应用体验:肺炎CT图像识别(Grad-CAM)
GoogLeNet依靠两个辅助loss将网络撑到22层并取得2014年ILSVRC比赛的冠军,但增加辅助loss的方法似乎治标不治本,否则GoogLeNet也不会增加区区三层即止,给人一种吊着氧气瓶赢得马拉松的感觉。2015年ResNet横空出世,使用残差结构打破深度神经网络的任督二脉!从此DNN层数开始成百上千。

项目背景
肺炎给人民的健康生活带来巨大的风险和挑战,尤其在医疗技术不是很发达的地区,由于缺乏医疗资源和医护人员,肺炎患者不能及时得到诊断,从而错过治疗的最佳时期。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新型冠状病毒肺炎(Corona Virus Disease 2019,COVID-19),简称“新冠肺炎”。新冠肺炎的爆发,是一场世界性的灾难,经过三年全国人民的共同努力,我们终于取得抗疫的阶段性胜利。经此一役,人民对肺炎的关注达到空前高度,肺部CT检测是诊断肺炎的最佳方法,它在临床护理和流行病学研究中发挥着至关重要的作用,但是通过肺部CT影像来诊断肺炎是一项具有挑战性的任务,需要依赖放射科医师的专业能力。
肺炎患者肺部CT影像中有相应的特征表现。因此,准确识别出肺部CT影像中的肺炎影像,具有十分重要的现实意义。项目旨在使用肺炎CT数据集训练深度学习算法,以协助医生快速、准确地判断患者是否感染肺炎。
项目采用来自ka塔尔大学和孟加拉国达卡大学的一组研究人员以及来自巴基斯坦和马来西亚的合作者同医生合作,创建的一个肺炎CT数据集。包含3616例COVID-19阳性、10192例正常、6012例肺部感染和1345例病毒性肺炎。模型选用注意力卷积网络EPSANet50-S,采用热启动的余弦退火学习率优化策略,测试集准确度可达94%以上。
医学免责声明:94%仅为实验数据集上的结果,任何临床使用的算法需要在实际使用环境下进行测试,本模型结果不可作为临床诊疗依据。
模型概要
众所周知,对于浅层网络,其模型性能会随着网络层的堆叠而提升,因为非线性层增多,特征提取的能力越强,即模型拟合数据的能力越强,所以从AlexNet到VGG,深度学习模型层数越来越多。但当继续加深时,模型性能不升反降,因为更深的网络会导致梯度消失问题,从而阻碍收敛,即模型退化问题。
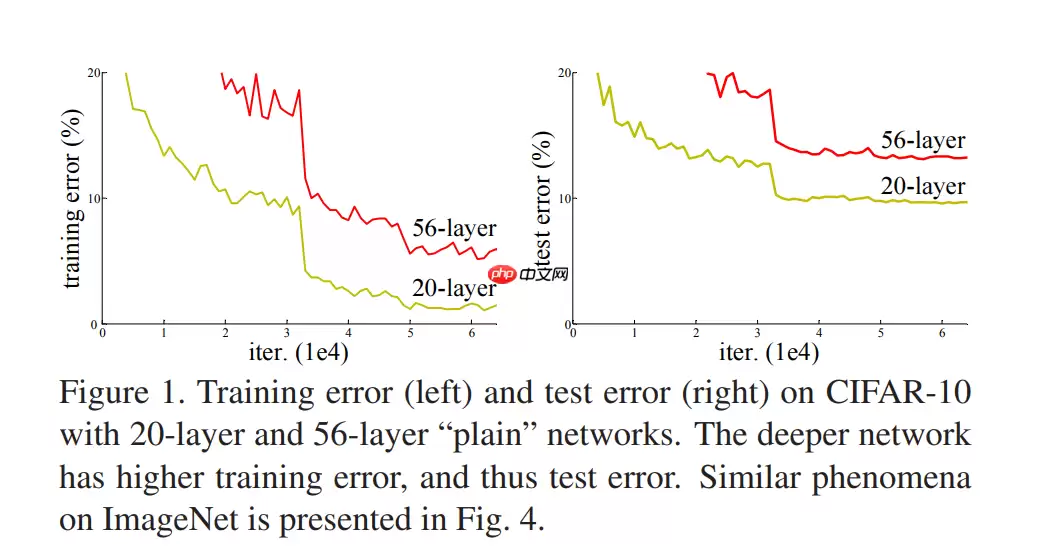
作为2015年ILSVRC比赛的冠军,ResNet在分类、检测、定位均表现优异。为解决退化问题,ResNet采用跨层连接的方法,图-2是论文中介绍的ResNet基本残差块的结构:
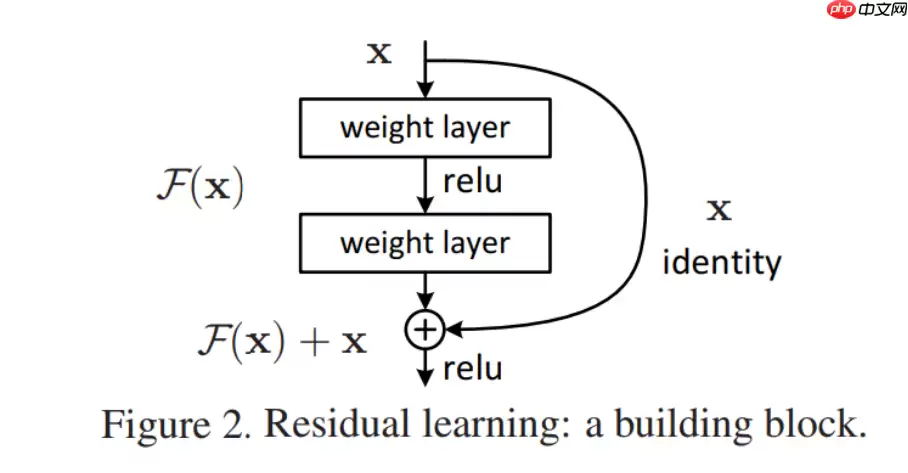
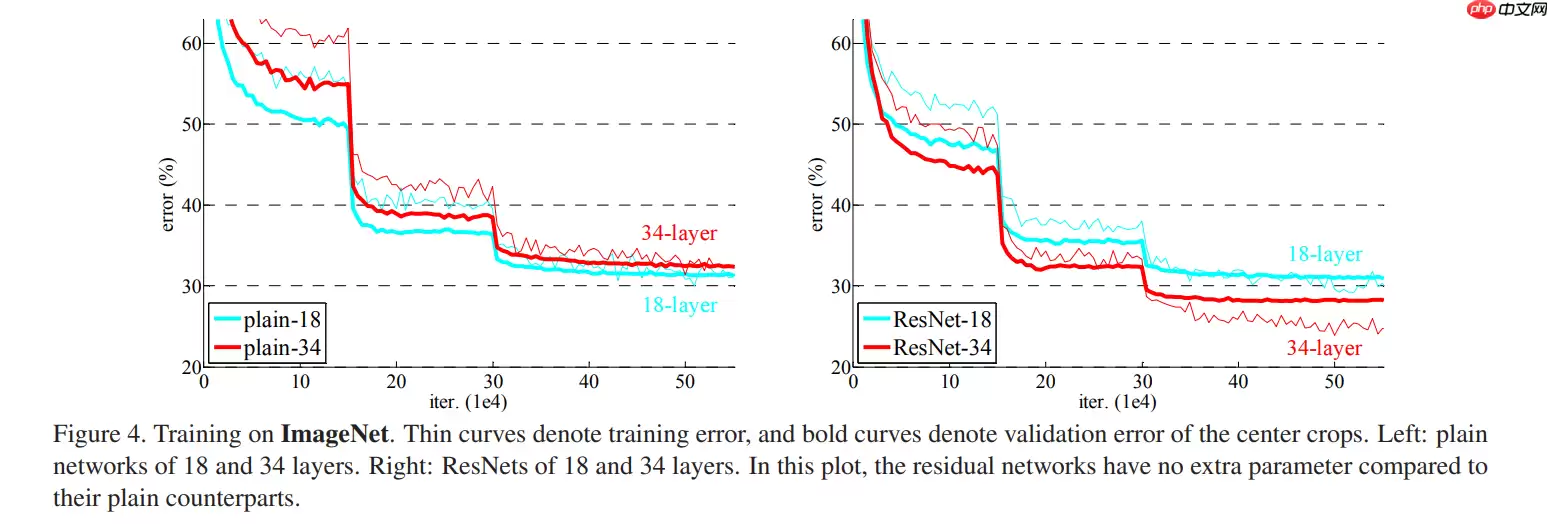
一般plain网络层输出y = F(x),而残差块residual block输出y = F(x) + x。残差块额外提供一条identity路径(short cut)。identity mapping称为恒等映射,即输入和输出是相等的。使用残差块的好处是:如果增加的层并未增加网络性能,则训练使得F(x)趋近于0,这样增加的层的输出y也趋近于输入x,相当于没有增加这个层。图-3是对比18层和34层的普通plain网络和残差块residual block的训练结果:
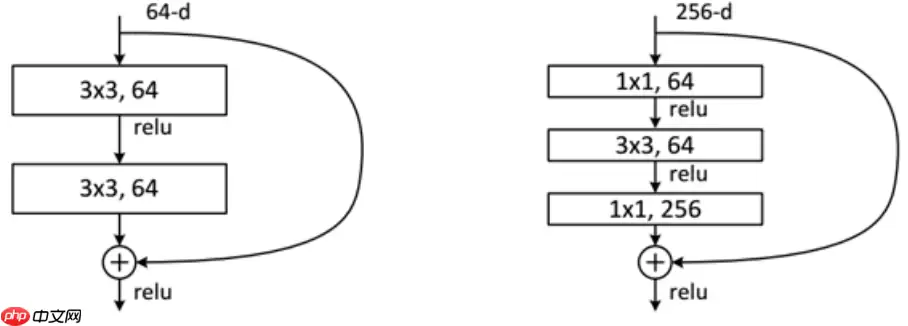
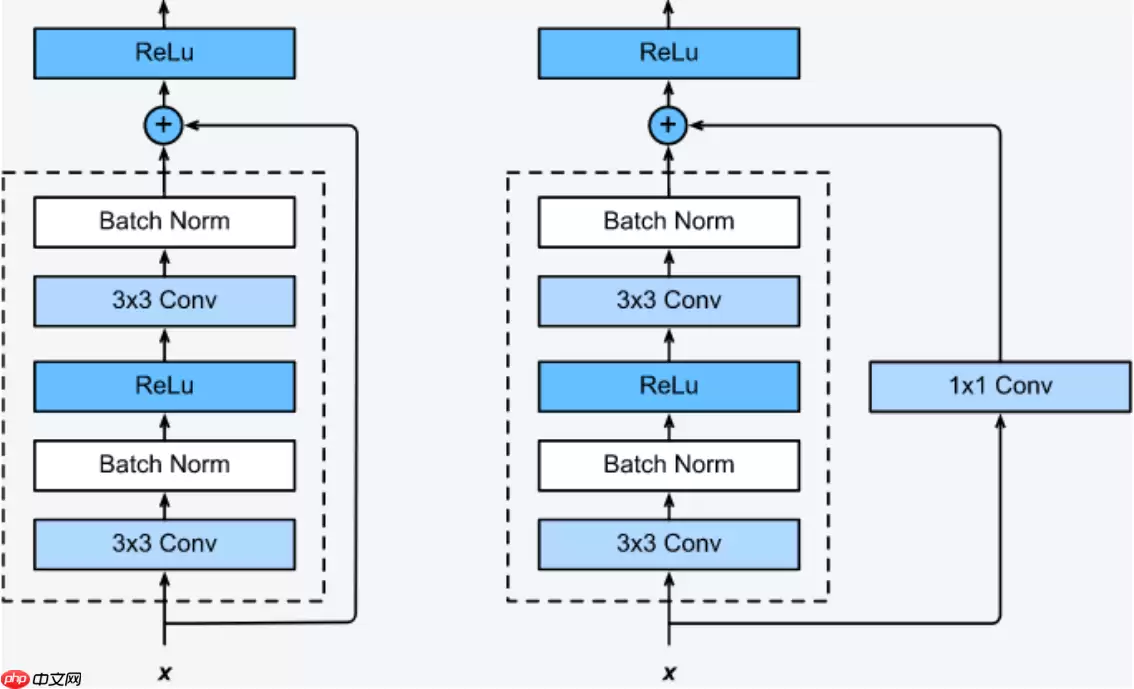
残差块分为两种,一种如图-4右侧所示的瓶颈结构(Bottleneck),Bottleneck主要用于降低计算复杂度,输入数据先经过1x1卷积层减少通道数,再经过3x3卷积层提取特征,最后经过1x1卷积层恢复通道数。通道数先减少再恢复,就像一个中间细两头粗的瓶颈,所以被称为Bottleneck。另一种如图-4左侧所示的Basic Block,由2个3×3卷积层构成。Bottleneck Block被用于ResNet50、ResNet101和ResNet152,而Basic Block被用于ResNet18和ResNet34。
short cut路径也分为两种,如图-5所示,当残差路径输出与输入的通道数和特征图尺寸均相同时,short cut路径将输入x原封不动地输出。若残差路径输出与输入的通道数或特征图尺寸不同时,short cut路径使用1x1卷积层对输入x进行调整,使得short cut路径输出与残差路径输出的通道数和特征图尺寸均相同。
已有研究表明:将注意力模块嵌入至CNN中可以带来显著的性能提升,例如SENet、BAM、CBAM、ECANet、GCNet、FcaNet等。其中SENet的缺点是其忽略空间信息的重要性,BAM和CBAM兼顾通道注意力和空间注意力,但仍然存在两个具有挑战性的问题:一是如何有效地捕获和利用不同尺度的特征图的空间信息来丰富特征空间,二是通道注意力或空间注意力只能有效地捕获局部信息,而无法建立远距离的依赖关系。后续出现的PyConv、Res2Net和HS-ResNet均用于解决这两个问题,但计算负担太过沉重。因此一种轻量高效的注意力模块PSA(Pyramid Squeeze Attention)应运而生,PSA模块可以处理多尺度特征图的空间信息并能有效地建立远距离的依赖关系。
PSA模块主要分四个步骤实现:
使用Split And Concat(SPC)得到多尺度特征图使用SEWeight提取多尺度特征图的Attention向量使用Softmax对多尺度Attention向量进行重新校准将重新校准的权重和相应的特征图进行逐元素点乘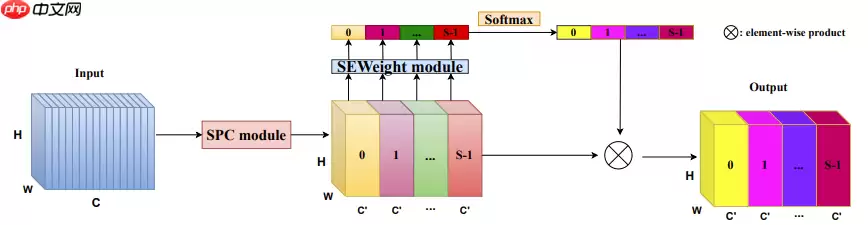
SPC模块:
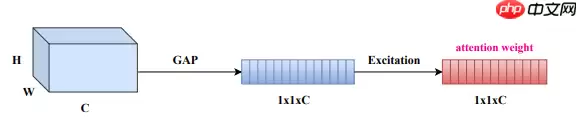
SEWeight模块:
即插即用的PSA模块替换Bottleneck Block中的3×3卷积层得到EPSA Block(Efficient Pyramid Squeeze Attention)。
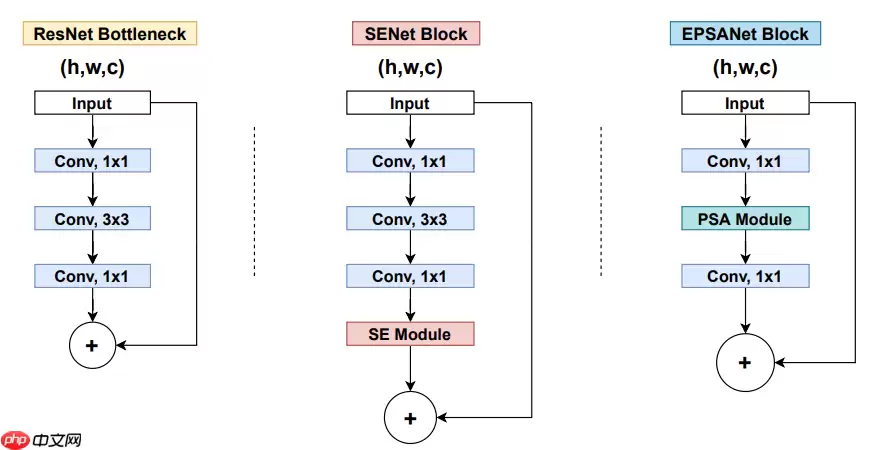
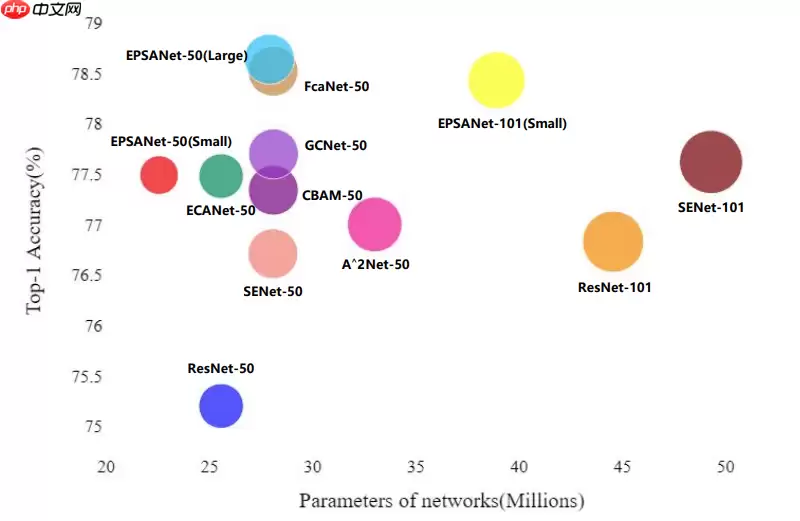
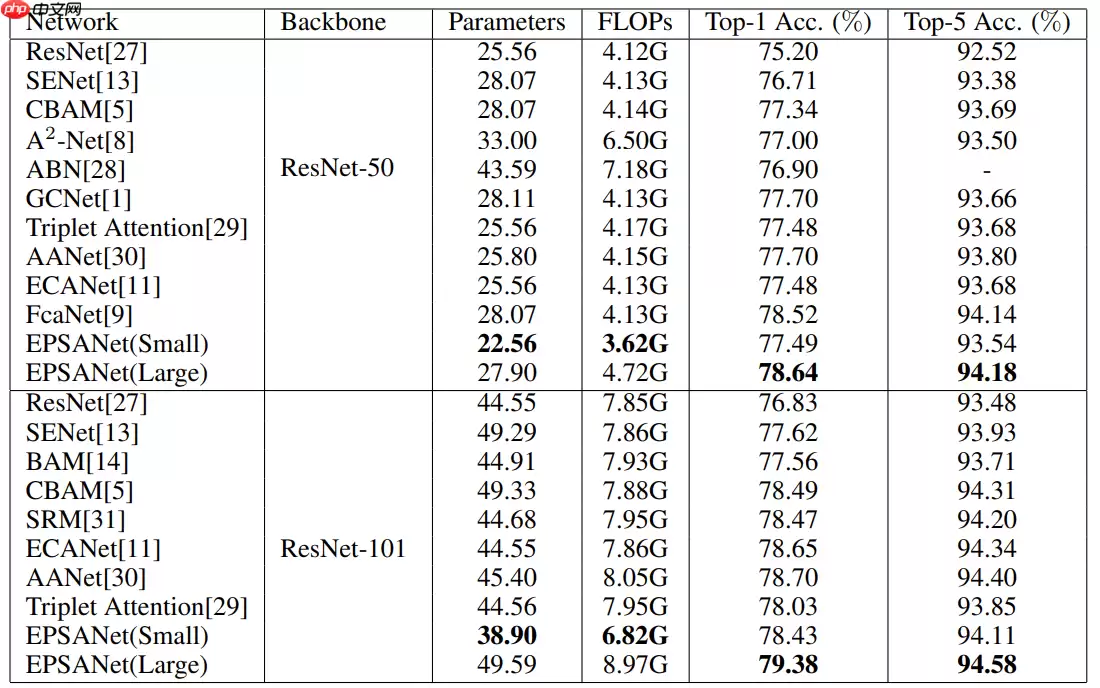
基于EPSA Block构建的注意力卷积网络EPSANet可以提供强大的多尺度特征表示能力并能自适应地重新校准跨维度通道权重。EPSANet不仅在图像分类任务Top-1 Acc上表现优秀,而且计算更加高效。如图-10所示,EPSANet分为两个版本:Small和Large,EPSANet-S的卷积核尺寸和分组尺寸分别为(3, 5, 7, 9)和(1, 4, 8, 16),而EPSANet-L拥有更大的分组尺寸:(32, 32, 32, 32)。
项目内容
In [ ]import osimport cv2import globimport paddleimport numpy as npimport prettytableimport matplotlib.pyplot as pltimport paddle.nn.functional as Ffrom paddle.io import Datasetfrom paddle.optimizer.lr import LinearWarmup, CosineAnnealingDecayfrom paddle.vision.transforms import Compose, Resize, ToTensor, Normalizefrom paddle.nn import Sequential, Conv2D, BatchNorm2D, ReLU, MaxPool2D, AdaptiveAvgPool2D, Flatten, Linear, Sigmoid, Softmax登录后复制In [ ]
# 解压数据集!unzip /home/aistudio/data/data179597/dataset.zip -d work/登录后复制In [3]
# 划分数据集base_dir = '/home/aistudio/work/dataset/'img_dirs = ['COVID', 'LungOpacity', 'Normal', 'ViralPneumonia']file_names = ['train.txt', 'val.txt', 'test.txt']splits = [0, 0.7, 0.9, 1] # 7 : 2 : 1 划分for split_idx, file_name in enumerate(file_names): with open(os.path.join('/home/aistudio/work/dataset', file_name), 'w') as f: for label, img_dir in enumerate(img_dirs): imgs = os.listdir(os.path.join(base_dir, img_dir)) for idx in range(int(splits[split_idx] * len(imgs)), int(splits[split_idx + 1] * len(imgs))): print('{} {}'.format(img_dir + '/' + imgs[idx], label), file=f)登录后复制In [4]# 计算均值和标准差def get_mean_std(img_paths): print('Total images:', len(img_paths)) mean, std = np.zeros(3), np.zeros(3) transform = Compose([Resize(size=[224, 224]), ToTensor()]) for img_path in img_paths: img = cv2.imread(img_path) img = transform(img) for c in range(3): mean[c] += img[c, :, :].mean() std[c] += img[c, :, :].std() mean /= len(img_paths) std /= len(img_paths) return mean, stdimg_paths = []img_paths.extend(glob.glob(os.path.join('work/dataset/COVID', '*.webp')))img_paths.extend(glob.glob(os.path.join('work/dataset/LungOpacity', '*.webp')))img_paths.extend(glob.glob(os.path.join('work/dataset/Normal', '*.webp')))img_paths.extend(glob.glob(os.path.join('work/dataset/ViralPneumonia', '*.webp')))mean, std = get_mean_std(img_paths)print('mean:', mean)print('std:', std)登录后复制Total images: 21165mean: [0.50897003 0.50897003 0.50897003]std: [0.23101362 0.23101362 0.23101362]登录后复制In [5]
# 自定义数据集class CTDataset(Dataset): def __init__(self, base_dir, label_path, transform=None): super(CTDataset, self).__init__() self.datas = [] with open(label_path) as f: for line in f.readlines(): img_path, label = line.strip().split(' ') img_path = os.path.join(base_dir, img_path) self.datas.append([img_path, label]) self.transform = transform # 数据处理方法 def __getitem__(self, idx): img_path, label = self.datas[idx] img = cv2.imread(img_path) if self.transform is not None: img = self.transform(img) label = np.array([int(label)]) # cross_entropy要求label格式为int return img, label def __len__(self): return len(self.datas)登录后复制In [6]# 数据预处理transform = Compose([Resize(size=[224, 224]), ToTensor(), # numpy.ndarray -> paddle.Tensor HWC -> CHW 0~255 -> 0~1 Normalize(mean=[0.509, 0.509, 0.509], std=[0.231, 0.231, 0.231], data_format='CHW')])train_dataset = CTDataset('work/dataset', 'work/dataset/train.txt', transform)val_dataset = CTDataset('work/dataset', 'work/dataset/val.txt', transform)test_dataset = CTDataset('work/dataset', 'work/dataset/test.txt', transform)print('训练集图片数量: {}\n验证集图片数量: {}\n测试集图片数量: {}'.format(len(train_dataset), len(val_dataset), len(test_dataset)))登录后复制训练集图片数量: 14814验证集图片数量: 4232测试集图片数量: 2119登录后复制
ResNet
BasicBlock
In [7]# 定义BasicBlockclass BasicBlock(paddle.nn.Layer): def __init__(self, in_channels, out_channels, stride): super(BasicBlock, self).__init__() self.conv1 = Sequential( Conv2D(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias_attr=False), # bias_attr=False 不添加偏置 BatchNorm2D(out_channels), ReLU() ) self.conv2 = Sequential( Conv2D(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias_attr=False), BatchNorm2D(out_channels) ) # 当输入通道数和输出通道数不同或特征图尺寸不同时 shortcut路径使用1x1卷积层对输入进行调整 if stride != 1 or in_channels != out_channels: self.shortcut = Sequential( Conv2D(in_channels, out_channels, kernel_size=1, stride=stride, padding=0, bias_attr=False), BatchNorm2D(out_channels) ) else: self.shortcut = Sequential() self.relu = ReLU() def forward(self, inputs): out_conv1 = self.conv1(inputs) out_conv2 = self.conv2(out_conv1) outputs = self.relu(out_conv2 + self.shortcut(inputs)) return outputs登录后复制
BottleneckBlock
In [8]# 定义BottleneckBlockclass BottleneckBlock(paddle.nn.Layer): def __init__(self, in_channels, out_channels, stride): super(BottleneckBlock, self).__init__() self.conv1 = Sequential( Conv2D(in_channels, out_channels // 4, kernel_size=1, stride=1, padding=0, bias_attr=False), BatchNorm2D(out_channels // 4), ReLU() ) self.conv2 = Sequential( Conv2D(out_channels // 4, out_channels // 4, kernel_size=3, stride=stride, padding=1, bias_attr=False), BatchNorm2D(out_channels // 4), ReLU() ) self.conv3 = Sequential( Conv2D(out_channels // 4, out_channels, kernel_size=1, stride=1, padding=0, bias_attr=False), BatchNorm2D(out_channels) ) # 当输入通道数和输出通道数不同或特征图尺寸不同时 shortcut路径使用1x1卷积层对输入进行调整 if stride != 1 or in_channels != out_channels: self.shortcut = Sequential( Conv2D(in_channels, out_channels, kernel_size=1, stride=stride, padding=0, bias_attr=False), BatchNorm2D(out_channels) ) else: self.shortcut = Sequential() self.relu = ReLU() def forward(self, inputs): out_conv1 = self.conv1(inputs) out_conv2 = self.conv2(out_conv1) out_conv3 = self.conv3(out_conv2) outputs = self.relu(out_conv3 + self.shortcut(inputs)) return outputs登录后复制In [9]
# 定义ResNetclass ResNet(paddle.nn.Layer): def __init__(self, layers, num_classes): super(ResNet, self).__init__() config = { 18: {'block_type': BasicBlock, 'num_blocks': [2, 2, 2, 2], 'out_channels': [64, 128, 256, 512]}, 34: {'block_type': BasicBlock, 'num_blocks': [3, 4, 6, 3], 'out_channels': [64, 128, 256, 512]}, 50: {'block_type': BottleneckBlock, 'num_blocks': [3, 4, 6, 3], 'out_channels': [256, 512, 1024, 2048]}, 101: {'block_type': BottleneckBlock, 'num_blocks': [3, 4, 23, 3], 'out_channels': [256, 512, 1024, 2048]}, 152: {'block_type': BottleneckBlock, 'num_blocks': [3, 8, 36, 3], 'out_channels': [256, 512, 1024, 2048]} } self.conv = Sequential( Conv2D(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias_attr=False), BatchNorm2D(64), ReLU(), ) self.max_pool = MaxPool2D(kernel_size=3, stride=2, padding=1) in_channels = 64 block_list = [] for i, block_num in enumerate(config[layers]['num_blocks']): for order in range(block_num): block_list.append(config[layers]['block_type'](in_channels, config[layers]['out_channels'][i], 2 if order == 0 and i != 0 else 1)) in_channels = config[layers]['out_channels'][i] self.block = Sequential(*block_list) self.avg_pool = AdaptiveAvgPool2D(1) # 自适应平均池化 self.flatten = Flatten() # 展平 self.fc = Linear(config[layers]['out_channels'][-1], num_classes) def forward(self, inputs): out_conv = self.conv(inputs) out_max_pool = self.max_pool(out_conv) out_block = self.block(out_max_pool) out_avg_pool = self.avg_pool(out_block) out_flatten = self.flatten(out_avg_pool) outputs = self.fc(out_flatten) return outputs登录后复制
# 查看ResNet50网络结构resnet50 = ResNet(50, 4)paddle.summary(resnet50, (1, 3, 224, 224))登录后复制
------------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # =============================================================================== Conv2D-1 [[1, 3, 224, 224]] [1, 64, 112, 112] 9,408 BatchNorm2D-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 256 ReLU-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 0 MaxPool2D-1 [[1, 64, 112, 112]] [1, 64, 56, 56] 0 Conv2D-2 [[1, 64, 56, 56]] [1, 64, 56, 56] 4,096 BatchNorm2D-2 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-2 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864 BatchNorm2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-4 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-4 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 Conv2D-5 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-5 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 ReLU-4 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 BottleneckBlock-1 [[1, 64, 56, 56]] [1, 256, 56, 56] 0 Conv2D-6 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384 BatchNorm2D-6 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-5 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-7 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864 BatchNorm2D-7 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-6 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-8 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-8 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 ReLU-7 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 BottleneckBlock-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 Conv2D-9 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384 BatchNorm2D-9 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-8 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-10 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864 BatchNorm2D-10 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-9 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-11 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-11 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 ReLU-10 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 BottleneckBlock-3 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 Conv2D-12 [[1, 256, 56, 56]] [1, 128, 56, 56] 32,768 BatchNorm2D-12 [[1, 128, 56, 56]] [1, 128, 56, 56] 512 ReLU-11 [[1, 128, 56, 56]] [1, 128, 56, 56] 0 Conv2D-13 [[1, 128, 56, 56]] [1, 128, 28, 28] 147,456 BatchNorm2D-13 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-12 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-14 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-14 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 Conv2D-15 [[1, 256, 56, 56]] [1, 512, 28, 28] 131,072 BatchNorm2D-15 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 ReLU-13 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 BottleneckBlock-4 [[1, 256, 56, 56]] [1, 512, 28, 28] 0 Conv2D-16 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536 BatchNorm2D-16 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-14 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-17 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456 BatchNorm2D-17 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-15 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-18 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-18 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 ReLU-16 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 BottleneckBlock-5 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-19 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536 BatchNorm2D-19 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-17 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-20 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456 BatchNorm2D-20 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-18 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-21 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-21 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 ReLU-19 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 BottleneckBlock-6 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-22 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536 BatchNorm2D-22 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-20 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-23 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456 BatchNorm2D-23 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-21 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-24 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-24 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 ReLU-22 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 BottleneckBlock-7 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-25 [[1, 512, 28, 28]] [1, 256, 28, 28] 131,072 BatchNorm2D-25 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024 ReLU-23 [[1, 256, 28, 28]] [1, 256, 28, 28] 0 Conv2D-26 [[1, 256, 28, 28]] [1, 256, 14, 14] 589,824 BatchNorm2D-26 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-24 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-27 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-27 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 Conv2D-28 [[1, 512, 28, 28]] [1, 1024, 14, 14] 524,288 BatchNorm2D-28 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-25 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 BottleneckBlock-8 [[1, 512, 28, 28]] [1, 1024, 14, 14] 0 Conv2D-29 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-29 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-26 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-30 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824 BatchNorm2D-30 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-27 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-31 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-31 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-28 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 BottleneckBlock-9 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-32 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-32 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-29 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-33 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824 BatchNorm2D-33 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-30 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-34 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-34 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-31 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 BottleneckBlock-10 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-35 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-35 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-32 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-36 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824 BatchNorm2D-36 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-33 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-37 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-37 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-34 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 BottleneckBlock-11 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-38 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-38 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-35 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-39 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824 BatchNorm2D-39 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-36 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-40 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-40 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-37 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 BottleneckBlock-12 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-41 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-41 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-38 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-42 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824 BatchNorm2D-42 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-39 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-43 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-43 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-40 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 BottleneckBlock-13 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-44 [[1, 1024, 14, 14]] [1, 512, 14, 14] 524,288 BatchNorm2D-44 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048 ReLU-41 [[1, 512, 14, 14]] [1, 512, 14, 14] 0 Conv2D-45 [[1, 512, 14, 14]] [1, 512, 7, 7] 2,359,296 BatchNorm2D-45 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-42 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-46 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576 BatchNorm2D-46 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 Conv2D-47 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 2,097,152 BatchNorm2D-47 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 ReLU-43 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 BottleneckBlock-14 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 0 Conv2D-48 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576 BatchNorm2D-48 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-44 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-49 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,296 BatchNorm2D-49 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-45 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-50 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576 BatchNorm2D-50 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 ReLU-46 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 BottleneckBlock-15 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 Conv2D-51 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576 BatchNorm2D-51 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-47 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-52 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,296 BatchNorm2D-52 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-48 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-53 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576 BatchNorm2D-53 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 ReLU-49 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 BottleneckBlock-16 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 AdaptiveAvgPool2D-1 [[1, 2048, 7, 7]] [1, 2048, 1, 1] 0 Flatten-1 [[1, 2048, 1, 1]] [1, 2048] 0 Linear-1 [[1, 2048]] [1, 4] 8,196 ===============================================================================Total params: 23,569,348Trainable params: 23,463,108Non-trainable params: 106,240-------------------------------------------------------------------------------Input size (MB): 0.57Forward/backward pass size (MB): 286.57Params size (MB): 89.91Estimated Total Size (MB): 377.05-------------------------------------------------------------------------------登录后复制
{'total_params': 23569348, 'trainable_params': 23463108}登录后复制EPSANet
SEWeightModule
In [11]# 定义SEWeightModuleclass SEWeightModule(paddle.nn.Layer): def __init__(self, channels, reduction=16): super(SEWeightModule, self).__init__() self.avg_pool = AdaptiveAvgPool2D(1) # 自适应平均池化 self.conv1 = Sequential( Conv2D(channels, channels // reduction, kernel_size=1, stride=1, padding=0, bias_attr=False), ReLU() ) self.conv2 = Sequential( Conv2D(channels // reduction, channels, kernel_size=1, stride=1, padding=0, bias_attr=False), Sigmoid() ) def forward(self, inputs): out_avg_pool = self.avg_pool(inputs) out_conv1 = self.conv1(out_avg_pool) outputs = self.conv2(out_conv1) return outputs登录后复制
PSAModule
In [12]# 定义PSAModuleclass PSAModule(paddle.nn.Layer): def __init__(self, in_channels, out_channels, stride, conv_kernels, conv_groups): super(PSAModule, self).__init__() self.conv1 = Conv2D(in_channels, out_channels // 4, kernel_size=conv_kernels[0], stride=stride, padding=conv_kernels[0] // 2, groups=conv_groups[0], bias_attr=False) self.conv2 = Conv2D(in_channels, out_channels // 4, kernel_size=conv_kernels[1], stride=stride, padding=conv_kernels[1] // 2, groups=conv_groups[1], bias_attr=False) self.conv3 = Conv2D(in_channels, out_channels // 4, kernel_size=conv_kernels[2], stride=stride, padding=conv_kernels[2] // 2, groups=conv_groups[2], bias_attr=False) self.conv4 = Conv2D(in_channels, out_channels // 4, kernel_size=conv_kernels[3], stride=stride, padding=conv_kernels[3] // 2, groups=conv_groups[3], bias_attr=False) self.se = SEWeightModule(out_channels // 4) self.split_channel = out_channels // 4 self.softmax = Softmax(axis=1) def forward(self, inputs): # stage 1 batch_size = inputs.shape[0] out_conv1 = self.conv1(inputs) out_conv2 = self.conv2(inputs) out_conv3 = self.conv3(inputs) out_conv4 = self.conv4(inputs) feature = paddle.concat((out_conv1, out_conv2, out_conv3, out_conv4), axis=1) feature = feature.reshape([batch_size, 4, self.split_channel, feature.shape[2], feature.shape[3]]) # stage 2 out_se1 = self.se(out_conv1) out_se2 = self.se(out_conv2) out_se3 = self.se(out_conv3) out_se4 = self.se(out_conv4) attention = paddle.concat((out_se1, out_se2, out_se3, out_se4), axis=1) attention = attention.reshape([batch_size, 4, self.split_channel, 1, 1]) # stage 3 attention = self.softmax(attention) # stage 4 weight_feature = feature * attention for i in range(4): x = weight_feature[:, i, :, :, :] if i == 0: outputs = x else: outputs = paddle.concat((outputs, x), axis=1) return outputs登录后复制
EPSABlock
In [13]# 定义EPSABlockclass EPSABlock(paddle.nn.Layer): def __init__(self, in_channels, out_channels, stride, conv_kernels, conv_groups, reduction): super(EPSABlock, self).__init__() self.conv1 = Sequential( Conv2D(in_channels, out_channels // reduction, kernel_size=1, stride=1, padding=0, bias_attr=False), BatchNorm2D(out_channels // reduction), ReLU() ) self.conv2 = Sequential( PSAModule(out_channels // reduction, out_channels // reduction, conv_kernels=conv_kernels, stride=stride, conv_groups=conv_groups), # 3x3卷积 -> PSAModule BatchNorm2D(out_channels // reduction), ReLU() ) self.conv3 = Sequential( Conv2D(out_channels // reduction, out_channels, kernel_size=1, stride=1, padding=0, bias_attr=False), BatchNorm2D(out_channels) ) # 当输入通道数和输出通道数不同或特征图尺寸不同时 shortcut路径使用1x1卷积层对输入进行调整 if stride != 1 or in_channels != out_channels: self.shortcut = Sequential( Conv2D(in_channels, out_channels, kernel_size=1, stride=stride, padding=0, bias_attr=False), BatchNorm2D(out_channels) ) else: self.shortcut = Sequential() self.relu = ReLU() def forward(self, inputs): out_conv1 = self.conv1(inputs) out_conv2 = self.conv2(out_conv1) out_conv3 = self.conv3(out_conv2) outputs = self.relu(out_conv3 + self.shortcut(inputs)) return outputs登录后复制In [14]
# 定义EPSANetclass EPSANet(paddle.nn.Layer): def __init__(self, layers, num_classes, conv_kernels=[3, 5, 7, 9], conv_groups=[1, 4, 8, 16], reduction=4): super(EPSANet, self).__init__() config = { 50: {'block_type': EPSABlock, 'num_blocks': [3, 4, 6, 3], 'out_channels': [256, 512, 1024, 2048]}, 101: {'block_type': EPSABlock, 'num_blocks': [3, 4, 23, 3], 'out_channels': [256, 512, 1024, 2048]}, 152: {'block_type': EPSABlock, 'num_blocks': [3, 8, 36, 3], 'out_channels': [256, 512, 1024, 2048]} } self.conv = Sequential( Conv2D(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias_attr=False), BatchNorm2D(64), ReLU(), ) self.max_pool = MaxPool2D(kernel_size=3, stride=2, padding=1) in_channels = 64 block_list = [] for i, block_num in enumerate(config[layers]['num_blocks']): for order in range(block_num): block_list.append(config[layers]['block_type'](in_channels, config[layers]['out_channels'][i], 2 if order == 0 and i != 0 else 1, conv_kernels=conv_kernels, conv_groups=conv_groups, reduction=reduction)) in_channels = config[layers]['out_channels'][i] self.block = Sequential(*block_list) self.avg_pool = AdaptiveAvgPool2D(1) # 自适应平均池化 self.flatten = Flatten() # 展平 self.fc = Linear(config[layers]['out_channels'][-1], num_classes) def forward(self, inputs): out_conv = self.conv(inputs) out_max_pool = self.max_pool(out_conv) out_block = self.block(out_max_pool) out_avg_pool = self.avg_pool(out_block) out_flatten = self.flatten(out_avg_pool) outputs = self.fc(out_flatten) return outputs登录后复制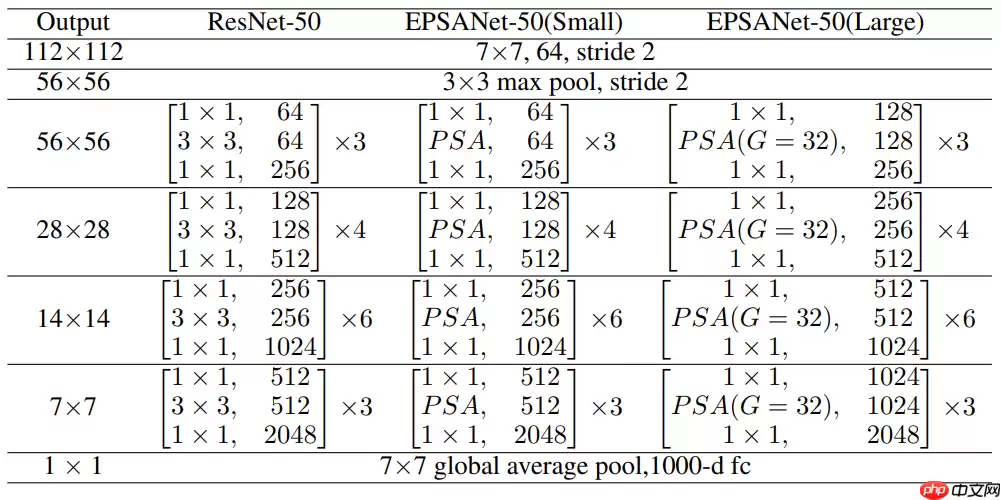
# 查看EPSANet50-S网络结构epsanet50 = EPSANet(50, 4)paddle.summary(epsanet50, (1, 3, 224, 224))登录后复制
-------------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # ================================================================================ Conv2D-54 [[1, 3, 224, 224]] [1, 64, 112, 112] 9,408 BatchNorm2D-54 [[1, 64, 112, 112]] [1, 64, 112, 112] 256 ReLU-50 [[1, 64, 112, 112]] [1, 64, 112, 112] 0 MaxPool2D-2 [[1, 64, 112, 112]] [1, 64, 56, 56] 0 Conv2D-55 [[1, 64, 56, 56]] [1, 64, 56, 56] 4,096 BatchNorm2D-55 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-51 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-56 [[1, 64, 56, 56]] [1, 16, 56, 56] 9,216 Conv2D-57 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,400 Conv2D-58 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,272 Conv2D-59 [[1, 64, 56, 56]] [1, 16, 56, 56] 5,184 AdaptiveAvgPool2D-2 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Conv2D-60 [[1, 16, 1, 1]] [1, 1, 1, 1] 16 ReLU-52 [[1, 1, 1, 1]] [1, 1, 1, 1] 0 Conv2D-61 [[1, 1, 1, 1]] [1, 16, 1, 1] 16 Sigmoid-1 [[1, 16, 1, 1]] [1, 16, 1, 1] 0 SEWeightModule-1 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Softmax-1 [[1, 4, 16, 1, 1]] [1, 4, 16, 1, 1] 0 PSAModule-1 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 BatchNorm2D-56 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-53 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-62 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-57 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 Conv2D-63 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-58 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 ReLU-54 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 EPSABlock-1 [[1, 64, 56, 56]] [1, 256, 56, 56] 0 Conv2D-64 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384 BatchNorm2D-59 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-55 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-65 [[1, 64, 56, 56]] [1, 16, 56, 56] 9,216 Conv2D-66 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,400 Conv2D-67 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,272 Conv2D-68 [[1, 64, 56, 56]] [1, 16, 56, 56] 5,184 AdaptiveAvgPool2D-3 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Conv2D-69 [[1, 16, 1, 1]] [1, 1, 1, 1] 16 ReLU-56 [[1, 1, 1, 1]] [1, 1, 1, 1] 0 Conv2D-70 [[1, 1, 1, 1]] [1, 16, 1, 1] 16 Sigmoid-2 [[1, 16, 1, 1]] [1, 16, 1, 1] 0 SEWeightModule-2 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Softmax-2 [[1, 4, 16, 1, 1]] [1, 4, 16, 1, 1] 0 PSAModule-2 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 BatchNorm2D-60 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-57 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-71 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-61 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 ReLU-58 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 EPSABlock-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 Conv2D-72 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384 BatchNorm2D-62 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-59 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-73 [[1, 64, 56, 56]] [1, 16, 56, 56] 9,216 Conv2D-74 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,400 Conv2D-75 [[1, 64, 56, 56]] [1, 16, 56, 56] 6,272 Conv2D-76 [[1, 64, 56, 56]] [1, 16, 56, 56] 5,184 AdaptiveAvgPool2D-4 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Conv2D-77 [[1, 16, 1, 1]] [1, 1, 1, 1] 16 ReLU-60 [[1, 1, 1, 1]] [1, 1, 1, 1] 0 Conv2D-78 [[1, 1, 1, 1]] [1, 16, 1, 1] 16 Sigmoid-3 [[1, 16, 1, 1]] [1, 16, 1, 1] 0 SEWeightModule-3 [[1, 16, 56, 56]] [1, 16, 1, 1] 0 Softmax-3 [[1, 4, 16, 1, 1]] [1, 4, 16, 1, 1] 0 PSAModule-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 BatchNorm2D-63 [[1, 64, 56, 56]] [1, 64, 56, 56] 256 ReLU-61 [[1, 64, 56, 56]] [1, 64, 56, 56] 0 Conv2D-79 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384 BatchNorm2D-64 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024 ReLU-62 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 EPSABlock-3 [[1, 256, 56, 56]] [1, 256, 56, 56] 0 Conv2D-80 [[1, 256, 56, 56]] [1, 128, 56, 56] 32,768 BatchNorm2D-65 [[1, 128, 56, 56]] [1, 128, 56, 56] 512 ReLU-63 [[1, 128, 56, 56]] [1, 128, 56, 56] 0 Conv2D-81 [[1, 128, 56, 56]] [1, 32, 28, 28] 36,864 Conv2D-82 [[1, 128, 56, 56]] [1, 32, 28, 28] 25,600 Conv2D-83 [[1, 128, 56, 56]] [1, 32, 28, 28] 25,088 Conv2D-84 [[1, 128, 56, 56]] [1, 32, 28, 28] 20,736 AdaptiveAvgPool2D-5 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Conv2D-85 [[1, 32, 1, 1]] [1, 2, 1, 1] 64 ReLU-64 [[1, 2, 1, 1]] [1, 2, 1, 1] 0 Conv2D-86 [[1, 2, 1, 1]] [1, 32, 1, 1] 64 Sigmoid-4 [[1, 32, 1, 1]] [1, 32, 1, 1] 0 SEWeightModule-4 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Softmax-4 [[1, 4, 32, 1, 1]] [1, 4, 32, 1, 1] 0 PSAModule-4 [[1, 128, 56, 56]] [1, 128, 28, 28] 0 BatchNorm2D-66 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-65 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-87 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-67 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 Conv2D-88 [[1, 256, 56, 56]] [1, 512, 28, 28] 131,072 BatchNorm2D-68 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 ReLU-66 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 EPSABlock-4 [[1, 256, 56, 56]] [1, 512, 28, 28] 0 Conv2D-89 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536 BatchNorm2D-69 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-67 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-90 [[1, 128, 28, 28]] [1, 32, 28, 28] 36,864 Conv2D-91 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,600 Conv2D-92 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,088 Conv2D-93 [[1, 128, 28, 28]] [1, 32, 28, 28] 20,736 AdaptiveAvgPool2D-6 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Conv2D-94 [[1, 32, 1, 1]] [1, 2, 1, 1] 64 ReLU-68 [[1, 2, 1, 1]] [1, 2, 1, 1] 0 Conv2D-95 [[1, 2, 1, 1]] [1, 32, 1, 1] 64 Sigmoid-5 [[1, 32, 1, 1]] [1, 32, 1, 1] 0 SEWeightModule-5 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Softmax-5 [[1, 4, 32, 1, 1]] [1, 4, 32, 1, 1] 0 PSAModule-5 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 BatchNorm2D-70 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-69 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-96 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-71 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 ReLU-70 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 EPSABlock-5 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-97 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536 BatchNorm2D-72 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-71 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-98 [[1, 128, 28, 28]] [1, 32, 28, 28] 36,864 Conv2D-99 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,600 Conv2D-100 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,088 Conv2D-101 [[1, 128, 28, 28]] [1, 32, 28, 28] 20,736 AdaptiveAvgPool2D-7 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Conv2D-102 [[1, 32, 1, 1]] [1, 2, 1, 1] 64 ReLU-72 [[1, 2, 1, 1]] [1, 2, 1, 1] 0 Conv2D-103 [[1, 2, 1, 1]] [1, 32, 1, 1] 64 Sigmoid-6 [[1, 32, 1, 1]] [1, 32, 1, 1] 0 SEWeightModule-6 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Softmax-6 [[1, 4, 32, 1, 1]] [1, 4, 32, 1, 1] 0 PSAModule-6 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 BatchNorm2D-73 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-73 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-104 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-74 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 ReLU-74 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 EPSABlock-6 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-105 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536 BatchNorm2D-75 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-75 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-106 [[1, 128, 28, 28]] [1, 32, 28, 28] 36,864 Conv2D-107 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,600 Conv2D-108 [[1, 128, 28, 28]] [1, 32, 28, 28] 25,088 Conv2D-109 [[1, 128, 28, 28]] [1, 32, 28, 28] 20,736 AdaptiveAvgPool2D-8 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Conv2D-110 [[1, 32, 1, 1]] [1, 2, 1, 1] 64 ReLU-76 [[1, 2, 1, 1]] [1, 2, 1, 1] 0 Conv2D-111 [[1, 2, 1, 1]] [1, 32, 1, 1] 64 Sigmoid-7 [[1, 32, 1, 1]] [1, 32, 1, 1] 0 SEWeightModule-7 [[1, 32, 28, 28]] [1, 32, 1, 1] 0 Softmax-7 [[1, 4, 32, 1, 1]] [1, 4, 32, 1, 1] 0 PSAModule-7 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 BatchNorm2D-76 [[1, 128, 28, 28]] [1, 128, 28, 28] 512 ReLU-77 [[1, 128, 28, 28]] [1, 128, 28, 28] 0 Conv2D-112 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536 BatchNorm2D-77 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048 ReLU-78 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 EPSABlock-7 [[1, 512, 28, 28]] [1, 512, 28, 28] 0 Conv2D-113 [[1, 512, 28, 28]] [1, 256, 28, 28] 131,072 BatchNorm2D-78 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024 ReLU-79 [[1, 256, 28, 28]] [1, 256, 28, 28] 0 Conv2D-114 [[1, 256, 28, 28]] [1, 64, 14, 14] 147,456 Conv2D-115 [[1, 256, 28, 28]] [1, 64, 14, 14] 102,400 Conv2D-116 [[1, 256, 28, 28]] [1, 64, 14, 14] 100,352 Conv2D-117 [[1, 256, 28, 28]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-9 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-118 [[1, 64, 1, 1]] [1, 4, 1, 1] 256 ReLU-80 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-119 [[1, 4, 1, 1]] [1, 64, 1, 1] 256 Sigmoid-8 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-8 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-8 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-8 [[1, 256, 28, 28]] [1, 256, 14, 14] 0 BatchNorm2D-79 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-81 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-120 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-80 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 Conv2D-121 [[1, 512, 28, 28]] [1, 1024, 14, 14] 524,288 BatchNorm2D-81 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-82 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 EPSABlock-8 [[1, 512, 28, 28]] [1, 1024, 14, 14] 0 Conv2D-122 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-82 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-83 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-123 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-124 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-125 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-126 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-10 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-127 [[1, 64, 1, 1]] [1, 4, 1, 1] 256 ReLU-84 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-128 [[1, 4, 1, 1]] [1, 64, 1, 1] 256 Sigmoid-9 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-9 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-9 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-9 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-83 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-85 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-129 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-84 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-86 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 EPSABlock-9 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-130 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-85 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-87 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-131 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-132 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-133 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-134 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-11 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-135 [[1, 64, 1, 1]] [1, 4, 1, 1] 256 ReLU-88 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-136 [[1, 4, 1, 1]] [1, 64, 1, 1] 256 Sigmoid-10 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-10 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-10 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-10 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-86 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-89 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-137 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-87 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-90 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 EPSABlock-10 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-138 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-88 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-91 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-139 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-140 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-141 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-142 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-12 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-143 [[1, 64, 1, 1]] [1, 4, 1, 1] 256 ReLU-92 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-144 [[1, 4, 1, 1]] [1, 64, 1, 1] 256 Sigmoid-11 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-11 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-11 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-11 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-89 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-93 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-145 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-90 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-94 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 EPSABlock-11 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-146 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-91 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-95 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-147 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-148 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-149 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-150 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-13 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-151 [[1, 64, 1, 1]] [1, 4, 1, 1] 256 ReLU-96 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-152 [[1, 4, 1, 1]] [1, 64, 1, 1] 256 Sigmoid-12 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-12 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-12 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-12 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-92 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-97 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-153 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-93 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-98 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 EPSABlock-12 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-154 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144 BatchNorm2D-94 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-99 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-155 [[1, 256, 14, 14]] [1, 64, 14, 14] 147,456 Conv2D-156 [[1, 256, 14, 14]] [1, 64, 14, 14] 102,400 Conv2D-157 [[1, 256, 14, 14]] [1, 64, 14, 14] 100,352 Conv2D-158 [[1, 256, 14, 14]] [1, 64, 14, 14] 82,944 AdaptiveAvgPool2D-14 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Conv2D-159 [[1, 64, 1, 1]] [1, 4, 1, 1] 256 ReLU-100 [[1, 4, 1, 1]] [1, 4, 1, 1] 0 Conv2D-160 [[1, 4, 1, 1]] [1, 64, 1, 1] 256 Sigmoid-13 [[1, 64, 1, 1]] [1, 64, 1, 1] 0 SEWeightModule-13 [[1, 64, 14, 14]] [1, 64, 1, 1] 0 Softmax-13 [[1, 4, 64, 1, 1]] [1, 4, 64, 1, 1] 0 PSAModule-13 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 BatchNorm2D-95 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024 ReLU-101 [[1, 256, 14, 14]] [1, 256, 14, 14] 0 Conv2D-161 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144 BatchNorm2D-96 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096 ReLU-102 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 EPSABlock-13 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0 Conv2D-162 [[1, 1024, 14, 14]] [1, 512, 14, 14] 524,288 BatchNorm2D-97 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048 ReLU-103 [[1, 512, 14, 14]] [1, 512, 14, 14] 0 Conv2D-163 [[1, 512, 14, 14]] [1, 128, 7, 7] 589,824 Conv2D-164 [[1, 512, 14, 14]] [1, 128, 7, 7] 409,600 Conv2D-165 [[1, 512, 14, 14]] [1, 128, 7, 7] 401,408 Conv2D-166 [[1, 512, 14, 14]] [1, 128, 7, 7] 331,776 AdaptiveAvgPool2D-15 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Conv2D-167 [[1, 128, 1, 1]] [1, 8, 1, 1] 1,024 ReLU-104 [[1, 8, 1, 1]] [1, 8, 1, 1] 0 Conv2D-168 [[1, 8, 1, 1]] [1, 128, 1, 1] 1,024 Sigmoid-14 [[1, 128, 1, 1]] [1, 128, 1, 1] 0 SEWeightModule-14 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Softmax-14 [[1, 4, 128, 1, 1]] [1, 4, 128, 1, 1] 0 PSAModule-14 [[1, 512, 14, 14]] [1, 512, 7, 7] 0 BatchNorm2D-98 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-105 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-169 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576 BatchNorm2D-99 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 Conv2D-170 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 2,097,152 BatchNorm2D-100 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 ReLU-106 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 EPSABlock-14 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 0 Conv2D-171 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576 BatchNorm2D-101 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-107 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-172 [[1, 512, 7, 7]] [1, 128, 7, 7] 589,824 Conv2D-173 [[1, 512, 7, 7]] [1, 128, 7, 7] 409,600 Conv2D-174 [[1, 512, 7, 7]] [1, 128, 7, 7] 401,408 Conv2D-175 [[1, 512, 7, 7]] [1, 128, 7, 7] 331,776 AdaptiveAvgPool2D-16 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Conv2D-176 [[1, 128, 1, 1]] [1, 8, 1, 1] 1,024 ReLU-108 [[1, 8, 1, 1]] [1, 8, 1, 1] 0 Conv2D-177 [[1, 8, 1, 1]] [1, 128, 1, 1] 1,024 Sigmoid-15 [[1, 128, 1, 1]] [1, 128, 1, 1] 0 SEWeightModule-15 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Softmax-15 [[1, 4, 128, 1, 1]] [1, 4, 128, 1, 1] 0 PSAModule-15 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 BatchNorm2D-102 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-109 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-178 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576 BatchNorm2D-103 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 ReLU-110 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 EPSABlock-15 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 Conv2D-179 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576 BatchNorm2D-104 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-111 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-180 [[1, 512, 7, 7]] [1, 128, 7, 7] 589,824 Conv2D-181 [[1, 512, 7, 7]] [1, 128, 7, 7] 409,600 Conv2D-182 [[1, 512, 7, 7]] [1, 128, 7, 7] 401,408 Conv2D-183 [[1, 512, 7, 7]] [1, 128, 7, 7] 331,776 AdaptiveAvgPool2D-17 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Conv2D-184 [[1, 128, 1, 1]] [1, 8, 1, 1] 1,024 ReLU-112 [[1, 8, 1, 1]] [1, 8, 1, 1] 0 Conv2D-185 [[1, 8, 1, 1]] [1, 128, 1, 1] 1,024 Sigmoid-16 [[1, 128, 1, 1]] [1, 128, 1, 1] 0 SEWeightModule-16 [[1, 128, 7, 7]] [1, 128, 1, 1] 0 Softmax-16 [[1, 4, 128, 1, 1]] [1, 4, 128, 1, 1] 0 PSAModule-16 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 BatchNorm2D-105 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048 ReLU-113 [[1, 512, 7, 7]] [1, 512, 7, 7] 0 Conv2D-186 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576 BatchNorm2D-106 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192 ReLU-114 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 EPSABlock-16 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0 AdaptiveAvgPool2D-18 [[1, 2048, 7, 7]] [1, 2048, 1, 1] 0 Flatten-2 [[1, 2048, 1, 1]] [1, 2048] 0 Linear-2 [[1, 2048]] [1, 4] 8,196 ================================================================================Total params: 20,573,028Trainable params: 20,466,788Non-trainable params: 106,240--------------------------------------------------------------------------------Input size (MB): 0.57Forward/backward pass size (MB): 297.15Params size (MB): 78.48Estimated Total Size (MB): 376.21--------------------------------------------------------------------------------登录后复制
{'total_params': 20573028, 'trainable_params': 20466788}登录后复制CosineWarmup
Momentum优化器:
如果初始学习率设置得当并且迭代轮数充足,该优化器会在众多的优化器中脱颖而出,使其在验证集上获得更高的准确率。但Momentum优化器有两个缺点,一是收敛速度慢(较之Adam、AdamW等自适应优化器),二是初始学习率的设置需要依靠大量经验。
Warmup:
Warmup是在ResNet论文中提到的一种学习率预热方法,它在训练开始时先使用一个较小的学习率训练一些epochs或者steps,再修改为预先设置的学习率进行训练。由于刚开始训练时,模型的权重是随机初始化的,若此时选择一个较大的学习率,可能会导致模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练时的一些epochs或者steps内学习率较小,在小的学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度更快,模型效果更佳。
余弦退火策略:
在使用梯度下降算法来优化目标函数时,当越来越接近loss的全局最小值时,学习率应该变得更小来使得模型尽可能接近这一最低点,而余弦退火(Cosine annealing)可以通过余弦函数来降低学习率。余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,最后缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
热启动的余弦退火学习率优化策略CosineWarmup非常实用,本项目选择使用Momentum优化器加CosineWarmup策略的组合替换传统SGD优化器。
In [16]# 热启动的余弦退火学习率优化策略class Cosine(CosineAnnealingDecay): def __init__(self, learning_rate, step_each_epoch, epoch_num, **kwargs): super(Cosine, self).__init__(learning_rate=learning_rate, T_max=step_each_epoch * epoch_num)class CosineWarmup(LinearWarmup): def __init__(self, learning_rate, step_each_epoch, epoch_num, warmup_epoch_num=5, **kwargs): assert epoch_num > warmup_epoch_num, 'epoch_num({}) should be larger than warmup_epoch_num({}) in CosineWarmup.'.format(epoch_num, warmup_epoch_num) warmup_steps = warmup_epoch_num * step_each_epoch start_lr = 0.0 end_lr = learning_rate learning_rate = Cosine(learning_rate, step_each_epoch, epoch_num - warmup_epoch_num) super(CosineWarmup, self).__init__(learning_rate=learning_rate, warmup_steps=warmup_steps, start_lr=start_lr, end_lr=end_lr)登录后复制train
In [17]# 训练def train(model, name='model'): epoch_num = 50 batch_size = 50 learning_rate = 0.01 train_loss_list = [] train_acc_list = [] eval_loss_list = [] eval_acc_list = [] iter = 0 iters = [] epochs = [] max_eval_acc = 0 model.train() train_loader = paddle.io.DataLoader(train_dataset, batch_size=batch_size, shuffle=True) val_loader = paddle.io.DataLoader(val_dataset, batch_size=batch_size) scheduler = CosineWarmup(learning_rate=learning_rate, step_each_epoch=int(len(train_dataset) / batch_size), epoch_num=epoch_num, verbose=True) opt = paddle.optimizer.Momentum(learning_rate=scheduler, weight_decay=paddle.regularizer.L2Decay(0.0005), parameters=model.parameters()) # Momentum + CosineWarmup for epoch_id in range(epoch_num): for batch_id, (images, labels) in enumerate(train_loader()): predicts = model(images) loss = F.cross_entropy(predicts, labels) acc = paddle.metric.accuracy(predicts, labels) if batch_id % 10 == 0: train_loss_list.append(loss.item()) train_acc_list.append(acc.item()) iters.append(iter) iter += 10 print('epoch: {}, batch: {}, learning_rate: {}, \ntrain loss is: {}, train acc is: {}'.format(epoch_id, batch_id, opt.get_lr(), loss.item(), acc.item())) loss.backward() # 反向传播 opt.step() # 更新参数 opt.clear_grad() # 清除梯度 scheduler.step() # 更新参数 # 每个epoch评估一次 model.eval() loss_list = [] acc_list = [] results = np.zeros([4, 4], dtype='int64') for batch_id, (images, labels) in enumerate(val_loader()): predicts = model(images) for i in range(len(images)): results[labels[i].item()][paddle.argmax(predicts[i]).item()] += 1 loss = F.cross_entropy(predicts, labels) acc = paddle.metric.accuracy(predicts, labels) loss_list.append(loss.item()) acc_list.append(acc.item()) eval_loss, eval_acc = np.mean(loss_list), np.mean(acc_list) eval_loss_list.append(eval_loss) eval_acc_list.append(eval_acc) epochs.append(epoch_id) model.train() print('eval loss: {}, eval acc: {}'.format(eval_loss, eval_acc)) # 保存最优模型 if eval_acc > max_eval_acc: paddle.save(model.state_dict(), '{}.pdparams'.format(name)) max_eval_acc = eval_acc results_table = prettytable.PrettyTable() results_table.field_names = ['Type', 'Precision', 'Recall', 'F1_Score'] class_names = ['COVID', 'LungOpacity', 'Normal', 'ViralPneumonia'] for i in range(4): precision = results[i][i] / results.sum(axis=0)[i] recall = results[i][i] / results.sum(axis=1)[i] results_table.add_row([class_names[i], np.round(precision, 3), np.round(recall, 3), np.round(precision * recall * 2 / (precision + recall), 3)]) print(results_table) return train_loss_list, train_acc_list, eval_loss_list, eval_acc_list, iters, epochs登录后复制In [ ]resnet50 = ResNet(50, 4)resnet50_train_loss, resnet50_train_acc, resnet50_eval_loss, resnet50_eval_acc, iters, epochs = train(resnet50, 'resnet50')登录后复制In [ ]
epsanet50 = EPSANet(50, 4)epsanet50_train_loss, epsanet50_train_acc, epsanet50_eval_loss, epsanet50_eval_acc, iters, epochs = train(epsanet50, 'epsanet50')登录后复制In [21]
# 训练过程可视化def plot(freq, list, color, name, xlabel, ylabel, title): plt.figure() plt.title(title, fontsize='x-large') plt.xlabel(xlabel, fontsize='large') plt.ylabel(ylabel, fontsize='large') for i in range(len(list)): plt.plot(freq, list[i], color=color[i]) plt.legend(name) plt.grid() plt.show()plot(iters, [resnet50_train_loss, epsanet50_train_loss], ['blue', 'green'], ['resnet50', 'epsanet50'], 'iter', 'loss', 'train loss')plot(iters, [resnet50_train_acc, epsanet50_train_acc], ['blue', 'green'], ['resnet50', 'epsanet50'], 'iter', 'acc', 'train acc')plot(epochs, [resnet50_eval_loss, epsanet50_eval_loss], ['blue', 'green'], ['resnet50', 'epsanet50'], 'epoch', 'loss', 'eval loss')plot(epochs, [resnet50_eval_acc, epsanet50_eval_acc], ['blue', 'green'], ['resnet50', 'epsanet50'], 'epoch', 'acc', 'eval acc')登录后复制
登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制
登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制
登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制
登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制
eval
In [22]# 评估def eval(model, name='model'): batch_size = 50 loss_list = [] acc_list = [] results = np.zeros([4, 4], dtype='int64') params_file_path = '{}.pdparams'.format(name) # 加载模型参数 param_dict = paddle.load(params_file_path) model.load_dict(param_dict) model.eval() test_loader = paddle.io.DataLoader(test_dataset, batch_size=batch_size) for batch_id, (images, labels) in enumerate(test_loader()): predicts = model(images) for i in range(len(images)): results[labels[i].item()][paddle.argmax(predicts[i]).item()] += 1 loss = F.cross_entropy(predicts, labels) acc = paddle.metric.accuracy(predicts, labels) loss_list.append(loss.item()) acc_list.append(acc.item()) eval_loss, eval_acc = np.mean(loss_list), np.mean(acc_list) print('eval_loss: {}, eval_acc: {}'.format(eval_loss, eval_acc)) results_table = prettytable.PrettyTable() results_table.field_names = ['Type', 'Precision', 'Recall', 'F1_Score'] class_names = ['COVID', 'LungOpacity', 'Normal', 'ViralPneumonia'] for i in range(4): precision = results[i][i] / results.sum(axis=0)[i] recall = results[i][i] / results.sum(axis=1)[i] results_table.add_row([class_names[i], np.round(precision, 3), np.round(recall, 3), np.round(precision * recall * 2 / (precision + recall), 3)]) print(results_table)登录后复制In [23]resnet50 = ResNet(50, 4)eval(resnet50, 'resnet50')登录后复制
eval_loss: 0.4542655143670218, eval_acc: 0.9192411234212476+----------------+-----------+--------+----------+| Type | Precision | Recall | F1_Score |+----------------+-----------+--------+----------+| COVID | 0.95 | 0.953 | 0.952 || LungOpacity | 0.907 | 0.846 | 0.875 || Normal | 0.906 | 0.949 | 0.927 || ViralPneumonia | 0.992 | 0.926 | 0.958 |+----------------+-----------+--------+----------+登录后复制In [24]
epsanet50 = EPSANet(50, 4)eval(epsanet50, 'epsanet50')登录后复制
eval_loss: 0.44931766024769043, eval_acc: 0.941101589868235+----------------+-----------+--------+----------+| Type | Precision | Recall | F1_Score |+----------------+-----------+--------+----------+| COVID | 0.962 | 0.975 | 0.968 || LungOpacity | 0.921 | 0.895 | 0.908 || Normal | 0.937 | 0.952 | 0.945 || ViralPneumonia | 1.0 | 0.97 | 0.985 |+----------------+-----------+--------+----------+登录后复制In [25]
# 预测图像def predict(img_path, model, name='model'): # 加载模型参数 model.load_dict(paddle.load('{}.pdparams'.format(name))) model.eval() img = cv2.imread(img_path) plt.imshow(img[:, :, ::-1]) # BGR -> RGB plt.show() img = paddle.reshape(transform(img), [-1, 3, 224, 224]) # 返回每个分类标签的对应概率 results = model(img) # 概率最大的标签作为预测结果 classes = ['COVID', 'LungOpacity', 'Normal', 'ViralPneumonia'] label = paddle.argmax(results).item() predict_result = classes[label] print(predict_result)predict('work/dataset/COVID/COVID-1949.webp', EPSANet(50, 4), 'epsanet50')predict('work/dataset/LungOpacity/LungOpacity-3118.webp', EPSANet(50, 4), 'epsanet50')predict('work/dataset/Normal/Normal-09331.webp', EPSANet(50, 4), 'epsanet50')predict('work/dataset/ViralPneumonia/ViralPneumonia-1195.webp', EPSANet(50, 4), 'epsanet50')登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制
COVID登录后复制
登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制
LungOpacity登录后复制
登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制
Normal登录后复制
登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制登录后复制
ViralPneumonia登录后复制
Grad-CAM
Grad-CAM(Gradient-weighted Class Activation Mapping)梯度加权类激活图,其前身为CAM(Class Activation Mapping)类激活图。CAM可以理解为对预测输出的贡献分布,分数越高的地方表示原始图片对应区域对网络的响应越高、贡献越大,即表示每个位置对该类别的重要程度。Grad-CAM是在CAM基础上的改进与泛化,使其能够用于更广泛的模型结构上,并进一步提升突出重点区域的能力。
CAM
一般DNN的结构如图-14所示:模型前面是堆叠在一起不断降低输出特征图尺寸、增加通道数的卷积层,用于提取图片各个粒度的特征,后面接一个GAP(全局平均池化)层得到各个通道特征图的均值,最后接一个Softmax激活的全连接层输出各个类别的判别概率。最终模型输出的每一个类别的判别概率就是最后全连接层对应此类别的权重乘以前面GAP层输出的特征图均值得到的。这个值越大模型最终输出此类别的概率就越大,是模型判别最终输出类别的关键。
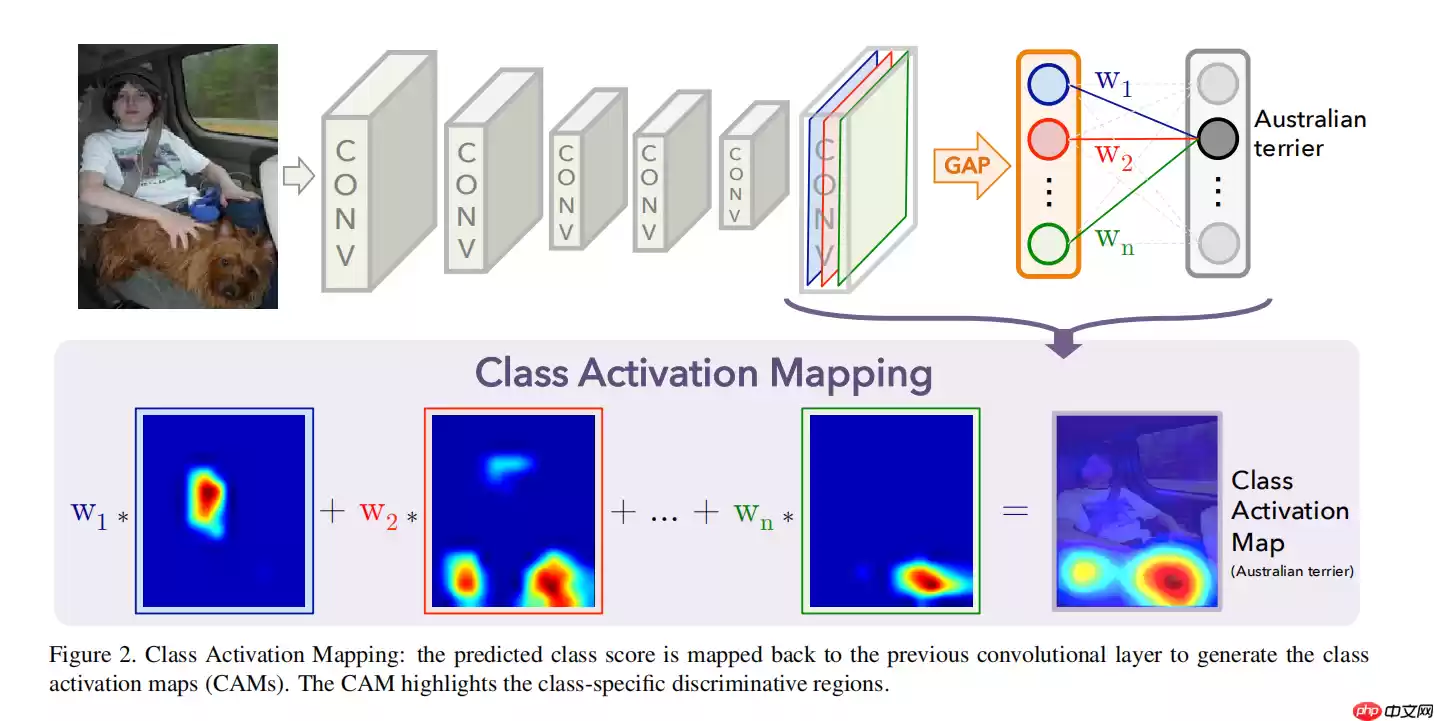
CAM就是从这个值的意义出发来设计的。全连接层权重与GAP层输出的特征图均值的乘积能够决定模型最终输出的类别,但是为了最终输出一个代表概率的值,GAP层将最后一个卷积层提取的特征图从二维降至一维,失去了空间特征信息。如果我们将最后一个卷积层提取的二维特征图不经过GAP层直接与最后的全连接层的权重相乘,不就既能保留二维特征图的二维空间特性,又能反应特征图对当前分类输出的重要性了么?其实,这就是CAM,计算公式如下所示:
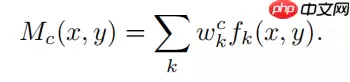
其中Mc(x,y)表示计算得到的针对类别C的类激活图,fk(x,y)表示最后一个卷积层提取的特征图,wkc表示最后一个全连接层计算类别c概率的权重。
CAM论文原文:Learning Deep Features for Discriminative Localization论文原版代码:https://github.com/zhoubolei/CAMGrad-CAM
既然CAM已经能够展现模型的重点关注区域,那为什么还要发展Grad-CAM呢?因为CAM要求模型结构中必须要包含一个GAP层,如果没有就要加入一个GAP层。这对一些已经训练好的模型很不方便,从而限制CAM的适用范围。而Grad-CAM正是为克服这一局限而设计的。
CAM公式如下:
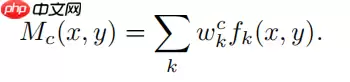
Grad-CAM公式如下:
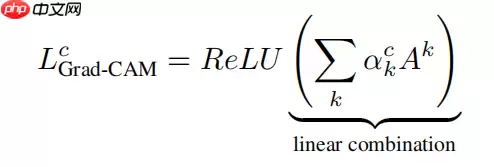
ReLU的目的是在最后加和各个通道的激活图时只加和权重为正值的,以消除激活图上一些与目标类别无关的干扰(仅关注对最终预测分类有正向影响的特征)。
Grad-CAM公式里的Ak和CAM公式里的fk(x,y)均表示最后一个卷积层提取的特征图。两个公式中剩下的唯一不同部分,也是最重要的部分就是特征图的激活加权方式。在CAM公式中是通过乘上wkc给各个通道的特征图进行激活加权的,其表示经过GAP后最后一个全连接层中激活目标类别c的k通道的权重,实现算法时将这部分权重从全连接层中剥离出来即可,在Grad-CAM公式中给特征图进行激活加权是通过αkc这部分实现的。
αkc是通过对最后一个卷积层的梯度进行GAP操作得到的,公式如下:
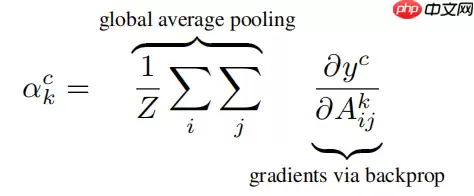
等式右边左半部份表示GAP操作,右半部份的∂Aijk∂yc表示针对目标类别c的loss对最后一个卷积层提取的特征图的梯度,其通过对模型的计算图进行反向梯度传播得到。
Grad-CAM论文原文:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization论文原版代码:https://github.com/ramprs/grad-cam/In [ ]# GradCAMfrom gradcam import GradCAMmodel = EPSANet(50, 4)model.load_dict(paddle.load('epsanet50.pdparams'))# 查看网络层GradCAM.show_network(model)# 指定卷积层layer = 'block.15.conv3.1'gradcam = GradCAM(model, layer)登录后复制In [ ]# 批量生成GradCAMdef grad_cam(img_dir): img_list = os.listdir(img_dir) img_list = filter(lambda x: '.webp' in x, img_list) for img_file in img_list: img_path = os.path.join(img_dir, img_file) img = cv2.imread(img_path) save_dir = os.path.split(img_dir)[-1] save_path = os.path.join('/home/aistudio/work/gradcam', f'{save_dir}') if not os.path.exists(save_path): os.makedirs(save_path) save_path = os.path.join(save_path, f'{img_file}') gradcam.save(img, file=save_path)grad_cam('/home/aistudio/work/dataset/ViralPneumonia')登录后复制In [28]# 批量展示GradCAMdef show_cam(img_dir, cam_dir): img_list = os.listdir(img_dir) img_list = filter(lambda x: '.webp' in x, img_list) img_list = [os.path.join(img_dir, img_file) for img_file in img_list] img_list.sort(key=lambda x : x[-8:]) cam_list = os.listdir(cam_dir) cam_list = filter(lambda x: '.webp' in x, cam_list) cam_list = [os.path.join(cam_dir, cam_file) for cam_file in cam_list] cam_list.sort(key=lambda x : x[-8:]) show_list = img_list[:8] + cam_list[:8] for i, path in enumerate(show_list): img = cv2.imread(path) img = img[:, :, ::-1] # BGR -> RGB plt.subplot(4, 4, i + 1) plt.imshow(img) plt.show()show_cam('/home/aistudio/work/dataset/ViralPneumonia', '/home/aistudio/work/gradcam/ViralPneumonia')登录后复制登录后复制
相关攻略

FDUSD脱锚惊魂夜:币安生态稳定币的信任危机与系统性风险 2025年4月2日夜间,加密货币市场经历了一场突如其来的“压力测试”。由香港First Digital Trust Limited发行的美元稳定币FDUSD,在市场上演了惊心动魄的脱锚跳水,其兑USDT价格一度暴跌至0 8726美元。这场震

最近又折腾了下 Obsidian 的 Git 插件,虽然也有点麻烦,但它是适合我的。下面介绍下怎么配置和使用。 第一次使用 Obsidian 是在 2024 年,这是翻阅之前的文章 《Obsidia

这项由华为技术有限公司、南洋理工大学、香港大学和香港中文大学联合完成的突破性研究发表于2026年1月,论文编号为arXiv:2601 01426v1。研究团队通过一种名为SWE-Lego的创新训练方

12 月 27 日消息,科技媒体 NeoWin 今天(12 月 27 日)发布博文,报道称 AI 代码编辑器 Windsurf 本周发布 Wave 13 版,通过大幅升级多智能体工作流、性能可访问

NEO(小蚁区块链)旨在构建智能经济网络。NEO通过资产数字化和智能合约实现自动化管理,用户需在支持NEO交易的平台注册账户并获取数字货币,选择合适的交易对后,即可下单交易并确认。交易完成后,可在账户中查看NEO资产,或转移至个人数字储存中安全保管NEO。
热门专题







热门推荐

在包子漫画App精准定位心仪漫画:从入门到精通的搜索指南 面对海量的漫画资源,你是否苦恼于如何快速找到自己想看的那一部?包子漫画App内置的智能搜索系统,正是你高效解锁全站精彩内容的利器。掌握以下搜索方法与技巧,你将能轻松驾驭这座漫画宝库,大幅提升找书效率。 第一步:快速找到搜索入口 启动包子漫画A

明日方舟终末地洛茜最强配队攻略:三大体系阵容搭配详解 在《明日方舟:终末地》的策略攻防世界中,角色组合与队伍构建是决定战局胜负的关键。作为当前版本的热门输出手,洛茜的配队方案备受玩家关注。本文将全面解析洛茜的核心配队思路,包括法术爆发、物理攻坚、五色极致及稳定进阶四大流派,帮助您根据自身box与资源

魔兽世界城市大门钥匙:功能详解与核心作用 开启核心区域通道 城市大门钥匙最基础的用途,便是解锁主城的主要入口,让玩家能够深入城市的中央区域。以经典例子铁炉堡大门钥匙来说,缺少这把钥匙,玩家便无法进入这座矮人王城的核心地带,只能在外围区域活动。 成功进入主城后,完整的游戏体验才正式开启。主城是玩家活动

奥兹玛攻坚战小队模式攻略:机制详解与高效通关指南 对于DNF玩家而言,奥兹玛攻坚战无疑是版本实力的重要试炼场。其中,小队模式以其独特的挑战性备受关注——它的难度究竟如何定义?实际上,攻克奥兹玛小队模式虽有章法可循,却也需要系统性的策略与准备,绝非仅凭蛮力就能轻易通关。 职业配置是基石,团队协同定胜负

七大罪起源红色魔神Boss攻略:三阶段机制详解与实战打法 在《七大罪:起源》中,世界等级3的最终守关首领“红色魔神”,以其极具挑战性的多阶段机制与极低的容错率,成为了当前版本团队副本的核心难点。许多队伍在此反复受挫,究其根本,往往是对Boss各阶段的技能逻辑、环境互动与团队配置策略缺乏系统性理解。本