【Paddle-CLIP】使用 CLIP 模型进行图像识别
引入
上回介绍了如何搭建模型并加载参数进行模型测试本次就详细介绍一下 CLIP 模型的各种使用CLIP 模型的用途
可通过模型将文本和图像进行编码
然后通过计算相似度得出文本与图像之间的关联程度
模型大致的架构图如下:
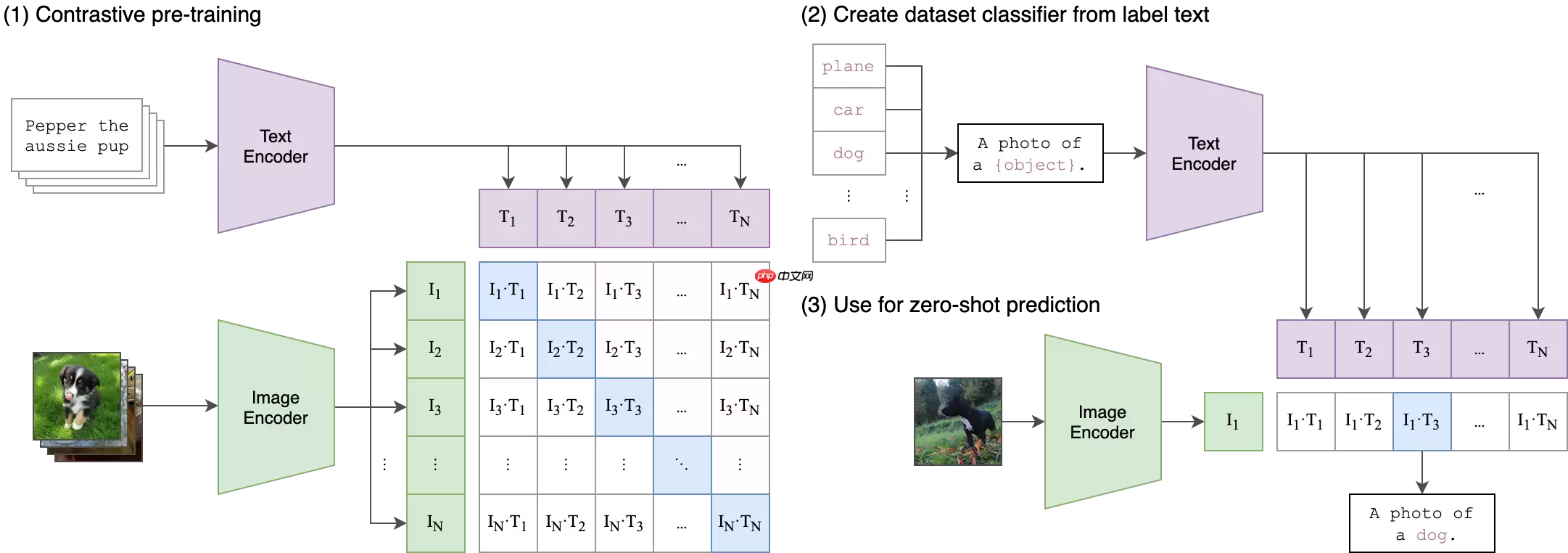
项目说明
项目 GitHub:【Paddle-CLIP】有关模型的相关细节,请看上一个项目:【Paddle2.0:复现 OpenAI CLIP 模型】安装 Paddle-CLIP
In [ ]!pip install paddleclip登录后复制
加载模型
首次加载会自动下载预训练模型,请耐心等待In [ ]import paddlefrom PIL import Imagefrom clip import tokenize, load_modelmodel, transforms = load_model('ViT_B_32', pretrained=True)登录后复制 图像识别
使用预训练模型输出各种候选标签的概率In [ ]# 设置图片路径和标签img_path = "apple.webp"labels = ['apple', 'fruit', 'pear', 'peach']# 准备输入数据img = Image.open(img_path)display(img)image = transforms(Image.open(img_path)).unsqueeze(0)text = tokenize(labels)# 计算特征with paddle.no_grad(): logits_per_image, logits_per_text = model(image, text) probs = paddle.nn.functional.softmax(logits_per_image, axis=-1)# 打印结果for label, prob in zip(labels, probs.squeeze()): print('该图片为 %s 的概率是:%.02f%%' % (label, prob*100.))登录后复制 登录后复制
该图片为 apple 的概率是:83.19%该图片为 fruit 的概率是:1.25%该图片为 pear 的概率是:6.71%该图片为 peach 的概率是:8.84%登录后复制 In [ ]
# 设置图片路径和标签img_path = "fruit.webp"labels = ['apple', 'fruit', 'pear', 'peach']# 准备输入数据img = Image.open(img_path)display(img)image = transforms(Image.open(img_path)).unsqueeze(0)text = tokenize(labels)# 计算特征with paddle.no_grad(): logits_per_image, logits_per_text = model(image, text) probs = paddle.nn.functional.softmax(logits_per_image, axis=-1)# 打印结果for label, prob in zip(labels, probs.squeeze()): print('该图片为 %s 的概率是:%.02f%%' % (label, prob*100.))登录后复制 登录后复制
该图片为 apple 的概率是:8.52%该图片为 fruit 的概率是:90.30%该图片为 pear 的概率是:0.98%该图片为 peach 的概率是:0.21%登录后复制
Zero-Shot
使用 Cifar100 的测试集测试零次学习In [1]import paddlefrom clip import tokenize, load_modelfrom paddle.vision.datasets import Cifar100# 加载模型model, transforms = load_model('ViT_B_32', pretrained=True)# 加载 Cifar100 数据集cifar100 = Cifar100(mode='test', backend='pil')classes = [ 'apple', 'aquarium_fish', 'baby', 'bear', 'beaver', 'bed', 'bee', 'beetle', 'bicycle', 'bottle', 'bowl', 'boy', 'bridge', 'bus', 'butterfly', 'camel', 'can', 'castle', 'caterpillar', 'cattle', 'chair', 'chimpanzee', 'clock', 'cloud', 'cockroach', 'couch', 'crab', 'crocodile', 'cup', 'dinosaur', 'dolphin', 'elephant', 'flatfish', 'forest', 'fox', 'girl', 'hamster', 'house', 'kangaroo', 'keyboard', 'lamp', 'lawn_mower', 'leopard', 'lion', 'lizard', 'lobster', 'man', 'maple_tree', 'motorcycle', 'mountain', 'mouse', 'mushroom', 'oak_tree', 'orange', 'orchid', 'otter', 'palm_tree', 'pear', 'pickup_truck', 'pine_tree', 'plain', 'plate', 'poppy', 'porcupine', 'possum', 'rabbit', 'raccoon', 'ray', 'road', 'rocket', 'rose', 'sea', 'seal', 'shark', 'shrew', 'skunk', 'skyscraper', 'snail', 'snake', 'spider', 'squirrel', 'streetcar', 'sunflower', 'sweet_pepper', 'table', 'tank', 'telephone', 'television', 'tiger', 'tractor', 'train', 'trout', 'tulip', 'turtle', 'wardrobe', 'whale', 'willow_tree', 'wolf', 'woman', 'worm']# 准备输入数据image, class_id = cifar100[3637]display(image)image_input = transforms(image).unsqueeze(0)text_inputs = tokenize(["a photo of a %s" % c for c in classes])# 计算特征with paddle.no_grad(): image_features = model.encode_image(image_input) text_features = model.encode_text(text_inputs)# 筛选 Top_5image_features /= image_features.norm(axis=-1, keepdim=True)text_features /= text_features.norm(axis=-1, keepdim=True)similarity = (100.0 * image_features @ text_features.t())similarity = paddle.nn.functional.softmax(similarity, axis=-1)values, indices = similarity[0].topk(5)# 打印结果for value, index in zip(values, indices): print('该图片为 %s 的概率是:%.02f%%' % (classes[index], value*100.))登录后复制 Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-100-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-100-python.tar.gz Begin to downloadDownload finished登录后复制
登录后复制
该图片为 snake 的概率是:65.31%该图片为 turtle 的概率是:12.29%该图片为 sweet_pepper 的概率是:3.83%该图片为 lizard 的概率是:1.88%该图片为 crocodile 的概率是:1.75%登录后复制
逻辑回归
使用模型的图像编码和标签进行逻辑回归训练使用的数据集依然是 Cifar100In [ ]import osimport paddleimport numpy as npfrom tqdm import tqdmfrom paddle.io import DataLoaderfrom clip import tokenize, load_modelfrom paddle.vision.datasets import Cifar100from sklearn.linear_model import LogisticRegression# 加载模型model, transforms = load_model('ViT_B_32', pretrained=True)# 加载数据集train = Cifar100(mode='train', transform=transforms, backend='pil')test = Cifar100(mode='test', transform=transforms, backend='pil')# 获取特征def get_features(dataset): all_features = [] all_labels = [] with paddle.no_grad(): for images, labels in tqdm(DataLoader(dataset, batch_size=100)): features = model.encode_image(images) all_features.append(features) all_labels.append(labels) return paddle.concat(all_features).numpy(), paddle.concat(all_labels).numpy()# 计算并获取特征train_features, train_labels = get_features(train)test_features, test_labels = get_features(test)# 逻辑回归classifier = LogisticRegression(random_state=0, C=0.316, max_iter=1000, verbose=1, n_jobs=-1)classifier.fit(train_features, train_labels)# 模型评估predictions = classifier.predict(test_features)accuracy = np.mean((test_labels == predictions).astype(np.float)) * 100.# 打印结果print(f"Accuracy = {accuracy:.3f}")登录后复制 /home/aistudio/Paddle-CLIPAccuracy = 79.900登录后复制
相关攻略

零基础学习Python可从安装环境开始。前往官网下载最新稳定版,安装时勾选添加PATH选项。验证安装后,创建 py文件并写入print()函数输出文本。通过命令行运行文件,观察输出结果。理解代码按顺序执行,注意括号与引号的正确使用。初期不必死记语法,通过修改代码并运行来建立动手反馈的实践感。

Trae的AI功能深度适配FastAPI与Flask框架。针对FastAPI,它能精准识别异步架构与类型注解,提供模型定义、路由补全及异步数据库建议;在Flask中,则侧重理解装饰器链、请求上下文与ORM操作,辅助完成权限控制与数据库提交等典型模式。此外,Trae具备跨框架语义索引能力,可感知项目结构、依赖变更与工具函数调用,提升开发效率。

Trae在Python数据分析与机器学习项目中主要通过四种方式提供支持:利用Auto模式自动生成并执行端到端分析脚本;通过AgentCLI命令行自动化机器学习建模流程;对现有代码进行智能调试与优化;借助语音交互快速构建数据处理函数。这些功能覆盖了从需求描述到代码生成、模型构建及代码优化的全流程。

在Python编程中,你是否也曾编写过类似的统计代码? 统计词频 count = {} for word in words: if word in count: count[word] += 1 else: count[word] = 1 实际上,这种高频的计数需求,完全可以通过Python内置

Trae稳定支持Python3 10至3 13版本,3 9及以下版本无法运行。Python3 14处于实验性支持阶段,核心功能可能受限。当存在多个3 10以上版本时,Trae优先选择虚拟环境中的解释器,其次为最高系统版本。此外,Trae仅兼容64位Python解释器,不支持32位架构。
热门专题







热门推荐

公安部就电子数据取证规则公开征求意见,拟将网络安全等行政案件纳入适用范围,并规范取证流程与核心概念。新规特别明确了获取密码、调取通讯内容等特殊程序,需经严格审批并保障当事人权利。配套法律文书也同步优化,以构建更规范且注重权利保障的取证体系。

理想L9和LIvis的定价策略刚掀起波澜,小鹏GX的最终价格就给出了更猛烈的回应——从近40万元的预售价直降至27万元起。用小鹏产品矩阵负责人吴安飞的话说,这叫“9系的产品,8系的价格”。 这12万元的下调,效果堪称立竿见影。发布会次日,小鹏集团港股股价一度大涨超8%。更关键的是市场订单:上市12小

5月21日,环塔拉力赛新疆且末赛段大营迎来了一位备受瞩目的访客——知名零售企业胖东来的创始人于东来。他专程前往长城汽车车队营地,与参赛车手及后勤团队进行了深度交流。据悉,于东来此次自驾越野之旅已历时一月,随行车队中包含多款国产越野车型。经过实地驾驶与多维度对比,他对以长城汽车为代表的国产越野车品质给

比特币官方入口在哪里?一个核心门户的权威指南 说起比特币,很多人第一反应是去找它的“官网”或“官方App”。但这里有个关键点需要先理清:比特币本质上是一种去中心化的全球数字货币,它不属于任何一家公司或机构,而是由一个庞大的、遍布全球的社区共同维护。因此,它并没有传统意义上由某个企业运营的“官方网站”

Ring-2 5-1T是什么 在当今大模型技术激烈竞争的赛道上,追求更长的上下文处理能力和更强大的深度推理性能已成为核心焦点。近日,蚂蚁集团旗下的inclusionAI团队重磅开源了Ring-2 5-1T模型,这是一个参数规模高达万亿级别的混合线性思考大语言模型。该模型基于先进的Ling 2 5架构