访客——知名零售企业胖东来的创始人于东来。他专程前往长城汽车车队营地,与参赛车手及后勤团队进行了深度交流。据悉,于东来此次自驾越野之旅已历时一月,随行车队中包含多款国产越野车型。经过实地驾驶与多维度对比,他对以长城汽车为代表的国产越野车品质给

比特币官方入口在哪里?一个核心门户的权威指南 说起比特币,很多人第一反应是去找它的“官网”或“官方App”。但这里有个关键点需要先理清:比特币本质上是一种去中心化的全球数字货币,它不属于任何一家公司或机构,而是由一个庞大的、遍布全球的社区共同维护。因此,它并没有传统意义上由某个企业运营的“官方网站”

Ring-2 5-1T是什么 在当今大模型技术激烈竞争的赛道上,追求更长的上下文处理能力和更强大的深度推理性能已成为核心焦点。近日,蚂蚁集团旗下的inclusionAI团队重磅开源了Ring-2 5-1T模型,这是一个参数规模高达万亿级别的混合线性思考大语言模型。该模型基于先进的Ling 2 5架构