FF Only:Attention真的需要吗?
本文复现去attention化论文,以Feed-Forward替代Transformer的attention层,基于ViT、DeiT模型在ImageNet表现良好。代码构建相关模型,展示结构与参数,在Cifar10简短训练,表明视觉Transformer中除注意力外的部分可能很重要。

前言
hi guy!我们又再一次见面了,这次来复现一篇非常有趣的论文,去attention化
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
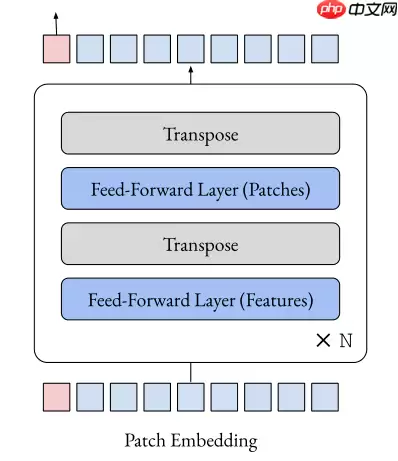
作者实验竟然惊讶发现,仅Feed-Forward就能在ImageNet表现良好的性能,这可以帮助研究人员理解为什么当前模型为什么这么有效
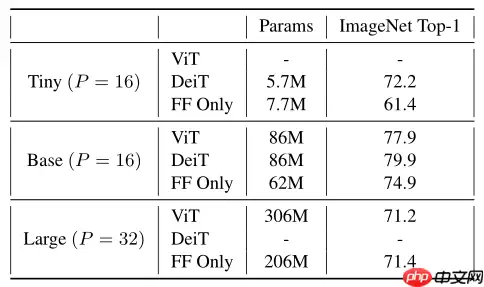
具体来说,该模型用FF(fead-forward)替换Transformer的attention层,基于ViT、DeiT的模型获得了良好的top1准确性,如下所示
完整代码
导入所需要的包
In [ ]import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom functools import partialtrunc_normal_ = nn.initializer.TruncatedNormal(std=.02)zeros_ = nn.initializer.Constant(value=0.)ones_ = nn.initializer.Constant(value=1.)kaiming_normal_ = nn.initializer.KaimingNormal()登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):登录后复制
基础函数定义
In [ ]def swapdim(x, dim1, dim2): a = list(range(len(x.shape))) a[dim1], a[dim2] = a[dim2], a[dim1] return x.transpose(a)def drop_path(x, drop_prob = 0., training = False): if drop_prob == 0. or not training: return x keep_prob = 1 - drop_prob shape = (x.shape[0],) + (1,) * (x.ndim - 1) random_tensor = paddle.to_tensor(keep_prob) + paddle.rand(shape) random_tensor = paddle.floor(random_tensor) output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer): def __init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob def forward(self, x): return drop_path(x, self.drop_prob, self.training) class Identity(nn.Layer): def __init__(self, *args, **kwargs): super(Identity, self).__init__() def forward(self, input): return inputclass Mlp(nn.Layer): def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x登录后复制
模型组网
In [ ]class LinearBlock(nn.Layer): def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, num_tokens=197): super().__init__() # First stage self.mlp1 = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop) self.norm1 = norm_layer(dim) # Second stage self.mlp2 = Mlp(in_features=num_tokens, hidden_features=int( num_tokens * mlp_ratio), act_layer=act_layer, drop=drop) self.norm2 = norm_layer(num_tokens) # Dropout (or a variant) self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity() def forward(self, x): x = x + self.drop_path(self.mlp1(self.norm1(x))) x = swapdim(x, -2, -1) x = x + self.drop_path(self.mlp2(self.norm2(x))) x = swapdim(x, -2, -1) return xclass PatchEmbed(nn.Layer): """ Wraps a convolution """ def __init__(self, patch_size=16, in_chans=3, embed_dim=768): super().__init__() self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x): x = self.proj(x) return xclass LearnedPositionalEncoding(nn.Layer): """ Learned positional encoding with dynamic interpolation at runtime """ def __init__(self, height, width, embed_dim): super().__init__() self.height = height self.width = width self.pos_embed = self.create_parameter(shape=[1, embed_dim, height, width], default_initializer=trunc_normal_) self.add_parameter("pos_embed", self.pos_embed) self.cls_pos_embed = self.create_parameter(shape=[1, 1, embed_dim], default_initializer=trunc_normal_) self.add_parameter("cls_pos_embed", self.cls_pos_embed) def forward(self, x): B, C, H, W = x.shape if H == self.height and W == self.width: pos_embed = self.pos_embed else: pos_embed = F.interpolate(self.pos_embed, size=[H, W], mode='bilinear', align_corners=False) # ?? return self.cls_pos_embed, pos_embedclass LinearVisionTransformer(nn.Layer): """ Basically the same as the standard Vision Transformer, but with support for resizable or sinusoidal positional embeddings. """ def __init__(self, *, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, positional_encoding='learned', learned_positional_encoding_size=(14, 14), block_cls=LinearBlock): super().__init__() # Config self.num_classes = num_classes self.patch_size = patch_size self.num_features = self.embed_dim = embed_dim # Patch embedding self.patch_embed = PatchEmbed(patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim) # Class token self.cls_token = self.create_parameter(shape=[1, 1, embed_dim], default_initializer=trunc_normal_) self.add_parameter("cls_token", self.cls_token) # Positional encoding if positional_encoding == 'learned': height, width = self.learned_positional_encoding_size = learned_positional_encoding_size self.pos_encoding = LearnedPositionalEncoding(height, width, embed_dim) else: raise NotImplementedError('Unsupposed positional encoding') self.pos_drop = nn.Dropout(p=drop_rate) # Stochastic depth dpr = [x for x in paddle.linspace(0, drop_path_rate, depth)] self.blocks = nn.LayerList([ block_cls(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, num_tokens=1 + (224 // patch_size)**2) for i in range(depth)]) self.norm = norm_layer(embed_dim) # Classifier head self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else Identity() self.apply(self._init_weights) def _init_weights(self, m): if isinstance(m, nn.Linear): trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None: zeros_(m.bias) elif isinstance(m, nn.LayerNorm): zeros_(m.bias) ones_(m.weight) def forward_features(self, x): # Patch embedding B, C, H, W = x.shape # B x C x H x W x = self.patch_embed(x) # B x E x H//p x W//p # Positional encoding # NOTE: cls_pos_embed for compatibility with pretrained models cls_pos_embed, pos_embed = self.pos_encoding(x) # Flatten image, append class token, add positional encoding cls_tokens = self.cls_token.expand([B, -1, -1]) x = x.flatten(2) # flatten x = swapdim(x , 1, 2) x = paddle.concat((cls_tokens, x), axis=1) # class token pos_embed = pos_embed.flatten(2) # flatten pos_embed = swapdim(pos_embed, 1, 2) pos_embed = paddle.concat([cls_pos_embed, pos_embed], axis=1) # class pos emb x = x + pos_embed x = self.pos_drop(x) # Transformer for blk in self.blocks: x = blk(x) # Final layernorm x = self.norm(x) return x[:, 0] def forward(self, x): x = self.forward_features(x) x = self.head(x) return x登录后复制模型生成
In [ ]def linear_tiny(**kwargs): model = LinearVisionTransformer( patch_size=16, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef linear_base(**kwargs): model = LinearVisionTransformer( patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef linear_large(**kwargs): model = LinearVisionTransformer( patch_size=32, embed_dim=1024, depth=24, num_heads=16, mlp_ratio=4, qkv_bias=True, norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return model登录后复制
模型结构可视化
In [ ]paddle.Model(linear_base()).summary((1,3,224,224))登录后复制
-------------------------------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # ================================================================================================== Conv2D-4 [[1, 3, 224, 224]] [1, 768, 14, 14] 590,592 PatchEmbed-4 [[1, 3, 224, 224]] [1, 768, 14, 14] 0 LearnedPositionalEncoding-4 [[1, 768, 14, 14]] [[1, 1, 768], [1, 768, 14, 14]] 151,296 Dropout-76 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-76 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-148 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-73 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-77 [[1, 197, 768]] [1, 197, 768] 0 Linear-149 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-73 [[1, 197, 768]] [1, 197, 768] 0 Identity-37 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-77 [[1, 768, 197]] [1, 768, 197] 394 Linear-150 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-74 [[1, 768, 788]] [1, 768, 788] 0 Dropout-78 [[1, 768, 197]] [1, 768, 197] 0 Linear-151 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-74 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-37 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-78 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-152 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-75 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-79 [[1, 197, 768]] [1, 197, 768] 0 Linear-153 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-75 [[1, 197, 768]] [1, 197, 768] 0 Identity-38 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-79 [[1, 768, 197]] [1, 768, 197] 394 Linear-154 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-76 [[1, 768, 788]] [1, 768, 788] 0 Dropout-80 [[1, 768, 197]] [1, 768, 197] 0 Linear-155 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-76 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-38 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-80 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-156 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-77 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-81 [[1, 197, 768]] [1, 197, 768] 0 Linear-157 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-77 [[1, 197, 768]] [1, 197, 768] 0 Identity-39 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-81 [[1, 768, 197]] [1, 768, 197] 394 Linear-158 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-78 [[1, 768, 788]] [1, 768, 788] 0 Dropout-82 [[1, 768, 197]] [1, 768, 197] 0 Linear-159 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-78 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-39 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-82 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-160 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-79 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-83 [[1, 197, 768]] [1, 197, 768] 0 Linear-161 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-79 [[1, 197, 768]] [1, 197, 768] 0 Identity-40 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-83 [[1, 768, 197]] [1, 768, 197] 394 Linear-162 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-80 [[1, 768, 788]] [1, 768, 788] 0 Dropout-84 [[1, 768, 197]] [1, 768, 197] 0 Linear-163 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-80 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-40 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-84 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-164 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-81 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-85 [[1, 197, 768]] [1, 197, 768] 0 Linear-165 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-81 [[1, 197, 768]] [1, 197, 768] 0 Identity-41 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-85 [[1, 768, 197]] [1, 768, 197] 394 Linear-166 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-82 [[1, 768, 788]] [1, 768, 788] 0 Dropout-86 [[1, 768, 197]] [1, 768, 197] 0 Linear-167 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-82 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-41 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-86 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-168 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-83 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-87 [[1, 197, 768]] [1, 197, 768] 0 Linear-169 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-83 [[1, 197, 768]] [1, 197, 768] 0 Identity-42 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-87 [[1, 768, 197]] [1, 768, 197] 394 Linear-170 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-84 [[1, 768, 788]] [1, 768, 788] 0 Dropout-88 [[1, 768, 197]] [1, 768, 197] 0 Linear-171 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-84 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-42 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-88 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-172 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-85 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-89 [[1, 197, 768]] [1, 197, 768] 0 Linear-173 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-85 [[1, 197, 768]] [1, 197, 768] 0 Identity-43 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-89 [[1, 768, 197]] [1, 768, 197] 394 Linear-174 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-86 [[1, 768, 788]] [1, 768, 788] 0 Dropout-90 [[1, 768, 197]] [1, 768, 197] 0 Linear-175 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-86 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-43 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-90 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-176 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-87 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-91 [[1, 197, 768]] [1, 197, 768] 0 Linear-177 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-87 [[1, 197, 768]] [1, 197, 768] 0 Identity-44 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-91 [[1, 768, 197]] [1, 768, 197] 394 Linear-178 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-88 [[1, 768, 788]] [1, 768, 788] 0 Dropout-92 [[1, 768, 197]] [1, 768, 197] 0 Linear-179 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-88 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-44 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-92 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-180 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-89 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-93 [[1, 197, 768]] [1, 197, 768] 0 Linear-181 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-89 [[1, 197, 768]] [1, 197, 768] 0 Identity-45 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-93 [[1, 768, 197]] [1, 768, 197] 394 Linear-182 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-90 [[1, 768, 788]] [1, 768, 788] 0 Dropout-94 [[1, 768, 197]] [1, 768, 197] 0 Linear-183 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-90 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-45 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-94 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-184 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-91 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-95 [[1, 197, 768]] [1, 197, 768] 0 Linear-185 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-91 [[1, 197, 768]] [1, 197, 768] 0 Identity-46 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-95 [[1, 768, 197]] [1, 768, 197] 394 Linear-186 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-92 [[1, 768, 788]] [1, 768, 788] 0 Dropout-96 [[1, 768, 197]] [1, 768, 197] 0 Linear-187 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-92 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-46 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-96 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-188 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-93 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-97 [[1, 197, 768]] [1, 197, 768] 0 Linear-189 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-93 [[1, 197, 768]] [1, 197, 768] 0 Identity-47 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-97 [[1, 768, 197]] [1, 768, 197] 394 Linear-190 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-94 [[1, 768, 788]] [1, 768, 788] 0 Dropout-98 [[1, 768, 197]] [1, 768, 197] 0 Linear-191 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-94 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-47 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-98 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-192 [[1, 197, 768]] [1, 197, 3072] 2,362,368 GELU-95 [[1, 197, 3072]] [1, 197, 3072] 0 Dropout-99 [[1, 197, 768]] [1, 197, 768] 0 Linear-193 [[1, 197, 3072]] [1, 197, 768] 2,360,064 Mlp-95 [[1, 197, 768]] [1, 197, 768] 0 Identity-48 [[1, 768, 197]] [1, 768, 197] 0 LayerNorm-99 [[1, 768, 197]] [1, 768, 197] 394 Linear-194 [[1, 768, 197]] [1, 768, 788] 156,024 GELU-96 [[1, 768, 788]] [1, 768, 788] 0 Dropout-100 [[1, 768, 197]] [1, 768, 197] 0 Linear-195 [[1, 768, 788]] [1, 768, 197] 155,433 Mlp-96 [[1, 768, 197]] [1, 768, 197] 0 LinearBlock-48 [[1, 197, 768]] [1, 197, 768] 0 LayerNorm-100 [[1, 197, 768]] [1, 197, 768] 1,536 Linear-196 [[1, 768]] [1, 1000] 769,000 ==================================================================================================Total params: 61,942,252Trainable params: 61,942,252Non-trainable params: 0--------------------------------------------------------------------------------------------------Input size (MB): 0.57Forward/backward pass size (MB): 365.91Params size (MB): 236.29Estimated Total Size (MB): 602.77--------------------------------------------------------------------------------------------------登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/numpy/core/fromnumeric.py:87: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray. return ufunc.reduce(obj, axis, dtype, out, **passkwargs)登录后复制
{'total_params': 61942252, 'trainable_params': 61942252}登录后复制添加预训练权重
ImageNet-1k validation
In [ ]# ff tinyff_tiny = linear_tiny()ff_tiny.set_state_dict(paddle.load('/home/aistudio/data/data96150/linear_tiny.pdparams'))# ff baseff_base = linear_base()ff_base.set_state_dict(paddle.load('/home/aistudio/data/data96150/linear_base.pdparams'))登录后复制Cifar10 验证性能
采用Cifar10数据集,无过多的数据增强
数据准备
In [ ]import paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10# 开启 GPUpaddle.set_device('gpu')# 数据准备transform = T.Compose([ T.Resize(size=(224,224)), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],data_format='HWC'), T.ToTensor()])train_dataset = Cifar10(mode='train', transform=transform)val_dataset = Cifar10(mode='test', transform=transform)登录后复制Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz Begin to downloadDownload finished登录后复制
模型准备
In [17]ff_base = linear_base(num_classes=10)ff_base.set_state_dict(paddle.load('/home/aistudio/data/data96150/linear_base.pdparams'))model = paddle.Model(ff_base)登录后复制开始训练
由于时间篇幅只训练5轮,感兴趣的同学可以继续训练
In [16]model.prepare(optimizer=paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters()), loss=paddle.nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy())# 开启训练可视化visualdl=paddle.callbacks.VisualDL(log_dir='visual_log') model.fit( train_data=train_dataset, eval_data=val_dataset, batch_size=64, epochs=5, verbose=1, callbacks=[visualdl] )登录后复制
训练过程可视化
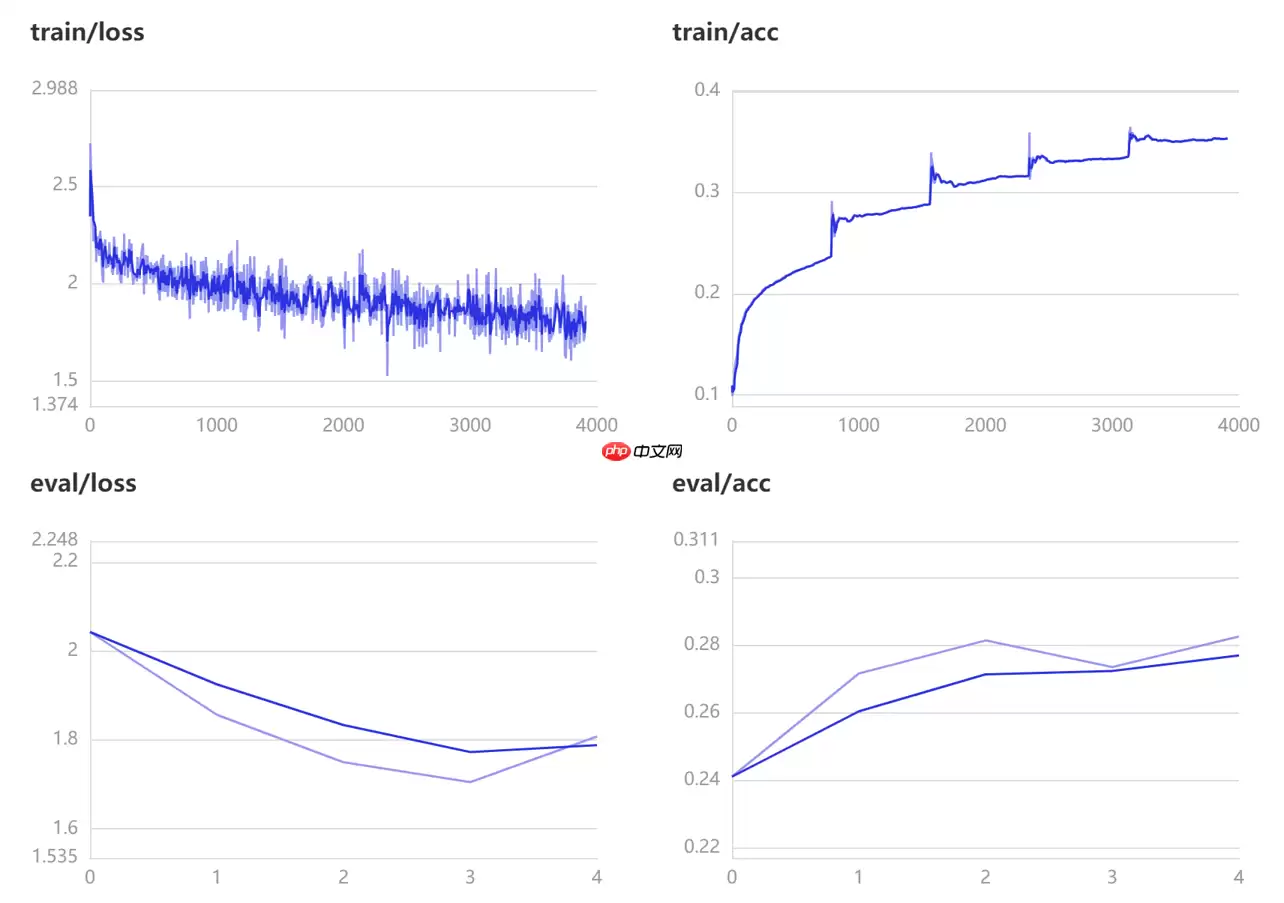
总结
这些结果表明,除了注意力以外,视觉Transformer的其他方面(例如patch embedding)可能比以前认为的要重要。我们希望这些结果能促使社区花费更多时间来理解为什么我们当前的模型如此有效。
相关攻略

爬虫与RPA:同为“自动化”,却大有不同 一提到自动化,爬虫和RPA(机器人流程自动化)是绕不开的两大技术。它们都致力于替代人工、提升效率,但如果你仔细琢磨,会发现两者就像“特种兵”与“文职助理”,职责领域和发力点截然不同。 一、应用场景:一个向外“索取”,一个向内“梳理” 爬虫的核心舞台在数据采集

Python Http请求 说到Python里的Http网络请求,大家常用的库其实就那么几个:Urllib、Urllib3、Httplib2,还有名声在外的Requests。这里头,Urllib3算是个实力派,它功能全面、设计清晰,不仅支持线程安全,还自带连接池,连文件上传(post)都给安排好了。

优化数据获取流程 网络爬虫的数据获取,其实可以拆解为“请求”和“执行”两个清晰的环节。简单来说,就是按照需求去下载网页信息。这个过程的核心,在于如何向服务器发送请求。技术上,我们通常会通过模拟浏览器行为来发送请求指令。如果服务器“接招”并给出了响应,程序就可以继续执行后续步骤;如果毫无反应,那就得回

在数字货币和区块链技术日益普及的今天,高效地与这些平台交互,已经成了开发者的一项必备技能。作为全球领先的加密货币交易平台,币安提供了丰富的API接口,尤其是其Web3 API,为基于以太坊等区块链网络的应用开发带来了巨大便利。那么,用什么工具来调用这些接口最顺手呢?答案很可能是Python。这门语言

爬虫技术介绍 当你用Requests、Scrapy或者Selenium这些工具从网上抓取数据时,拿到手的原始“材料”往往是HTML、XML或JSON格式的“毛坯”。这就像淘金,挖到了矿石,还需要后续的解析和提炼,才能把真正有价值的“金子”——也就是目标数据——分离出来,并妥善保存起来。 Reques
热门专题







热门推荐

传统游戏注册流程繁琐,常因网络或系统问题打断体验。免登录游戏实现“一键启动”,无需账号密码和个人信息,几秒即可畅玩。这种即时性完美契合快节奏生活,无论是碎片时间消遣还是突发娱乐冲动,用户都能零负担进入游戏,不再因流程繁琐而放弃尝试。下面是不用登录不用实名认证的游戏推荐! 不用登录不用实名认证的游戏推

在炉石传说的世界里,一套强力的卡组能带来无尽的乐趣与胜利的喜悦 今天要和大家深入探讨的,是一套围绕“无界空宇洛德”构筑的、极具爆发力的卡组。它的魅力在于,能在中期瞬间扭转战局,给对手带来巨大的压迫感。 卡组核心思路 这套牌的战术轴心非常明确:一切为了无界空宇洛德服务。前期,我们需要用低费卡牌进行场面

《Pragmata》全服装获取攻略!解锁Hugh和Diana所有外观,包括宾果板、通关奖励及豪华版专属服装。无属性加成,纯外观收集指南。 对于任何一款值得投入时间的游戏来说,角色外观的收集与搭配,本身就是一大乐趣。虽然在《Pragmata》里,服装并不影响战斗数值,但谁不想让自己操控的角色在末世冒险

《明日方舟终末地》庄方宜电队搭配一图流 《明日方舟终末地》1 2版本推出的新角色庄方宜,定位是六星电系核心输出。很多玩家拿到手后,最关心的问题自然是:这位强力大C,到底该怎么配队才能发挥最大威力?下面,我们就结合玩家“十三天天”整理的一图流攻略,来详细拆解庄方宜的电系队伍搭配思路。 核心配队逻辑解析

《明日方舟终末地》庄方宜配队与手法排轴教学 在《明日方舟终末地》的战场上,雷属性角色庄方宜以其独特的机制,带来了不少操作上的可能性与策略深度。那么,如何围绕她构建队伍,并安排一套行之有效的输出循环呢?今天,我们就来深入聊聊庄方宜的配队思路与实战手法排轴。 核心配队逻辑 为庄方宜搭配队伍,关键在于理解