【时间序列】时间序列分类方法一览
时间序列分类(time series classification) 是数据挖掘领域的重要任务,它涉及对按时间顺序排列的数据点进行标记和预测。此类数据广泛存在于金融、医疗、工业等多个领域,因此时间序列分类对于决策支持和系统开发具有重要意义。

时间序列分类
时间序列分类(time series classification) 是数据挖掘领域的重要任务,它涉及对按时间顺序排列的数据点进行标记和预测。此类数据广泛存在于金融、医疗、工业等多个领域,因此时间序列分类对于决策支持和系统开发具有重要意义。
在进行时间序列分类时,首先需要收集并预处理时间序列数据,然后通过特征提取技术将其转化为可用于分类的特征向量。接下来,使用适当的分类算法对特征向量进行训练,以构建一个能够准确预测新数据标签的分类模型。最后,评估模型的性能并进行优化以提高分类准确率。时间序列分类的挑战在于数据的动态性、高维度和噪声干扰等方面,因此选择合适的特征提取方法和分类算法至关重要。
目前,深度学习在计算机视觉和语音识别上有了非常广泛的应用,但是在工业应用方面还没有完善的体系,一方面缺乏数据集另一方缺乏优秀的顶级论文。在工业上的故障诊断领域,大多数据都来自于传感器的采集,如是西储大学轴承数据,TE化工数据集等,都是典型的时间序列,因而绝大多数问题可以抽象成时间序列分类(TSC)问题。因此本人准备从时间序列分类出发,用典型的深度学习方法,如多层感知器,卷积神经网络,递归神经网络等去测试UCR数据集(共128个时间序列数据集)和自己仿真的时间序列,由此得到一些启发和规律,再将这些知识迁移到工业上的故障诊断领域。为了方便大家阅读和复现代码,本文就不再有过多的数学推到,多以代码和如何使用代码为主(深度学习框架PaddlePaddle3.0),用最直观的方式去解释一些实验结果。
1 序列分类概述
1.1 相关定义
时间序列(TS):时间序列A是有序的n个数据点的集合,分为单变量时间序列(UTS)和多变量时间序列(MTS)。UTS中每个点ai表示一个数值,属于实数集R;MTS中每个点ai表示在同一时间点观测到的多个变量,每个点本身就是长度为d的向量ai属于Rd。
多变量时间序列(MTS):多变量时间序列A是n个向量的列表,每个向量ai有d个通道。这些通道的观测值被表示为标量ak,i。MTS可以被视为一组d个时间序列,所有ai中的观测值都在同一时间或空间点观察到。
时间序列分类(TSC):TSC是一种监督学习任务,通过神经网络学习目标变量与一组时间序列之间的关系。TSC的目标是将时间序列数据归类为有限的类别,并训练神经网络模型将时间序列数据集映射到具有C个类别标签的集合Y。在训练完成后,神经网络输出一个包含C个值的向量,估计了时间序列属于每个类别的概率。通常在神经网络的最后一层使用Softmax激活函数来实现这一目标。
数据集:数据集D包含m个时间序列和一组预定义的离散类标签C。每个时间序列A(i)可以是单变量或多变量,其标签为y(i) ∈ C。表1总结了UCR和UEA数据集的详细信息。
1.2 基于深度学习的TSC分类
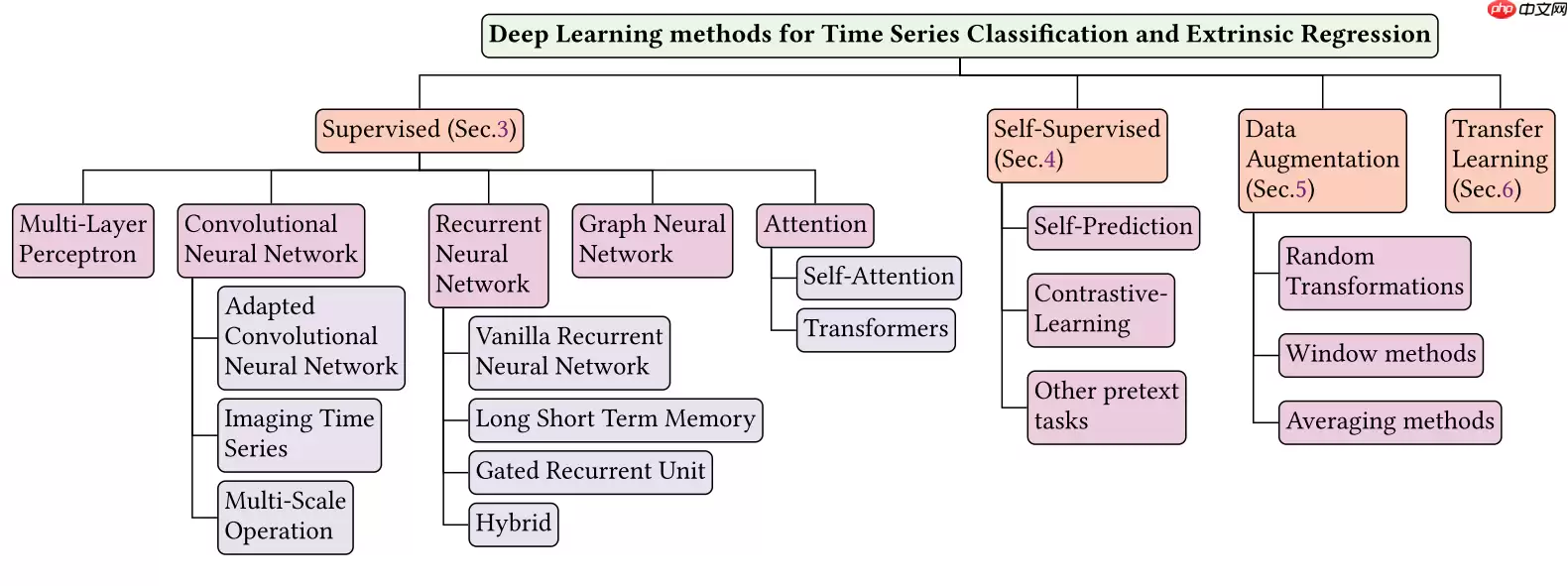
近年来,深度学习在TSC中的复杂问题上展现出显著的效果。基于深度学习的TSC方法主要分为生成式和判别式两类。生成式方法的目标是在训练分类器前找到合适的时间序列表示,而判别式方法则是直接将原始时间序列映射到类别概率分布。本综述主要关注判别式方法,因为其端到端的特性避免了繁琐的预处理。本文提出了一种基于网络架构和应用领域的分类方法,如图1所示,后续将详细讨论。(引用自Navidfoumani/TSC_Survey)
1.3 时间序列分类数据集
UCR和UEA时间序列存档分别是单变量和多变量时间序列分类基准数据集。UCR数据集于2002年提出,包含46个类别的数据集,2015年更新至85个,2018年扩展至128个,每个数据集样本都带有样本类别标签。UEA数据集于2018年发布,包含30个多变量数据集,例如心电图、运动分类、光谱分类等,这些数据集在维度数量、时间序列数量、时间序列类别数量和时间序列长度等方面各不相同。表1总结了UCR和UEA数据集的详细信息。

2 深度学习模型
2.1 多层感知机
全连接网络(Fully Connected network,FC)是最简单的神经网络架构,也称为多层感知器(MuLtilayer Perceptron,MLP)。如下图所示,FC中,每一层的所有神经元都与下一层的所有神经元连接,权重用于建模连接关系。MLP在处理时间序列数据时,存在的一个主要局限是它们不适合捕捉这种类型数据中的时间依赖关系。
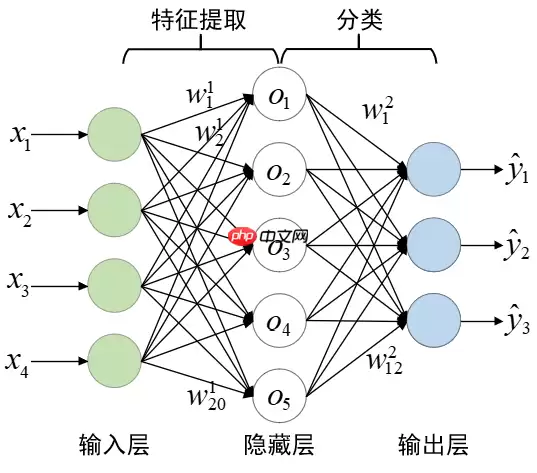
为了解决这个问题,一些研究将MLP和其他特征提取器相结合,如动态时间规整(DTW)。动态时间规整神经网络(DTWNN)利用DTW的弹性匹配技术来动态对齐网络层的输入与权重。尽管上述模型尝试解决MLP模型无法捕捉时间依赖关系的问题,但它们在捕捉时间不变特征方面仍存在局限性。此外,MLP模型无法以多尺度方式处理输入数据。许多其他深度学习模型更适合处理时间序列数据,例如循环神经网络(RNNs)和卷积神经网络(CNNs),这些模型专门设计用于捕捉时间序列数据中的时间依赖性和局部模式。
2.2 卷积神经网络模型
2.2.1 改进卷积神经网络
自2012年AlexNet在计算机视觉领域取得突破以来,CNN在时间序列分类方面经历了多次改进,形成了改进的时间序列分类CNNs。首个模型是多通道深度卷积神经网络(MC-DCNN),针对多变量数据特点对传统深度CNN进行改进。另一种模型是人体活动识别MC-CNN,同时将1D卷积应用于所有输入通道以捕捉时间和空间关系。全卷积网络(FCN)和ResNet也被改进用于端到端的时间序列分类。ResNet被用于单变量时间序列分类,包含3个残差块,后跟1个GAP层和1个Softmax分类器。此外,文献还提出了将ResNet和FCN结合的方法,以充分利用两个网络的优势。一些研究不仅调整网络架构,还专注于修改卷积核以适应时间序列分类任务。扩张卷积神经网络(DCNNs)是卷积神经网络的一种,使用扩张卷积增加感受野而不增加参数数量。分离型卷积神经网络(DisjointCNN)显示将1维卷积核分解为不相交的时间和空间组件,几乎不增加计算成本的情况下提高准确性。下表总结了基于改进卷积神经网络的时间序列分类模型。
2.2.2 时间序列图像化处理
时间序列分类的常见方法是将其转化为固定长度的表示并输入深度学习模型,但对长度变化或具有复杂时间依赖性的数据具有挑战性。一种解决方法是将时间序列数据表示为图像形式,使模型能学习内部空间关系。Wang等人提出将单变量时间序列数据编码为图像并使用CNN分类的方法。Hatami等人则将时间序列转化为2维图像并用深度CNN分类。此外,Chen等人利用相对位置矩阵和VGGNet对2维图像进行分类。Yang等人使用3种图像编码方法将多变量时间序列数据编码为2维图像。虽然这些方法在某些情况下有效,但将时间序列表示为2维图像可能导致信息损失,影响准确分类。使用特定转换方法(如GASF, GADF和MTF)并没有明显改善预测结果。表1对时间序列转二维图像方法归类,下表2总结了基于时间序列图像化处理的时间序列分类模型。
2.2.3 多尺度卷积
还有使用多尺度卷积神经网络(MCNN)、t-LeNet和多变量卷积神经网络(MVCNN)等模型,这些模型对输入时间序列进行预处理,以在多尺度序列上应用卷积。MCNN结构简单,包括2个卷积层、1个池化层、全连接层和Softmax层,但涉及大量数据预处理。t-LeNet使用窗口切片和窗口扭曲技术进行数据增强,以防止过拟合。受Inception架构启发,Liu等人设计了MVCNN,使用3种尺度的卷积核提取传感器之间的相互作用特征。Inception-ResNet架构包括卷积层、Inception模块和残差块,以提高性能。InceptionTime是一个集成模型,由5个相同结构的深度学习分类器组成,每个分类器由两个级联的Inception模块组成。它在UCR基准测试中达到最先进性能。此外,还介绍了EEGinception、InceptionFCN、MRes-FCN等模型,这些模型在时间序列分类中表现优秀,具有广泛的应用前景。下表总结了基于多尺度卷积的时间序列分类模型。
2.3 循环神经网络(RNN)
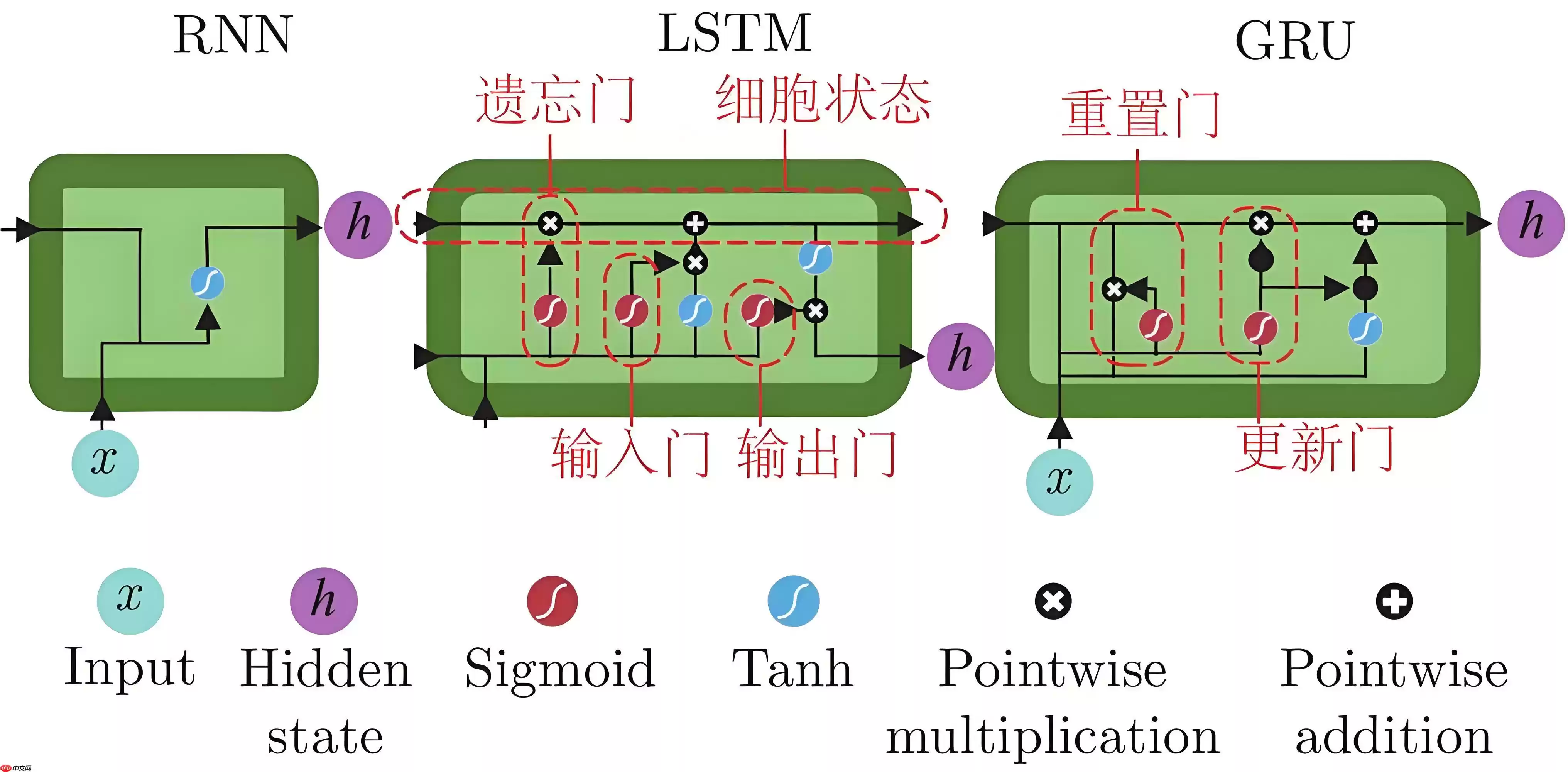
循环神经网络是一种能够处理序列数据的神经网络,它通过在层间建立有向连接并共享参数,可以处理可变长度的输入和输出。RNN模型主要分为序列到序列和序列到单一输出两种类型,它们在时间序列分类任务中尤为重要。
2.3.1 长短时记忆网络(LSTM)
LSTM通过引入门控记忆单元,有效解决了RNN在训练过程中可能出现的梯度消失或梯度爆炸问题。LSTM利用隐藏向量和记忆向量控制状态更新和输出,使其在处理如语言翻译、视频表示学习等序列数据问题时表现出色。在时间序列分类中,LSTM通常与序列到序列注意力网络结合使用,通过编码器和解码器实现序列到序列学习,提取关键信息并构建固定长度的序列,为分类提供支持。
2.3.2 门控循环单元(GRU)
GRU是LSTM的一个变体,它结构更简洁,仅包含重置门和更新门,这使得GRU在计算上更为高效,并且对数据的需求更少。GRU特别适合处理时间序列分类问题,它通过序列自编码器的形式,作为编码器和解码器处理不同长度的输入并产生固定大小的输出。在大规模无标签数据上进行预训练可以显著提升模型的准确性。
2.3.3 混合模型
结合卷积神经网络(CNN)和RNN的混合模型在时间序列分类中展现出更高的性能。CNN擅长捕捉空间关系,而RNN擅长捕捉时间依赖关系,两者的结合能够同时学习空间和时间特征,从而提高分类的准确性。
2.3.4 RNN的应用限制
尽管RNN及其变体在时间序列分类中表现出色,但在应用中也存在一些限制:
长时间序列训练时可能会遇到梯度消失和梯度爆炸问题。RNN的计算成本较高,训练和并行化较为困难。循环架构主要用于预测未来,不直接适用于时间序列分类。RNN可能无法有效捕捉长序列中的长程依赖关系。2.4 注意力机制模型
注意力机制模型在处理长距离依赖关系和整体顺序方面表现出色,它们可以提供更多的上下文信息,提高模型的学习能力。这些模型通过关注重要特征并抑制不必要的特征,增强了网络的表示能力。
2.4.1 注意力机制
注意力机制最初由Bahdanau等人提出,用于改进神经网络机器翻译中的编码器-解码器模型性能。这种机制允许解码器通过上下文向量关注源中的每个元素,已被证明在自然语言处理任务中非常有效。在时间序列分类任务中,注意力机制也被证明有效,并且可以通过结合CNN对时间序列进行编码。
2.4.2 注意力模型
自注意力机制:自注意力机制允许模型在处理序列时考虑序列内部的长距离依赖关系。Squeeze-and-Excitation (SE):一种注意力模型,通过重新加权特征通道来增强模型的表示能力。多尺度注意力卷积神经网络 (MACNN):结合了多尺度特征和注意力机制,以提高模型对不同尺度特征的捕捉能力。2.4.3 Transformers
Transformer模型近年来在自然语言处理和计算机视觉任务中取得了显著成功,成为深度学习领域的基础模型。它基于点积操作来寻找输入片段之间的关联或相关性。Transformer的编码器结构通常包括多头注意力层和前馈层。多头注意力机制已被应用于临床时间序列分类等多种任务。
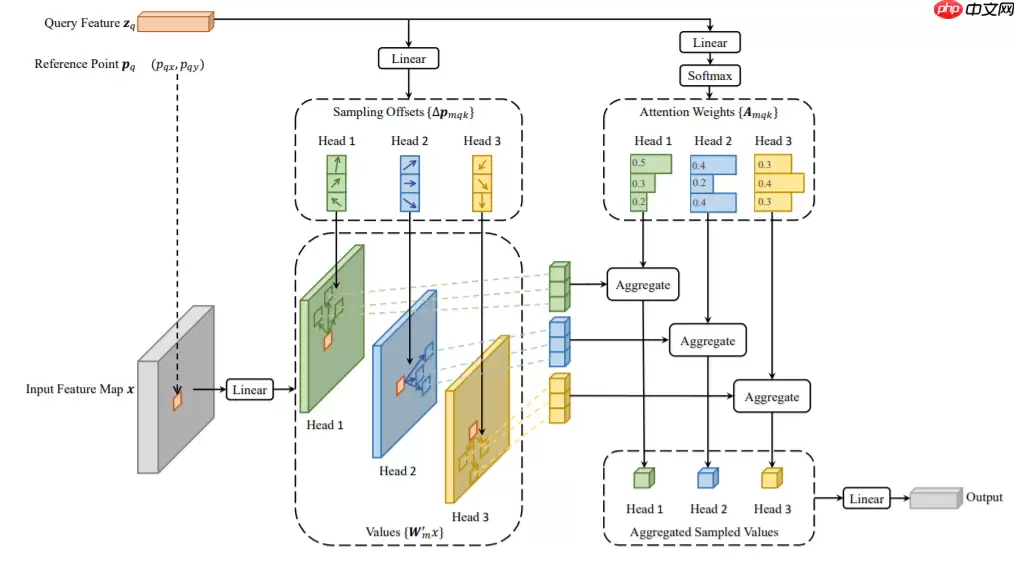
2.4.4 Transformers在时间序列分类中的应用
一些研究将Transformer应用于临床时间序列数据的分类,利用其强大的表示能力来提高分类准确性。其他研究使用时频特征作为输入嵌入到Transformer中,以处理时间序列数据。还有研究将高斯过程插值嵌入方法应用于原始光学卫星时间序列分类,展示了Transformer在处理这类数据时的潜力。
3 快速开始
本节将使用PaddlePaddle3.0,实现对与时间序列分类数据集UCR的加载,模型构建,训练以及测试,实现完整的流程。
In [1]# 导入相应的库import mathimport numpy as npimport pandas as pdimport paddleimport paddle.nn as nnfrom paddle.io import Dataset, DataLoaderimport paddle.optimizer as optim登录后复制In [2]
# Download the data 下载数据# !wget https://www.cs.ucr.edu/%7Eeamonn/time_series_data_2018/UCRArchive_2018.zip# !unzip UCRArchive_2018.zip登录后复制
3.1 时间序列数据可视化
In [3]# If you want to run the experiment on other datasets, please change file_name_prefix here:(修改数据集)file_name_prefix = "UCRArchive_2018/Coffee/Coffee"登录后复制In [4]
import pandas as pdimport matplotlib.pyplot as pltimport numpy as npfrom numpy import matlib# 读取CSV文件data = pd.read_csv('UCRArchive_2018/Car/Car_TRAIN.tsv', nrows=1, sep='\t', header=None) # 只读取第一行print(data)# 提取第一行数据(除了列名)row_data = data.iloc[0].values# 第一个数为label,其他为观测值label = row_data[0]observations = row_data[1:]# 使用折线图进行可视化(从第二个元素开始)plt.figure(figsize=(5, 3)) # 设置图形大小plt.plot(range(1, len(observations) + 1), observations, marker='', color='red', linewidth='4') # 从第二个元素开始绘制折线图# plt.title(f'Observations for Label: {label}') # 设置图表标题plt.xlabel([]) # 设置x轴标签plt.ylabel([]) # 设置y轴标签# plt.grid(True) # 显示网格线# 隐藏坐标轴plt.axis('off')plt.savefig('ts_vision.svg', bbox_inches='tight')plt.show() # 显示图表登录后复制0 1 2 3 4 5 6 7 \0 1 1.654107 1.621582 1.589211 1.557358 1.525398 1.493311 1.483532 8 9 ... 568 569 570 571 572 \0 1.483766 1.455129 ... 1.675778 1.672432 1.669461 1.666592 1.664132 573 574 575 576 577 0 1.661809 1.659795 1.640838 1.607442 1.607442 [1 rows x 578 columns]登录后复制
登录后复制
3.2 时间序列数据加载
In [5]class UCR_data_provider(Dataset): def __init__(self, dataset_type: str = 'train', znorm: bool = True): self.input_size = 0 self.output_size = 0 self.dataset_type = dataset_type self.znorm = znorm self.read_dataset() def read_dataset(self): if self.dataset_type == 'train': df_raw = pd.read_csv(file_name_prefix + '_TRAIN.tsv', sep='\t', header=None) elif self.dataset_type == 'test': df_raw = pd.read_csv(file_name_prefix + '_TEST.tsv', sep='\t', header=None) else: raise ValueError("Illegal dataset type.") ts = df_raw.drop(columns=[0]) ts = ts.fillna(0) self.input_size = ts.shape[1] # shape指第index维度的维数,DataFrame的成员 ts.columns = range(ts.shape[1]) label = df_raw.values[:, 0] self.output_size = int(max(label) + 1) ts = ts.values if self.znorm: std_ = ts.std(axis=1, keepdims=True) std_[std_ == 0] = 1.0 ts = (ts - ts.mean(axis=1, keepdims=True)) / std_ self.ts = ts self.label = label def __getitem__(self, index): ts = self.ts[index] label = self.label[index] return ts, label def __len__(self): return self.label.shape[0]登录后复制In [6]train_batch_size = 4test_batch_size = 4UCR_dataset_train = UCR_data_provider(dataset_type='train')UCR_dataset_test = UCR_data_provider(dataset_type='test')train_len = (len(UCR_dataset_train) // train_batch_size) * train_batch_sizetest_len = math.ceil(len(UCR_dataset_test) // test_batch_size) * test_batch_size# 返回一个三维tensor, (batch_size, seq_len, S=1/MS=7)train_loader = DataLoader(UCR_dataset_train, batch_size=train_batch_size, shuffle=True, drop_last=True)test_loader = DataLoader(UCR_dataset_test, batch_size=test_batch_size, shuffle=False, drop_last=False)登录后复制
3.3 构建模型
In [7]# 构建一个简单的CNN模型class CNN(nn.Layer): def __init__(self, dim, n_classes): super(CNN, self).__init__() self.embed_layer1 = nn.Sequential(nn.Conv2D(1, 16 * 2, kernel_size=[1, 8], padding='same'), nn.BatchNorm2D(16 * 2), nn.GELU()) self.embed_layer2 = nn.Sequential(nn.Conv2D(16 * 2, 16 * 4, kernel_size=[1, 8], padding='same'), nn.BatchNorm2D(16 * 4), nn.GELU()) self.embed_layer3 = nn.Sequential(nn.Conv2D(16 * 4, 16 * 2, kernel_size=[1, 8], padding='same'), nn.BatchNorm2D(16 * 2), nn.GELU()) self.embed_layer4 = nn.Sequential(nn.Conv2D(16 * 2, 16 * 2, kernel_size=[1, 1], padding='valid'), nn.BatchNorm2D(32), nn.GELU()) self.conv1 = nn.Conv1D(32, 16, kernel_size=3, stride=1, padding=1) self.pool1 = nn.MaxPool1D(2, stride=2) self.gelu1 = nn.GELU() self.conv2 = nn.Conv1D(16, 8, kernel_size=3, stride=1, padding=1) self.pool2 = nn.MaxPool1D(kernel_size=2, stride=2) self.gelu2 = nn.GELU() self.head = nn.Linear(8 * (dim // 4), n_classes) def forward(self, ts): ts = ts.unsqueeze(1) x = ts.unsqueeze(1) x_src = self.embed_layer1(x) x_src = self.embed_layer2(x_src) x_src = self.embed_layer3(x_src) encoded_ts = self.embed_layer4(x_src).squeeze(2) x = self.gelu1(self.pool1(self.conv1(encoded_ts))) x = self.gelu2(self.pool2(self.conv2(x))) # 展平特征并应用全连接层 x = x.reshape([-1, int(x.shape[1] * x.shape[2])]) # 假设你的x是一个三维Tensor,你想要展平除了batch_size外的其他维度 x = self.head(x) return x登录后复制In [8]
# 使用Paddle构建基于非深度学习方法的ROCKETclass Rocket(nn.Layer): def __init__(self, n_features, seq_len, n_classes, n_kernels=100, kss=[7, 9, 11]): super(Rocket, self).__init__() kss = [ks for ks in kss if ks < seq_len] convs = nn.LayerList() for i in range(n_kernels): ks = np.random.choice(kss) dilation = 2**np.random.uniform(0, np.log2((seq_len - 1) // (ks - 1))) padding = int((ks - 1) * dilation // 2) if np.random.randint(2) == 1 else 0 weight = paddle.randn(shape=[1, n_features, ks]) weight -= weight.mean() bias = 2 * (paddle.rand(shape=[1]) - .5) layer = nn.Conv1D(n_features, 1, ks, padding=2 * padding, dilation=int(dilation), bias=True) layer.weight = paddle.create_parameter(weight.shape, dtype=weight.dtype, default_initializer=paddle.nn.initializer.Assign(weight)) layer.bias = paddle.create_parameter(bias.shape, dtype=bias.dtype, default_initializer=paddle.nn.initializer.Assign(bias)) convs.append(layer) self.convs = convs self.n_kernels = n_kernels self.feature_dim = 2 * n_kernels self.fc = nn.Linear(self.feature_dim, n_classes) def forward(self, x): # input x: [B, F, T], where B = Batch size, F = features, T = Time sampels, _output = [] for i in range(self.n_kernels): out = self.convs[i](x).cpu() _max = out.max(dim=-1)[0] _ppv = (out > 0).astype('float32').sum(axis=-1) / out.shape[-1] _output.append(_max) _output.append(_ppv) output = paddle.concat(_output, axis=1) # [batch_size, feature_dim] if paddle.is_compiled_with_cuda(): output = output.cuda(0) output = self.fc(output) return output登录后复制In [9]# 构建一个Encoder模型import paddleimport paddle.nn as nnfrom paddle.nn import TransformerEncoderLayer, TransformerEncoderclass Encoder(nn.Layer): def __init__(self, input_size: int = 0, output_size: int = 0, nhead: int = 1, num_layers: int = 6, dim_feedforward: int = 2048, dropout: float = 0.1): if input_size == 0 or output_size == 0: raise ValueError("Requiring input_size and output_size.") super().__init__() encoder_layer = TransformerEncoderLayer(input_size, nhead, dim_feedforward, dropout) encoder_norm = nn.LayerNorm(input_size) self.encoder = TransformerEncoder(encoder_layer, num_layers, encoder_norm) self.ffn = nn.Linear(input_size, output_size, bias_attr=True) self.input_size = input_size def forward(self, x): if x.size(-1) != self.input_size: raise RuntimeError("the feature number of input must be equal to input_size") x = self.encoder(x) return self.ffn(x)登录后复制3.4 模型训练与测试
In [10]import osfrom sklearn.metrics import f1_score, roc_auc_score# 检查是否支持 CUDAif paddle.device.is_compiled_with_cuda(): device = paddle.device.set_device('gpu:0') print("Train on GPU")else: print("GPU is not available, we will use CPU instead of GPU")model = CNN(dim=UCR_dataset_train.input_size, n_classes=UCR_dataset_train.output_size)# model = Encoder(input_size=UCR_dataset_train.input_size, output_size=UCR_dataset_train.output_size)# 超参数设置learning_rate = 0.0001optimizer = optim.AdamW(learning_rate=learning_rate, parameters=model.parameters(), weight_decay=0.0001)loss_fn = nn.CrossEntropyLoss()epochs = 10eva_folder = 'output'if not os.path.exists(eva_folder): os.makedirs(eva_folder)train_epoch_acc = []train_epoch_loss = []test_epoch_acc = []test_epoch_loss = []# 模型训练for e in range(epochs): train_acc = 0 train_loss = 0 test_acc = 0 test_loss = 0 for i, (x_train, y_train) in enumerate(train_loader): x_train = x_train.astype('float32').to(device) y_train = y_train.astype('int64').to(device) y_pred = model(x_train) predicted = paddle.argmax(y_pred.data, 1) loss = loss_fn(y_pred, y_train) train_loss += loss.item() train_acc += (predicted == y_train).sum() loss.backward() optimizer.step() print('Epoch: {}, Cur_lr: {:.5f}, Train Loss: {:.5f}, Train Acc: {:.3f}'.format(e, learning_rate, (train_loss / train_len), (100 * ( train_acc.item() / train_len)) )) train_epoch_acc.append(100 * (train_acc.item() / train_len)) train_epoch_loss.append(train_loss / train_len)# 模型测试 model.eval() # 设置模型为评估模式 correct = 0 all_labels = [] all_probs = [] # test import time start = time.time() for i, (x_test, y_test) in enumerate(test_loader): x_test = x_test.astype('float32').to(device) y_test = y_test.astype('int64').to(device) y_val = model(x_test) predicted = paddle.argmax(y_val.data, 1) loss = loss_fn(y_val, y_test) test_loss += loss.item() test_acc += (predicted == y_test).sum() # 存储真实标签和预测概率 all_labels.extend(y_test.detach().cpu().numpy()) probabilities = paddle.nn.functional.softmax(y_val, axis=-1) all_probs.extend(probabilities.detach().cpu().numpy()) time_used = time.time() - start print(time_used) # 计算 F1-score f1 = f1_score(all_labels, np.argmax(all_probs, axis=1), average='macro') # 计算 AUC # y_true = np.array(all_labels) # y_scores = np.array(all_probs) # auc = roc_auc_score(y_true, y_scores, multi_class='ovo', average='macro') print(f"F1-score: {f1}") print('Epoch: {}, Cur_lr: {:.5f}, Test Loss: {:.5f}, Test Acc: {:.3f}'.format(e, learning_rate, (test_loss / test_len), (100 * ( test_acc.item() / test_len)) )) test_epoch_acc.append(100 * (test_acc.item() / test_len)) test_epoch_loss.append(test_loss / test_len)登录后复制Train on GPU登录后复制
W0726 10:33:42.391019 71769 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 12.0, Runtime API Version: 11.8W0726 10:33:42.397060 71769 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9./opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(登录后复制
Epoch: 0, Cur_lr: 0.00010, Train Loss: 0.17294, Train Acc: 53.5710.3813612461090088F1-score: 0.6354166666666667Epoch: 0, Cur_lr: 0.00010, Test Loss: 0.17196, Test Acc: 64.286Epoch: 1, Cur_lr: 0.00010, Train Loss: 0.16675, Train Acc: 64.2860.31325459480285645F1-score: 0.3488372093023256Epoch: 1, Cur_lr: 0.00010, Test Loss: 0.16618, Test Acc: 53.571Epoch: 2, Cur_lr: 0.00010, Train Loss: 0.15959, Train Acc: 75.0000.3412129878997803F1-score: 0.9270833333333333Epoch: 2, Cur_lr: 0.00010, Test Loss: 0.15629, Test Acc: 92.857Epoch: 3, Cur_lr: 0.00010, Train Loss: 0.14256, Train Acc: 89.2860.5003435611724854F1-score: 0.625668449197861Epoch: 3, Cur_lr: 0.00010, Test Loss: 0.14621, Test Acc: 64.286Epoch: 4, Cur_lr: 0.00010, Train Loss: 0.13112, Train Acc: 85.7140.6045587062835693F1-score: 0.9270833333333333Epoch: 4, Cur_lr: 0.00010, Test Loss: 0.12471, Test Acc: 92.857Epoch: 5, Cur_lr: 0.00010, Train Loss: 0.11456, Train Acc: 92.8570.306201696395874F1-score: 0.9270833333333333Epoch: 5, Cur_lr: 0.00010, Test Loss: 0.11018, Test Acc: 92.857Epoch: 6, Cur_lr: 0.00010, Train Loss: 0.10243, Train Acc: 92.8570.21962332725524902F1-score: 0.8564102564102565Epoch: 6, Cur_lr: 0.00010, Test Loss: 0.11047, Test Acc: 85.714Epoch: 7, Cur_lr: 0.00010, Train Loss: 0.10781, Train Acc: 71.4290.4008927345275879F1-score: 0.6571428571428571Epoch: 7, Cur_lr: 0.00010, Test Loss: 0.12239, Test Acc: 67.857Epoch: 8, Cur_lr: 0.00010, Train Loss: 0.07673, Train Acc: 100.0000.21308040618896484F1-score: 0.9638709677419355Epoch: 8, Cur_lr: 0.00010, Test Loss: 0.07794, Test Acc: 96.429Epoch: 9, Cur_lr: 0.00010, Train Loss: 0.12291, Train Acc: 64.2860.42348647117614746F1-score: 0.4285714285714286Epoch: 9, Cur_lr: 0.00010, Test Loss: 0.19558, Test Acc: 57.143登录后复制
3.5 结果可视化
In [11]import csvimport matplotlib.pyplot as pltwith open('result/' + 'Car.csv', 'w') as f: writer = csv.writer(f) writer.writerow(['train_loss', 'train_accuracy', 'test_loss', 'test_accuracy']) for train_loss, train_accuracy, test_loss, test_accuracy in zip(train_epoch_loss, train_epoch_acc, test_epoch_loss, test_epoch_acc): writer.writerow([train_loss, train_accuracy, test_loss, test_accuracy])path_img = eva_folder + f'Car.webp'time = list(range(epochs))fig, (a1, a2) = plt.subplots(1, 2, sharex=False, sharey=False)fig.set_figheight(5)fig.set_figwidth(15)plt.subplots_adjust(wspace=0.3, hspace=0)x_major_locator = plt.MultipleLocator(5)a1.plot(time, train_epoch_acc, color='r', marker='o', label='Train_ACC', linewidth=2.5, markersize=10)a1.plot(time, test_epoch_acc, color='g', marker='v', label='Test_ACC', linewidth=2.5, markersize=10)a1.set_xlabel('Epochs', fontdict={'size': 9}, labelpad=-1)a1.set_ylabel('ACC:%', fontdict={'size': 9})a1.tick_params(labelsize=7)a1.xaxis.set_major_locator(x_major_locator)a1.set_title('Accuarcy', fontsize=10)a1.legend(loc=0, prop={'size': 9})a2.plot(time, train_epoch_loss, color='r', marker='o', label='Train_Loss', linewidth=2.5, markersize=10)a2.plot(time, test_epoch_loss, color='g', marker='v', label='Test_Loss', linewidth=2.5, markersize=10)a2.set_xlabel('Epochs', fontdict={'size': 9}, labelpad=-1)a2.set_ylabel('Loss', fontdict={'size': 9})a2.tick_params(labelsize=7)a2.xaxis.set_major_locator(x_major_locator)a2.set_title('Loss', fontsize=10)a2.legend(loc=0, prop={'size': 9})fig.tight_layout()plt.savefig(path_img)登录后复制登录后复制
4 时间序列分类应用
时间序列分类技术在人类活动识别、脑电图情绪识别以及股票预测等领域具有广泛应用。
4.1 人体活动识别最新进展和挑战
HAR(人类活动识别)通过对传感器或仪器收集的数据进行分析,用于识别或监测人类活动。随着可穿戴技术和物联网的发展,HAR的应用变得更加广泛,包括医疗保健、健身监测、智能家居以及辅助生活等。用于收集HAR数据的设备主要有视觉设备和基于传感器的设备,其中基于传感器的设备又分为对象传感器、环境传感器和可穿戴传感器。大多数HAR研究使用可穿戴传感器或视觉设备的数据。在可穿戴设备中,主要使用的传感器包括加速度计、陀螺仪和磁传感器,这些传感器的数据被分成时间窗口,然后学习一个将每个时间窗口的多元传感器数据映射到一组活动的函数。用于HAR的深度学习方法包括CNN和RNN,以及混合的CNNRNN模型。
4.2 脑电图情绪识别最新进展和挑战
情绪在人类决策、规划等心理活动中起着关键作用,可通过面部表情、语言、行为或生理信号识别。脑电图(EEG)是一种非侵入性的生理信号,可直接测量情绪状态下的脑电活动,具有高时间分辨率、快数据采集和传输速度、低成本等优点,是自发和非主观地反映人类情绪状态的信号,广泛应用于情绪识别研究。然而,EEG信号的非平稳性、非线性特性以及伪影影响使得基于脑电图的情绪识别极具挑战性。本综述的研究范围仅提供了使用深度学习进行脑电图情绪识别研究的简要概述。深度学习方法可分为CNN、RNN以及混合的CNN-RNN模型,也有部分研究使用Transformer模型,但目前较少。
5 总结
5.1 项目总结
近年来,深度学习在时间序列分类(TSC)领域非常活跃,但尚未出现主导其他方法的模型。待解决的问题和未来研究趋势包括:
不等长度时间序列的处理:现有模型通常假设所有时间序列具有相同的采样频率,但在实际应用中,时间序列往往具有不等长度。研究如何设计能够适应不同长度时间序列的模型是一个重要的研究方向。
网络架构的设计:深度学习模型需要更适应时间序列数据的特点,以提升时间序列分类模型的性能。设计能够捕捉时间序列内在结构和模式的网络架构是关键。
模型可解释性的提升:深度学习模型存在“黑盒效应”,决策过程缺乏透明性。在医学和金融等关键领域,提升模型的可解释性是至关重要的,以减少不可接受的错误决策。
类别不平衡的处理:在许多实际应用场景中,时间序列数据类别不平衡,可能导致模型在训练和评估时出现偏差。研究如何有效地处理类别不平衡问题,确保模型的公平性和准确性,是一个重要的研究方向。
利用大语言模型处理时间序列:预训练大型语言模型具有强大的表示学习能力,可以探索如何利用这些模型来处理时间序列数据。这可能为时间序列分类带来新的视角和方法。
构建大型通用标签数据集:时间序列分类领域目前缺乏一个大型通用标签数据集。为了有效评估时间序列分类深度学习模型,迫切需要构建一个时间序列大型通用标签数据集,这将为模型的评估和比较提供重要基础。
尽管深度学习在时间序列分类领域取得了显著进展,但仍有许多挑战需要克服。未来的研究需要集中在设计能够适应时间序列数据特点的网络架构、提升模型的可解释性、处理类别不平衡问题、利用大型语言模型以及构建大型通用标签数据集等方面。通过解决这些问题,可以推动时间序列分类技术的发展,提高其在实际应用中的有效性和可靠性。
相关攻略

Trae在Python数据分析与机器学习项目中主要通过四种方式提供支持:利用Auto模式自动生成并执行端到端分析脚本;通过AgentCLI命令行自动化机器学习建模流程;对现有代码进行智能调试与优化;借助语音交互快速构建数据处理函数。这些功能覆盖了从需求描述到代码生成、模型构建及代码优化的全流程。

在Python编程中,你是否也曾编写过类似的统计代码? 统计词频 count = {} for word in words: if word in count: count[word] += 1 else: count[word] = 1 实际上,这种高频的计数需求,完全可以通过Python内置

Trae稳定支持Python3 10至3 13版本,3 9及以下版本无法运行。Python3 14处于实验性支持阶段,核心功能可能受限。当存在多个3 10以上版本时,Trae优先选择虚拟环境中的解释器,其次为最高系统版本。此外,Trae仅兼容64位Python解释器,不支持32位架构。

在企业级数据采集与自动化运维实践中,IT团队普遍面临一个核心挑战:Python爬虫为何频繁报错,修补维护何时才能终结?随着前端技术演进与动态反爬机制的日益复杂,依赖DOM解析的传统爬虫脚本往往陷入“部署即过时,运行即异常”的困境。本文将深入解析传统爬虫代码脆弱性的根本原因,并系统介绍一种能够重塑数据

很多刚接触Docker的开发者常有一个误解:制作镜像不就是把源代码打包进去就行了吗?实际上,在企业级的标准化开发流程中,直接将源码打包进Docker镜像是非常不专业的做法。这会导致镜像体积臃肿、引入潜在安全风险,并且模糊了“构建环境”与“运行环境”的边界。本文将深入解析Java、Vue、Go、Pyt
热门专题







热门推荐

现货持有者坚守仓位,比特币接近115,000水平 近期比特币(BTC)价格接近$115,000水平,市场整体情绪谨慎,但现货持有者依旧坚守仓位,显示出一定的多头信心。 市场现状与资金流动 那么,当前市场的资金究竟在如何流动?分析显示,一个有趣的现象正在上演:短线资金的流入其实相当有限,市场热度并未急

目录 要点介绍:分析师称XRP呈现“最强看涨结构”高位清算集中于2 90美元以上区域 周四,XRP价格稳稳站在了2 80美元上方。这个位置守住了,意味着什么?意味着市场向那个经典的“杯柄形态”目标价——6美元以上——又迈进了一步。 要点介绍: 先看几个核心数据:周四XRP报收2 82美元。技术分析显

近期,以太坊(ETH)衍生品市场经历了短暂的闪崩,但随后价格快速企稳,交易者开始关注关键突破点——$4,500水平。 ETH衍生品市场现状 市场情绪往往在剧烈波动后显露真容。从最新的链上数据和期权、永续合约的交易情况来看,那场短暂的闪崩更像是一次压力测试——结果是,市场波动率显著下降,多空力量似乎进

DOGE单日暴涨11%,交易量激增四倍,市场风向变了? 最近,加密货币市场又热闹起来了。DOGE(狗狗币)上演了一出“旱地拔葱”,价格单日暴涨11%,更关键的是,成交量直接翻了四倍。这种“价量齐升”的场面,无疑给整个迷因币板块打了一针强心剂,市场情绪肉眼可见地回暖了。 DOGE价格拉升原因分析 那么

如何安全获取欧易(OKX)官方APP?一份详尽的下载与使用指南 Binance币安 欧易OKX ️ Huobi火币️ 当人们谈论“欧易易欧”时,指的往往是那个全球顶尖的数字资产交易平台——欧易(OKX)。作为业务版图庞大的行业巨头,其官方APP无疑是用户进行交易、查看行情和管理资产的核心工具。不过,