用PaddleClas完成不平衡数据集多标签分类
本项目针对不平衡自然场景图片数据集的多标签分类任务,解决了数据分布不平衡及类标签依赖的难题。使用PaddleClas套件,通过过采样处理数据不平衡,用powerlabel区分多标签组合,基于MobileNetV1模型,采用带pos_weight参数的binary cross entropy with logits loss函数,最终在验证集上精度达0.94200。

前言
此项目的任务是不平衡数据集的多标签分类任务。该任务的难点如下:
在数据分布不平衡时其往往会导致分类器的输出倾向于在数据集中占多数的类别:输出多数类会带来更高的分类准确率,但在我们所关注的少数类中表现不佳。
类标签数量不确定,类标签之间相互依赖。这导致其比单分类任务更加复杂
在此项目中,我们成功解决了以上的难题,在不平衡的自然场景图片数据集上完成了多标签图片的分类任务。
In [ ]本项目中,数据集已包含在项目文件中,如需重新下载,请前往此地址。
本项目需要安装PaddleClas套件,运行下面两条指令即可完成安装。
!git clone https://gitee.com/paddlepaddle/PaddleClas.git -b release/2.3登录后复制 In [ ]
!cd PaddleClas/&&pip install --upgrade -r requirements.txt -i https://mirror.baidu.com/pypi/simple登录后复制
PaddleClas介绍
飞桨图像识别套件PaddleClas是飞桨为工业界和学术界所准备的一个图像识别任务的工具集,助力使用者训练出更好的视觉模型和应用落地。其拥有以下特性:
PP-ShiTu轻量图像识别系统:集成了目标检测、特征学习、图像检索等模块,广泛适用于各类图像识别任务。cpu上0.2s即可完成在10w+库的图像识别。
PP-LCNet轻量级CPU骨干网络:专门为CPU设备打造轻量级骨干网络,速度、精度均远超竞品。
丰富的预训练模型库:提供了36个系列共175个ImageNet预训练模型,其中7个精选系列模型支持结构快速修改。
全面易用的特征学习组件:集成arcmargin, triplet loss等12度量学习方法,通过配置文件即可随意组合切换。
SSLD知识蒸馏:14个分类预训练模型,精度普遍提升3%以上;其中ResNet50_vd模型在ImageNet-1k数据集上的Top-1精度达到了84.0%, Res2Net200_vd预训练模型Top-1精度高达85.1%。
在我们的任务中我们需要使用PaddleClas的多标签分类 quick start。quick start使用了binary cross entropy with logits loss 损失函数,其默认使用MobileNetV1模型。
数据集介绍
本项目中的数据集由 2000 张图片组成,图像为自然场景图片,下面为图片样例。




数据集共有5个类标签分别是沙漠(desert)、山脉(mountains)、海洋(sea)、日落(sunset)和树木(trees),不同的类标签组成一个标签组。
因为数据集中图片有可能属于多个类别,所以每一张图片被人为的分配一个标签组用以表示其所属类别,下表给出不同标签组与其图像数量的详细描述。
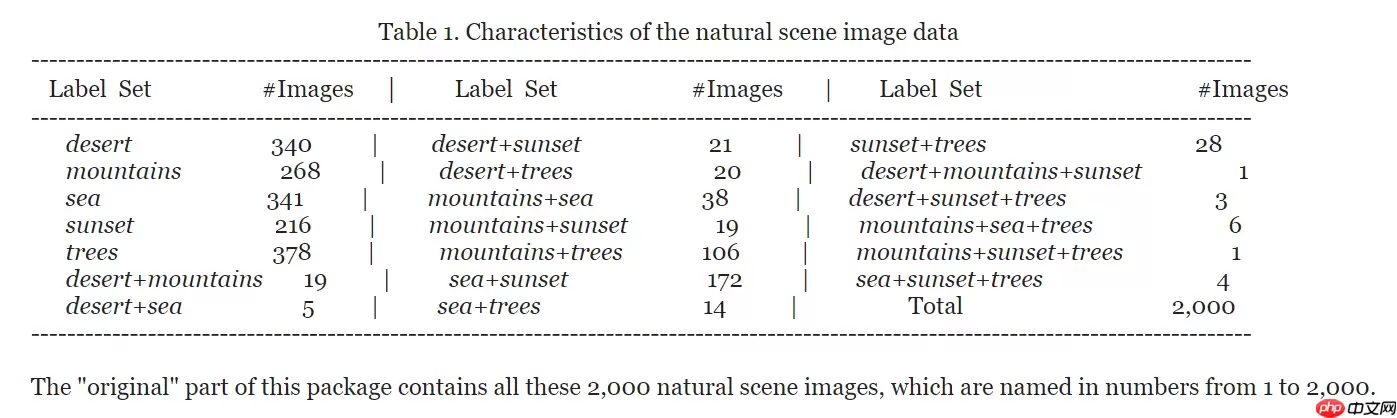
其中属于一个以上类别(例如sea+sunset)的图像数量占数据集的 22% 以上,而许多组合类别(例如mountain+sunset +trees)极为罕见,平均而言,每张图像与 1.24 个类别标签相关联。
综上所述,我们能发现我们的数据集为不平衡数据集,所以我们在项目中需要解决的一个重要问题就是数据集的不平衡问题。
数据集的准备与处理
下载好的数据集我们先将它解压,以下为解压相关命令:
In [5]#解压miml-image-data.rar文件!rar x miml-image-data.rar#解压original.rar文件!rar x original.rar#解压processed.rar文件!rar x processed.rar#将解压后图片放到指定文件夹里!mkdir original&&mv /home/aistudio/*.webp /home/aistudio/original登录后复制
执行以上命令过后我们得到一个包含标签信息的mat文件(miml data.mat)和一个包含图片的文件夹(original)。
其中图片以数字编号命名,文件miml data.mat中的targets表包含了每张图片对应的标签组信息,如下表所示。
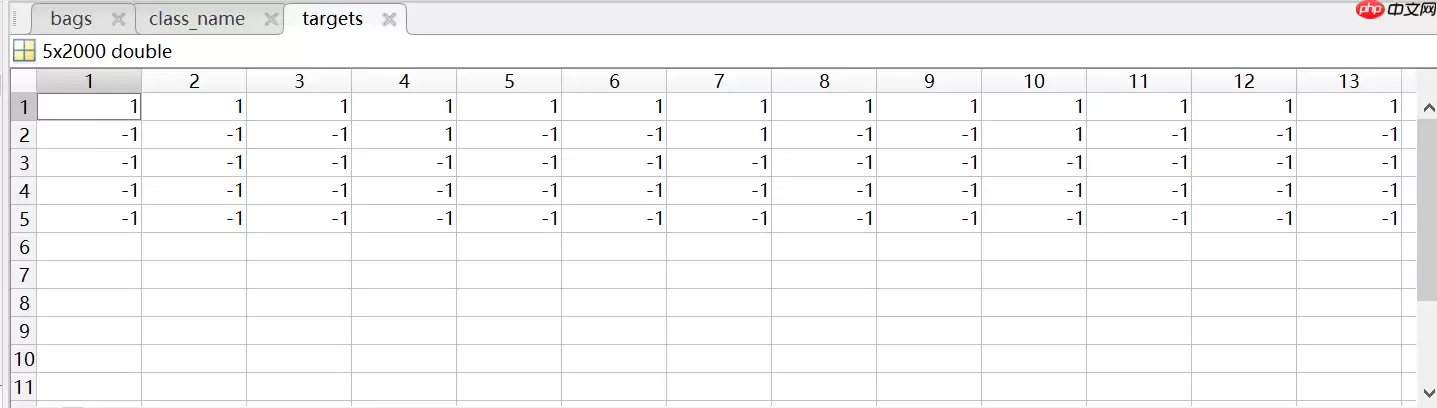
targets表中的列标对应每张图的编号名称,行标对应每个类标签的编号。表中每一列都记录了对应图片的标签组信息,其中“1”表示是,“-1”表示否,
例如:图片类别为mountain+sunset+trees,在表中对应的列从上往下记录为-1,1,-1,1,1。
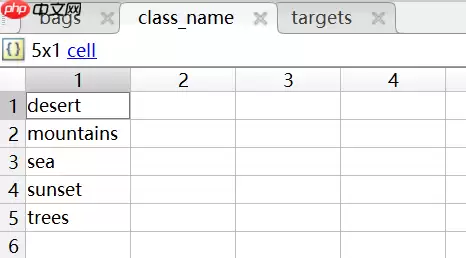
类标签与其对应的编号信息记录在class_name表中,如下表所示,其行标为编号,表中的内容为对应的图片。
下面我们将targets表和class_name表以及图片的名称整合到一张DataFrame类型的表中。
为了适应后面PaddleClas中MobileNetV1模型的图片标签输入格式,我们将targets表中的“-1”将转为“0”代表,其代码如下:
In [6]import osimport scipy.io as scioimport pandas as pdimport copyimport waveimport numpy as npimport matplotlib.pyplot as pltproc_mat=scio.loadmat("/home/aistudio/miml data.mat")#读取文件miml data.matclass_names=[]for c in proc_mat['class_name']:#从class_name表中读取类别名称 class_names.append(c[0][0])labels=copy.deepcopy(proc_mat['targets'].T)#从targets表中读取标签组labels[labels==-1]=0data_df=pd.DataFrame(columns=["filenames"]+class_names)#设置DataFrame表的列标filenames=os.listdir("/home/aistudio/original")#读取图片编号data_df["filenames"]=np.array(sorted(list(map(lambda x:int(x[:-4]),np.array(filenames)))))#将图片编号输入到DataFrame表中的filenames一列data_df['filenames']=data_df['filenames'].apply(lambda x:str(x)+'.webp')#完善filenames一列图片名称data_df[class_names]=np.array(labels)#将对应标签组信息输入到DataFrame表中print(data_df)#输出DataFrame表,表中每行代表一张图的名称和其对应的标签登录后复制 filenames desert mountains sea sunset trees0 1.webp 1 0 0 0 01 2.webp 1 0 0 0 02 3.webp 1 0 0 0 03 4.webp 1 1 0 0 04 5.webp 1 0 0 0 0... ... ... ... .. ... ...1995 1996.webp 0 0 0 0 11996 1997.webp 0 0 0 0 11997 1998.webp 0 0 0 0 11998 1999.webp 0 0 0 0 11999 2000.webp 0 0 0 0 1[2000 rows x 6 columns]登录后复制
然后我们算出每个标签组的powerlabel标签来代表每张图片的类别,
例如 : 一张sea+sunset类别的图片,那么其标签组现在为0,0,1,1,0,我们将其从右往左按二进制转换成十进制得到6,那么这个6就可以代表sea+sunset类,我们将这个6记作该图片的powerlabel。
这样我们就能用一个数字区分图片类别而不是一个标签组,这方便我们进一步进行数据处理。
我们在DataFrame表中再添一powerlabel列用来记录图片相应的powerlabel标签,代码如下所示:
In [7]data_df['powerlabel']=data_df.apply(lambda x:16*x["desert"]+8*x['mountains']+4*x['sea']+2*x["sunset"]+1*x['trees'],axis=1)print(data_df)登录后复制
filenames desert mountains sea sunset trees powerlabel0 1.webp 1 0 0 0 0 161 2.webp 1 0 0 0 0 162 3.webp 1 0 0 0 0 163 4.webp 1 1 0 0 0 244 5.webp 1 0 0 0 0 16... ... ... ... .. ... ... ...1995 1996.webp 0 0 0 0 1 11996 1997.webp 0 0 0 0 1 11997 1998.webp 0 0 0 0 1 11998 1999.webp 0 0 0 0 1 11999 2000.webp 0 0 0 0 1 1[2000 rows x 7 columns]登录后复制
现在我们画出每个类别图片数量的统计表,运行下面代码可画出统计表。
从表中可见数据很不平衡,所以我们需要对数据集进行过采样。所谓过采样就是当数据量不足时,通过增大稀有样本的大小来达到平衡。经过过采样我们就能解决数据集不平衡的问题。
In [10]data_df['powerlabel'].hist(bins=np.unique(data_df['powerlabel']))登录后复制
登录后复制
登录后复制
在进行过采样之前,我们需要对数据集划分为训练集和验证集,因为验证集不需要进行过采样。下面代码对数据集按照3:1的比例进行了划分,其中随机种子固定为2024:
In [11]from sklearn.model_selection import train_test_splitdf_train,df_test = train_test_split(data_df,test_size = 0.25,random_state=2024)#划分数据集print(df_train)print(df_test)登录后复制
filenames desert mountains sea sunset trees powerlabel1138 1139.webp 0 0 1 0 0 4863 864.webp 0 0 1 0 0 41956 1957.webp 0 0 0 0 1 1900 901.webp 0 0 1 0 0 41063 1064.webp 0 0 1 0 0 4... ... ... ... .. ... ... ...1713 1714.webp 0 0 0 0 1 1624 625.webp 0 1 1 0 1 13173 174.webp 1 0 0 0 0 161244 1245.webp 0 0 1 1 0 6893 894.webp 0 1 1 0 0 12[1500 rows x 7 columns] filenames desert mountains sea sunset trees powerlabel1018 1019.webp 0 0 1 0 0 41295 1296.webp 0 0 0 1 1 3643 644.webp 0 1 0 0 1 91842 1843.webp 0 0 0 0 1 11669 1670.webp 0 0 0 0 1 1... ... ... ... .. ... ... ...1420 1421.webp 0 0 1 1 0 61785 1786.webp 0 0 0 0 1 1366 367.webp 1 0 0 0 0 161732 1733.webp 0 0 0 0 1 11874 1875.webp 0 0 0 0 1 1[500 rows x 7 columns]登录后复制
数据集划分完成后,我们对训练集进行过采样,代码如下:
In [12]def over_sampling(df_data,index='oversample'):#定义过采样函数,第一个参数传入数据的DataFrame表。第二个参数传入'oversample'表示进行过采样,传入'None'不进行过采样。 powerlabels=np.unique(df_data['powerlabel'])#读取图片类别 powercount={} for p in powerlabels: powercount[p]=np.count_nonzero(df_data['powerlabel']==p)#记录每类图片和其对应的数量到字典中 maxcount=np.max(list(powercount.values()))#获取字数量最多的图片的数量记为maxcount for p in powerlabels: if index=='oversample':#如果需要过采样,获取每类图片的数量与maxcount值的差值 gapnum=maxcount-powercount[p] elif index=='None':#如果不需要过采样,差值设为0 gapnum=0 temp_df=df_data.iloc[np.random.choice(np.where(df_data['powerlabel']==p)[0],size=gapnum)]#按照差值,获取需要增加的图片信息 df_data=df_data.append(temp_df,ignore_index=True)#将获取到的图片信息增加到DataFrame表中,并对DataFrame表的编号进行更新,让其从0开始编号 return df_datadf_train=over_sampling(df_train)#对训练集进行过采样df_test=over_sampling(df_test,'None')#对验证集不进行过采样,但对其DataFrame表的行标进行更新,让其从0开始编号。如果不进行这一步会影响接下来的处理。 print(df_train)print(df_test)登录后复制 filenames desert mountains sea sunset trees powerlabel0 1139.webp 0 0 1 0 0 41 864.webp 0 0 1 0 0 42 1957.webp 0 0 0 0 1 13 901.webp 0 0 1 0 0 44 1064.webp 0 0 1 0 0 4... ... ... ... .. ... ... ...5675 120.webp 1 1 0 1 0 265676 120.webp 1 1 0 1 0 265677 120.webp 1 1 0 1 0 265678 120.webp 1 1 0 1 0 265679 120.webp 1 1 0 1 0 26[5680 rows x 7 columns] filenames desert mountains sea sunset trees powerlabel0 1019.webp 0 0 1 0 0 41 1296.webp 0 0 0 1 1 32 644.webp 0 1 0 0 1 93 1843.webp 0 0 0 0 1 14 1670.webp 0 0 0 0 1 1.. ... ... ... .. ... ... ...495 1421.webp 0 0 1 1 0 6496 1786.webp 0 0 0 0 1 1497 367.webp 1 0 0 0 0 16498 1733.webp 0 0 0 0 1 1499 1875.webp 0 0 0 0 1 1[500 rows x 7 columns]登录后复制
接下来我们将验证集和过采样之后的训练集中的图片名称和标签组保存到txt文件中供PaddleClas读取数据集使用。
我们按文件名+空格+标签组的格式将每张图片的信息按行存入txt文件中(其中标签组中每个类标签用','隔开),
例如:(1019.webp 0,0,1,0,0)。
该过程代码如下:
In [13]def save_txt(df_data,file_path):#定义存储函数,第一个参数传入数据的DataFrame表,第二个参数为存储的目标文件名 list1=df_data['filenames']#获取DataFrame表中的'filenames','desert','mountains','sea','sunset','trees'五列信息 list2=df_data['desert'] list3=df_data['mountains'] list4=df_data['sea'] list5=df_data['sunset'] list6=df_data['trees'] listall=[] for i in range(0,len(list1)): listall.append(list1[i]+" "+str(list2[i])+","+str(list3[i])+","+str(list4[i])+","+str(list5[i])+","+str(list6[i]))#将获取到的五列信息整合到一张listall列表中 with open(file_path,"w",encoding='utf-8') as file: for i in listall: file.write(i+'\n')#把listall列表中的信息保存到目标txt文件中 file.close()save_txt(df_test,file_path="/home/aistudio/PaddleClas/dataset/test_list.txt")#将验证集信息保存到目标文件save_txt(df_train,file_path="/home/aistudio/PaddleClas/dataset/train_list.txt")#将训练集信息保存到目标文件df_train.to_csv('data_list.csv', index=False)#将训练集信息保存到为csv文件登录后复制 处理完数据集后,我们需要算出binary cross entropy with logits loss损失函数的pos_weight参数。
pos_weight会对我们的多标签分类任务起到帮助计算pos_weight的代码如下:
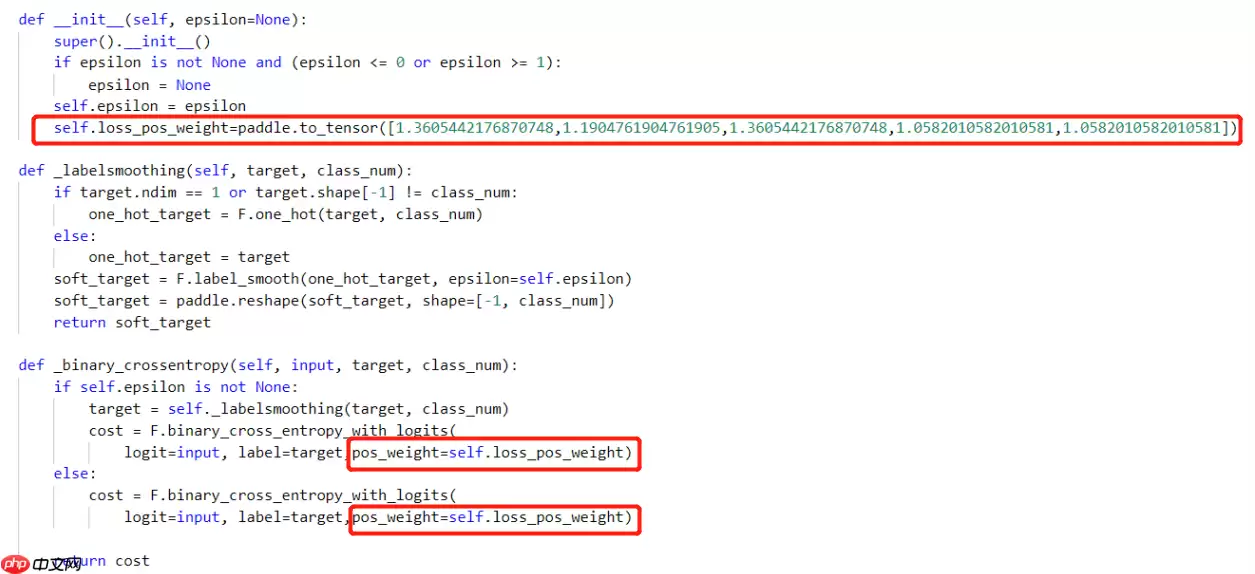
In [14]import pandas as pdimport numpy as npdata_df = pd.read_csv('/home/aistudio/data_list.csv')#读取刚才保存的csv文件class_names = ['desert','mountains','sea','sunset','trees']pos_weight = {}for c in class_names: pos_weight[c] = data_df.shape[0]/(2.1*np.count_nonzero(data_df[c]==1))#计算pos_weightprint(pos_weight)登录后复制 {'desert': 1.3605442176870748, 'mountains': 1.1904761904761905, 'sea': 1.3605442176870748, 'sunset': 1.0582010582010581, 'trees': 1.0582010582010581}登录后复制 使用Paddleclass构建任务
对于多标签分类任务我们使用Paddleclass的PaddleClas的多标签分类 quick start。首先我们打开文件MobileNetV1_multilabel.yaml。
文件路径为:/home/aistudio/PaddleClas/ppcls/configs/quickstart/professional/MobileNetV1multilabel.yaml
打开文件我们可以看到我们选用的模型为MobileNetV1,该网络 是 Google 于 2017 年发布的用于移动设备或嵌入式设备中的网络。
其将传统的卷积操作替换深度可分离卷积,即 Depthwise 卷积和 Pointwise 卷积的组合,相比传统的卷积操作,该组合可以大大节省参数量和计算量。
因为我们有5个类标签,所以我们将class_num改为5,如下图所示:

然后再在此文件中修改训练集的读取路径,如下图所示:
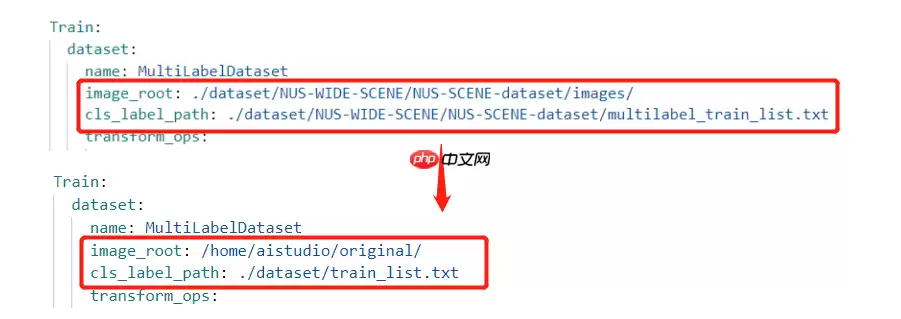
再修改验证集的读取路径,如下图所示:
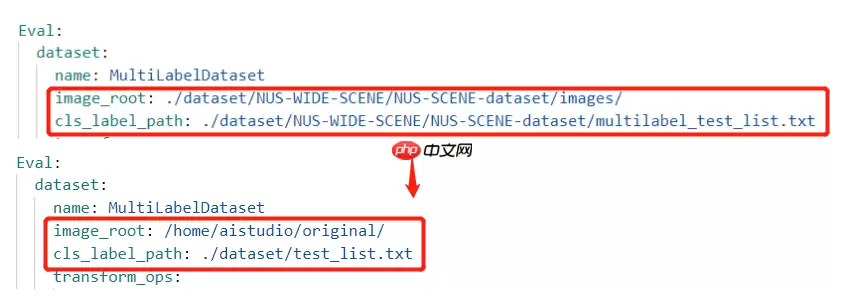
然后我们打开数据集读取的源文件multilabel_dataset.py
文件路径为:/home/aistudio/PaddleClas/ppcls/data/dataloader/multilabeldataset.py
因为我们的train_list和test_list文件中文件名与标签组用空格隔开,所以我们需要将源码进行修改,修改如下图所示:
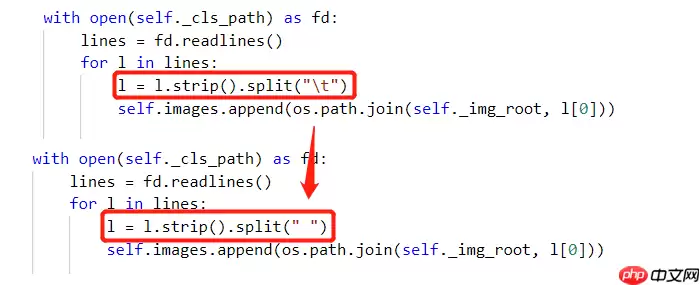
接着我们要对损失函数进行修改,将我们刚算出的pos_weight传入binary cross entropy with logits loss损失函数中。
我们先打开文件multilabelloss.py。
文件路径为:/home/aistudio/PaddleClas/ppcls/loss/multilabelloss.py
然后我们在此文件里添加下图所示内容。
用PaddleClas进行训练
首先在终端输入以下命令进入 PaddleClas文件夹。
cd PaddleClas
然后输入以下命令开始训练,这里我们用四卡训练。
export CUDA_VISIBLE_DEVICES=0,1,2,3python3 -m paddle.distributed.launch \ --gpus="0,1,2,3" \ tools/train.py \ -c ./ppcls/configs/quick_start/professional/MobileNetV1_multilabel.yaml登录后复制
下面是我们的训练时的界面:
训练结束后在验证集上的精度最高达到了0.94200
总结
一开始对于不平衡数据集的多标签分类任务我们选择的是自己搭模型,但是在实际的搭建过程中出现了很多没有想到的麻烦。
之后,百度的导师指导我们可以用PaddleClas做。然后我们开始了解PaddleClas这个套件,我们惊喜的发现PaddleClas 是一个超强的图像分类任务的工具集。
它集模型开发、训练、压缩、部署全流程于一体。在我们的项目中,它给我们提供了多标签分类quick,使得我们省去了很多麻烦,仅仅需要处理数据集和修改少量文件就能快速的构建我们的任务。
所以,我们希望读者可以尝试用PaddleClas来做图片分类任务,下面是PaddleClas相关链接地址:
PaddleClas github地址:https://github.com/PaddlePaddle/PaddleClas/
PaddleClas教程文档地址:https://paddleclas.readthedocs.io/zh_CN/latest/index.html
除此之外,我们也希望读者能学习到下面几个点:
用过采样方法处理数据集不平衡问题。
用powerlabel来对多标签图片进行分类。
用binary cross entropy with logits loss损失函数和pos_weight参数来计算损失。
相关攻略

零基础学习Python可从安装环境开始。前往官网下载最新稳定版,安装时勾选添加PATH选项。验证安装后,创建 py文件并写入print()函数输出文本。通过命令行运行文件,观察输出结果。理解代码按顺序执行,注意括号与引号的正确使用。初期不必死记语法,通过修改代码并运行来建立动手反馈的实践感。

Trae的AI功能深度适配FastAPI与Flask框架。针对FastAPI,它能精准识别异步架构与类型注解,提供模型定义、路由补全及异步数据库建议;在Flask中,则侧重理解装饰器链、请求上下文与ORM操作,辅助完成权限控制与数据库提交等典型模式。此外,Trae具备跨框架语义索引能力,可感知项目结构、依赖变更与工具函数调用,提升开发效率。

Trae在Python数据分析与机器学习项目中主要通过四种方式提供支持:利用Auto模式自动生成并执行端到端分析脚本;通过AgentCLI命令行自动化机器学习建模流程;对现有代码进行智能调试与优化;借助语音交互快速构建数据处理函数。这些功能覆盖了从需求描述到代码生成、模型构建及代码优化的全流程。

在Python编程中,你是否也曾编写过类似的统计代码? 统计词频 count = {} for word in words: if word in count: count[word] += 1 else: count[word] = 1 实际上,这种高频的计数需求,完全可以通过Python内置

Trae稳定支持Python3 10至3 13版本,3 9及以下版本无法运行。Python3 14处于实验性支持阶段,核心功能可能受限。当存在多个3 10以上版本时,Trae优先选择虚拟环境中的解释器,其次为最高系统版本。此外,Trae仅兼容64位Python解释器,不支持32位架构。
热门专题







热门推荐

公安部就电子数据取证规则公开征求意见,拟将网络安全等行政案件纳入适用范围,并规范取证流程与核心概念。新规特别明确了获取密码、调取通讯内容等特殊程序,需经严格审批并保障当事人权利。配套法律文书也同步优化,以构建更规范且注重权利保障的取证体系。

理想L9和LIvis的定价策略刚掀起波澜,小鹏GX的最终价格就给出了更猛烈的回应——从近40万元的预售价直降至27万元起。用小鹏产品矩阵负责人吴安飞的话说,这叫“9系的产品,8系的价格”。 这12万元的下调,效果堪称立竿见影。发布会次日,小鹏集团港股股价一度大涨超8%。更关键的是市场订单:上市12小

5月21日,环塔拉力赛新疆且末赛段大营迎来了一位备受瞩目的访客——知名零售企业胖东来的创始人于东来。他专程前往长城汽车车队营地,与参赛车手及后勤团队进行了深度交流。据悉,于东来此次自驾越野之旅已历时一月,随行车队中包含多款国产越野车型。经过实地驾驶与多维度对比,他对以长城汽车为代表的国产越野车品质给

比特币官方入口在哪里?一个核心门户的权威指南 说起比特币,很多人第一反应是去找它的“官网”或“官方App”。但这里有个关键点需要先理清:比特币本质上是一种去中心化的全球数字货币,它不属于任何一家公司或机构,而是由一个庞大的、遍布全球的社区共同维护。因此,它并没有传统意义上由某个企业运营的“官方网站”

Ring-2 5-1T是什么 在当今大模型技术激烈竞争的赛道上,追求更长的上下文处理能力和更强大的深度推理性能已成为核心焦点。近日,蚂蚁集团旗下的inclusionAI团队重磅开源了Ring-2 5-1T模型,这是一个参数规模高达万亿级别的混合线性思考大语言模型。该模型基于先进的Ling 2 5架构