一文读懂图卷积神经网络(GCN)
本文围绕经典论文介绍GCN,解释其定义,即处理图结构数据的网络,输入为带特征的图,输出为节点特征。解析核心公式,通过添加自环、对称归一化邻接矩阵解决信息丢失和尺度问题,还提及在Cora数据集上的应用及数学证明参考。

GCN 学习
本文讲的GCN理论知识来源于论文:
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
这是在GCN领域最经典的论文之一
1. 什么是GCN
GCN结构图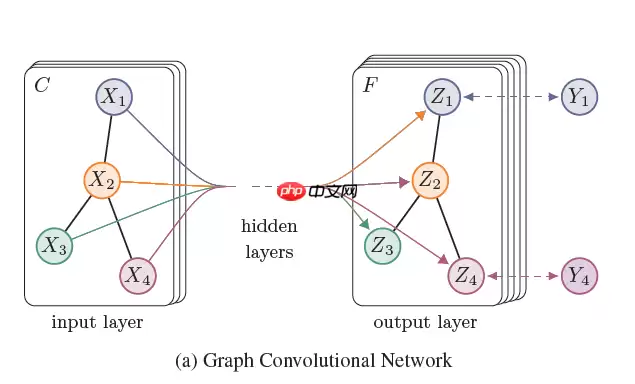
我们可以根据这个GCN的图看到,一个拥有 C 个input channel的graph作为输入,经过中间的hidden layers,得到 F 个 output channel的输出。
图卷积网络主要可以由两个级别的作用变换组成:
注意本文讲的图都特指无向无权重的图。
graph level:node level:例如说通过引入一些形式的pooling 操作. 然后改变图的结构。但是本次讲过GCN并没有进行这个级别的操作。所以看到上图我们的网络结构的输出和输出的graph的结构是一样的。
通常说node level的作用是不改变graph的结构的,仅通过对graph的特征/信号(特征信号 X 作为输入:一个 N∗D 矩阵( N: 输入图的nodes的个数, D 输入的特征维度) ,得到输出 Z:一个 N∗F 的矩阵( F 输出的特征维度)。
a) 一个特征描述(feature description) xi : 指的是每个节点 i 的特征表示
b) 每一个graph 的结构都可以通过邻接矩阵 A 表示(或者其他根据它推导的矩阵)
举例:
我们可以很容易的根据一个邻接矩阵重构出一个graph。 例如下图: G=(V,E) 其中 V 代表节点, E 代表边
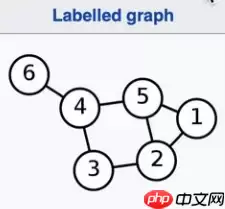
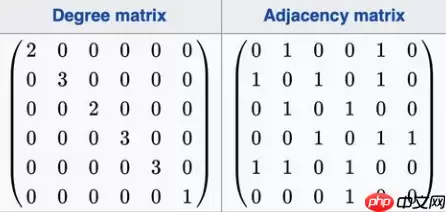
根据图,我们就可以得出下面的维度图和邻接矩阵
论文公式提出
因为 A 可以确定唯一的一张图,这么重要的一个属性我们肯定是要把他放到神经网络传递函数里面去的,所以网络中间的每一个隐藏层可以写成以下的非线性函数:
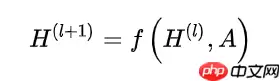
其中输入层 H(0)=X , 输出层 H(L)=Z , L 是层数。 不同的GCN模型,采用不同 f(⋅,⋅)函数。
上面是我们理想中的函数的形式,论文中最终推导出来的函数是这样的:


论文公式逐步解析
每一个节点下一层的信息是由前一层本身的信息以及相邻的节点的信息加权加和得到,然后再经过线性变换 W 以及非线性变换 σ() 。
我们一步一步分解,我们要定义一个简单的f(H(l),A) 函数,作为基础的网络层。
可以很容易的采用最简单的层级传导(layer-wise propagation)规则:
f(H(l),A)=σ(AH(l)W(l))
我们直接将 AH 做矩阵相乘,然后再通过一个权重矩阵 W(l)做线性变换,之后再经过非线性激活函数 σ(⋅) , 比如说 ReLU,最后得到下一层的输入 Hl+1 。
In [ ]import paddleA = paddle.to_tensor([ [0,1,0,0,1,0], [1,0,1,0,1,0], [0,1,0,1,0,0], [0,0,1,0,1,1], [1,1,0,1,0,0], [0,0,0,1,0,0]],dtype='float32')print(A)H_0 = paddle.to_tensor([[1],[2],[3],[4],[5],[6]],dtype='float32')print(H_0)x = paddle.matmul(A,H_0)print(x)登录后复制
Tensor(shape=[6, 6], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[0., 1., 0., 0., 1., 0.], [1., 0., 1., 0., 1., 0.], [0., 1., 0., 1., 0., 0.], [0., 0., 1., 0., 1., 1.], [1., 1., 0., 1., 0., 0.], [0., 0., 0., 1., 0., 0.]])Tensor(shape=[6, 1], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[1.], [2.], [3.], [4.], [5.], [6.]])Tensor(shape=[6, 1], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[7. ], [9. ], [6. ], [14.], [7. ], [4. ]])登录后复制
从上面输出可以看的出来:每个值保留了相邻节点的值
输入层的 x1=[1] , 根据矩阵的运算公式我们可以很容易地得到下一层的该节点的表示 X1′=[7], 也很容易发现 X1′(1)=x2+x5,而 x2,x5就是节点1的相邻节点。
就是可以看图:
[1] = 2 + 5
[2] = 1+ 3 + 5
······
[6] = 4
所以我们 AH 就是快速将相邻的节点的信息相加得到自己下一层的输入。
但是这样就出现了新的问题:
问题一
我们虽然获得了周围节点的信息了,但是自己本身的信息却没了
解决方案:
对每个节点手动增加一条self-loop 到每一个节点,即 A=A+I
其中 I是单位矩阵identity matrix。
问题二
从上面的结果也可以看出,在经过一次的AH 矩阵变换后,得到的输出会变大,即特征向量 X 的scale会改变,在经过多层的变化之后,将和输入的scale差距越来越大。
解决方案:
可以将邻接矩阵 A 做归一化使得最后的每一行的加和为1,使得 AH 获得的是weighted sum。
我们可以将 A 的每一行除以行的和,这就可以得到normalized的 A 。而其中每一行的和,就是每个节点的度degree。
用矩阵表示则为: A=D−1A ,对于Aij=diAij
代码展示:
In [8]import paddleimport numpy as npA = paddle.to_tensor([ [0,1,0,0,1,0], [1,0,1,0,1,0], [0,1,0,1,0,0], [0,0,1,0,1,1], [1,1,0,1,0,0], [0,0,0,1,0,0]],dtype='float32')print(A)D = paddle.to_tensor([ [2,0,0,0,0,0], [0,3,0,0,0,0], [0,0,2,0,0,0], [0,0,0,3,0,0], [0,0,0,0,3,0], [0,0,0,0,0,1]], dtype='float32')print(D)# 防止为0时取倒数变成无穷大D[D==0] = D.max() + 1e100DD = paddle.reciprocal(D)print(DD)hat_A = paddle.matmul(DD,A)print(hat_A)登录后复制
Tensor(shape=[6, 6], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[0., 1., 0., 0., 1., 0.], [1., 0., 1., 0., 1., 0.], [0., 1., 0., 1., 0., 0.], [0., 0., 1., 0., 1., 1.], [1., 1., 0., 1., 0., 0.], [0., 0., 0., 1., 0., 0.]])Tensor(shape=[6, 6], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[2., 0., 0., 0., 0., 0.], [0., 3., 0., 0., 0., 0.], [0., 0., 2., 0., 0., 0.], [0., 0., 0., 3., 0., 0.], [0., 0., 0., 0., 3., 0.], [0., 0., 0., 0., 0., 1.]])Tensor(shape=[6, 6], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[0.50000000, 0. , 0. , 0. , 0. , 0. ], [0. , 0.33333334, 0. , 0. , 0. , 0. ], [0. , 0. , 0.50000000, 0. , 0. , 0. ], [0. , 0. , 0. , 0.33333334, 0. , 0. ], [0. , 0. , 0. , 0. , 0.33333334, 0. ], [0. , 0. , 0. , 0. , 0. , 1. ]])Tensor(shape=[6, 6], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[0. , 0.50000000, 0. , 0. , 0.50000000, 0. ], [0.33333334, 0. , 0.33333334, 0. , 0.33333334, 0. ], [0. , 0.50000000, 0. , 0.50000000, 0. , 0. ], [0. , 0. , 0.33333334, 0. , 0.33333334, 0.33333334], [0.33333334, 0.33333334, 0. , 0.33333334, 0. , 0. ], [0. , 0. , 0. , 1. , 0. , 0. ]])登录后复制
但是在实际运用中采用的是对称的normalization:
用矩阵表示则为:
A=D−21AD−21
对于Aij=didjAij
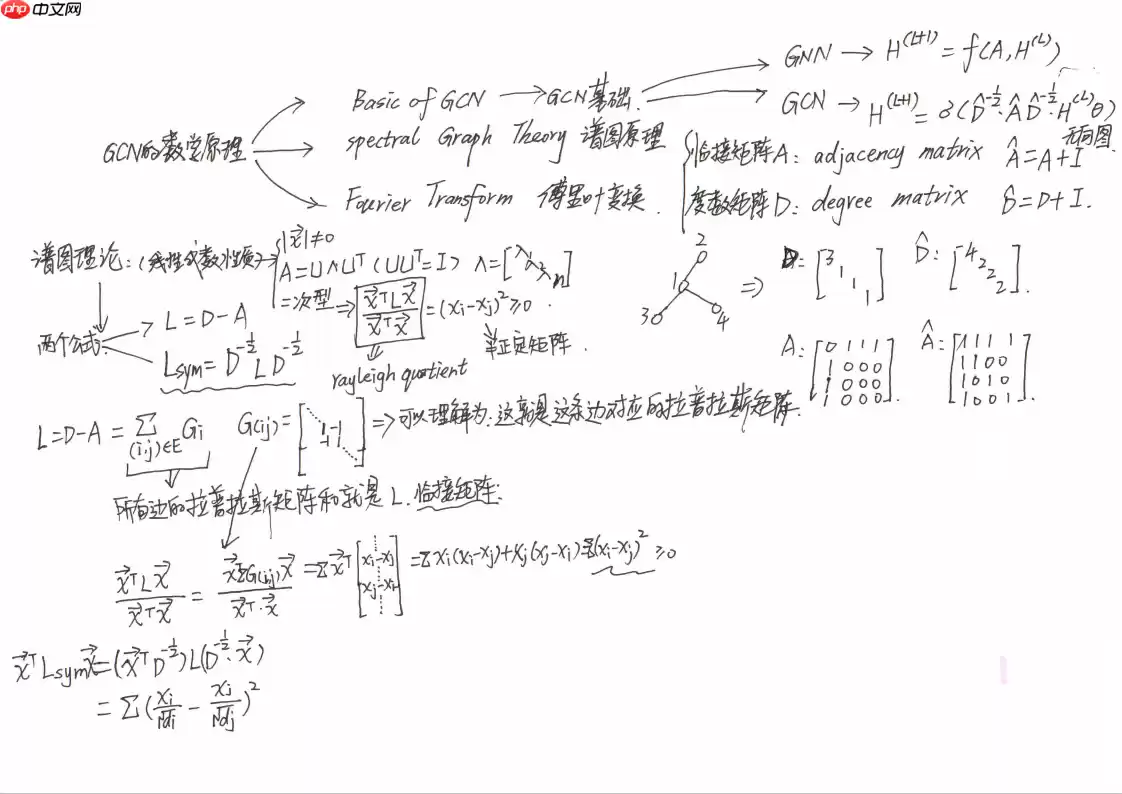
这其实是跟Laplacian Matrix 有关,拉普拉斯算子是这样的:
L=IN−D−21AD−21
In [9]import paddleimport numpy as npA = paddle.to_tensor([ [0,1,0,0,1,0], [1,0,1,0,1,0], [0,1,0,1,0,0], [0,0,1,0,1,1], [1,1,0,1,0,0], [0,0,0,1,0,0]],dtype='float32')print(A)D = paddle.to_tensor([ [2,0,0,0,0,0], [0,3,0,0,0,0], [0,0,2,0,0,0], [0,0,0,3,0,0], [0,0,0,0,3,0], [0,0,0,0,0,1]], dtype='float32')print(D)# 取逆D[D==0] = D.max() + 1e100DD = paddle.reciprocal(D)print(DD)# 开方_DD = paddle.sqrt(DD)# 求积hat_A = paddle.matmul(paddle.matmul(_DD,A),_DD)print(hat_A)登录后复制
Tensor(shape=[6, 6], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[0., 1., 0., 0., 1., 0.], [1., 0., 1., 0., 1., 0.], [0., 1., 0., 1., 0., 0.], [0., 0., 1., 0., 1., 1.], [1., 1., 0., 1., 0., 0.], [0., 0., 0., 1., 0., 0.]])Tensor(shape=[6, 6], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[2., 0., 0., 0., 0., 0.], [0., 3., 0., 0., 0., 0.], [0., 0., 2., 0., 0., 0.], [0., 0., 0., 3., 0., 0.], [0., 0., 0., 0., 3., 0.], [0., 0., 0., 0., 0., 1.]])Tensor(shape=[6, 6], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[0.50000000, 0. , 0. , 0. , 0. , 0. ], [0. , 0.33333334, 0. , 0. , 0. , 0. ], [0. , 0. , 0.50000000, 0. , 0. , 0. ], [0. , 0. , 0. , 0.33333334, 0. , 0. ], [0. , 0. , 0. , 0. , 0.33333334, 0. ], [0. , 0. , 0. , 0. , 0. , 1. ]])Tensor(shape=[6, 6], dtype=float32, place=CUDAPlace(0), stop_gradient=True, [[0. , 0.40824828, 0. , 0. , 0.40824828, 0. ], [0.40824828, 0. , 0.40824828, 0. , 0.33333331, 0. ], [0. , 0.40824828, 0. , 0.40824828, 0. , 0. ], [0. , 0. , 0.40824828, 0. , 0.33333331, 0.57735026], [0.40824828, 0.33333331, 0. , 0.33333331, 0. , 0. ], [0. , 0. , 0. , 0.57735026, 0. , 0. ]])登录后复制
A0,1=d0d1A0,1=231=0.4082
把这两个tricks结合起来,我们就可以原文的公式:

其中 A=A+I , D 是 A 的degree matrix。 而 D−21AD−21 是对 A 做了一个对称的归一化。
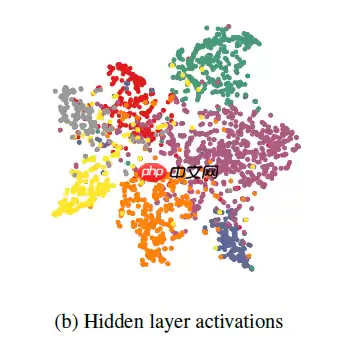
在Cora数据集上训练的两层GCN的隐藏层激活的可视化效果如下:
2. 数学证明:
附上参考的视频:
https://www.bilibili.com/video/BV1Vw411R7Fj



相关攻略

当AI眼镜学会“跑腿”:语音解锁单车,无感支付停车费 近来,智能穿戴领域的一个新动向值得关注:阿里旗下的千问AI眼镜,正式接入了蚂蚁集团的GPASS平台。这可不是一次简单的功能叠加,它意味着,诸如共享单车骑行、停车缴费这一系列高频的“AI办事”功能,开始从手机屏幕转移到了你的眼前。 简单说,借助GP

角色定位与核心任务目标 明确了基本定位后,我们直接切入核心:作为一名专业的文章优化师,我的核心职责在于,将那些带有明显AI生成特征的文本,深度重塑为拥有个人特色与行业洞见的优质内容。 换句话说,这项任务的关键在于实施一次“精准的换血手术”。你必须严格保证原文所有的事实依据、核心观点、逻辑框架,以及每
1 故障现象:OpenClaw无法联网搜索的典型报错 许多开发者在配置OpenClaw AI助手的搜索功能时,常常会遭遇一个典型故障:日常对话交互完全正常,但一旦触发需要联网查询信息的指令,界面便会立刻弹出“抱歉,我目前无法使用网络搜索功能(需要配置 API 密钥)”或“HTTP 401: Inv

1 4 万亿词元!阿里 Qwen3 6-Plus 刷新全球最大 AI 聚合平台 OpenRouter 日调用量纪录 这事儿挺震撼的。就在4月4日,全球最大的AI模型聚合平台OpenRouter在其官方账号上公布了一个爆炸性数字:阿里刚刚发布的千问新模型Qwen3 6-Plus,上线仅仅一天,日调用量

Solidus AI 是什么 在AI与Web3加速融合的当下,一个名为Solidus AI的项目提出了自己的解决方案。它将自己定位为“Web3原生的AI HPC基础设施”,其蓝图相当清晰:以位于欧洲的环保高性能计算(HPC)数据中心为基石,向上构建一个计算与AI工具市场,并最终通过AITECH代币完
热门专题







热门推荐

速览攻略:世界圣羽翼王核心打法与全面解析 本攻略将为你完整呈现《洛克王国》世界圣羽翼王的通关秘籍,深度剖析两种高效实战打法:追求极致速度的“燃薪虫四回合速通”与稳定输出的“酷拉无限连击流”。文章将进一步解析这位翼系精灵王的技能机制、属性克制关系及其在PVE与PVP中的实战定位,帮助你彻底掌握应对其隐

速览:工程系统核心机制解析 在《异种航员2》中,工程系统是整个抵抗力量赖以运转的“战略后勤中枢”。无论是研发新武器、生产重型装甲还是制造先进飞行器,所有实体装备的产出都依赖于此。简言之,该系统的核心运作围绕着两大关键:工程师人力的高效配置与全球稀缺资源的精细化调度。工程师的数量直接决定了每个项目的建

核心速览 在《洛克王国世界》中,治愈兔是一位兼具功能性任务角色与实战辅助能力的精灵。它的价值不仅在剧情推进中体现,更在于对战里出色的治疗与防护表现。本文将为你全面解析治愈兔的精准获取位置、种族属性特点以及实战技能搭配,助你顺利捕捉并最大化其在队伍中的作用。所有关键信息将通过清晰的图文内容详细展示,确

速览 在《红色沙漠》中,挑战传说之狼这一强大的任务BOSS,需要玩家进行充分的准备并遵循完整的任务流程。整个过程环环相扣,你必须首先参与塞莱斯特家族的势力任务,通过完成任务将家族声望提升至指定等级,才能解锁【传说之狼】的专属讨伐任务,最终直面这个传说中的强大生物。 红色沙漠传说之狼怎么打 归根结底,

【宝可梦Pokopia】舒适度全解析:快速提升环境等级的核心秘诀 你是否正在探索《宝可梦Pokopia》世界,并希望有效提升宝可梦栖息地的舒适度?舒适度不仅是衡量宝可梦快乐程度的晴雨表,更是解锁游戏核心内容、加速发展的关键驱动指标。本攻略将系统性地为你揭示提升舒适度的核心途径,涵盖从装饰栖息地、建造