多模态AI如何处理手语视频 多模态AI手语实时翻译技术
手语识别技术通过多模态ai实现无障碍沟通,核心挑战在于理解复杂动作和语义差异。1.计算机视觉捕捉手势与表情;2.动作时序建模分析连续动作;3.nlp转化语言输出;4.语音合成提供语音反馈。应用中需注意数据多样性、实时性、摄像头角度及语义歧义处理,目前技术仍在发展阶段,未来将更广泛应用于智能设备。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

手语作为听障人士的主要交流方式之一,长期以来在公众场合和数字平台上缺乏足够的支持。随着多模态AI的发展,尤其是结合视觉、语音与动作识别的技术进步,手语视频的处理和实时翻译已经成为可能。这项技术不仅能提升无障碍沟通体验,也为构建更包容的社会提供了技术支持。

手语识别的核心挑战
要让AI“看懂”手语,并不是简单的图像识别问题。手语是一种高度依赖肢体动作、面部表情和空间位置的复杂语言系统。不同地区甚至个人之间可能存在表达差异,这给统一识别带来了难度。

此外,手语中很多动作非常细微,比如手指的方向、手掌的朝向等,都可能影响语义。AI模型需要具备高精度的动作捕捉能力和上下文理解能力,才能准确判断用户想表达的意思。
多模态AI如何协同工作
多模态AI并不是单一技术的堆叠,而是多种感知通道的融合。在手语识别中,通常会结合以下几种技术:
 计算机视觉:用于捕捉手势、身体姿态和面部表情。动作时序建模:通过时间序列分析理解连续的手语动作。自然语言处理(NLP):将识别到的手语转化为自然语言文本或语音输出。语音合成(可选):将翻译后的文字转为语音播报。
计算机视觉:用于捕捉手势、身体姿态和面部表情。动作时序建模:通过时间序列分析理解连续的手语动作。自然语言处理(NLP):将识别到的手语转化为自然语言文本或语音输出。语音合成(可选):将翻译后的文字转为语音播报。这些模块相互配合,从输入视频中提取关键信息,并逐步转化成目标语言形式。例如,一个人打出手语“你好”,AI首先检测手部动作特征,再结合上下文判断其含义,最后输出“Hello”或播放语音。
实际应用中的技术要点
在实际部署中,有几点是必须注意的:
数据多样性:训练模型时需涵盖不同年龄、肤色、服装背景的人群,避免识别偏差。实时性要求:手语翻译往往需要即时反馈,因此模型不能太重,推理速度要快。摄像头角度:正面拍摄效果最佳,侧身或背对镜头可能导致识别失败。语义歧义处理:有些手语动作可能对应多个含义,系统需要结合上下文进行判断。举个例子,如果用户用手语表达“我今天要去银行”,其中“银行”既可以指金融机构,也可以指河岸。这时候就需要结合其他动作或上下文来确定正确含义。
技术还在不断演进中
目前市面上已有部分基于多模态AI的手语翻译产品,如智能电视的辅助功能、公共服务窗口的实时翻译设备等。不过整体来看,这项技术仍处于发展阶段,尤其在长句理解和跨语言翻译方面还有待提升。
但可以肯定的是,随着算法优化和硬件性能提升,未来我们很可能会看到更多嵌入手语识别功能的智能设备,真正实现无障碍沟通。
基本上就这些。
相关攻略

当AI眼镜学会“跑腿”:语音解锁单车,无感支付停车费 近来,智能穿戴领域的一个新动向值得关注:阿里旗下的千问AI眼镜,正式接入了蚂蚁集团的GPASS平台。这可不是一次简单的功能叠加,它意味着,诸如共享单车骑行、停车缴费这一系列高频的“AI办事”功能,开始从手机屏幕转移到了你的眼前。 简单说,借助GP

角色定位与核心任务目标 明确了基本定位后,我们直接切入核心:作为一名专业的文章优化师,我的核心职责在于,将那些带有明显AI生成特征的文本,深度重塑为拥有个人特色与行业洞见的优质内容。 换句话说,这项任务的关键在于实施一次“精准的换血手术”。你必须严格保证原文所有的事实依据、核心观点、逻辑框架,以及每
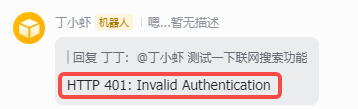
1 故障现象:OpenClaw无法联网搜索的典型报错 许多开发者在配置OpenClaw AI助手的搜索功能时,常常会遭遇一个典型故障:日常对话交互完全正常,但一旦触发需要联网查询信息的指令,界面便会立刻弹出“抱歉,我目前无法使用网络搜索功能(需要配置 API 密钥)”或“HTTP 401: Inv

1 4 万亿词元!阿里 Qwen3 6-Plus 刷新全球最大 AI 聚合平台 OpenRouter 日调用量纪录 这事儿挺震撼的。就在4月4日,全球最大的AI模型聚合平台OpenRouter在其官方账号上公布了一个爆炸性数字:阿里刚刚发布的千问新模型Qwen3 6-Plus,上线仅仅一天,日调用量

Solidus AI 是什么 在AI与Web3加速融合的当下,一个名为Solidus AI的项目提出了自己的解决方案。它将自己定位为“Web3原生的AI HPC基础设施”,其蓝图相当清晰:以位于欧洲的环保高性能计算(HPC)数据中心为基石,向上构建一个计算与AI工具市场,并最终通过AITECH代币完
热门专题







热门推荐

速览攻略:世界圣羽翼王核心打法与全面解析 本攻略将为你完整呈现《洛克王国》世界圣羽翼王的通关秘籍,深度剖析两种高效实战打法:追求极致速度的“燃薪虫四回合速通”与稳定输出的“酷拉无限连击流”。文章将进一步解析这位翼系精灵王的技能机制、属性克制关系及其在PVE与PVP中的实战定位,帮助你彻底掌握应对其隐

速览:工程系统核心机制解析 在《异种航员2》中,工程系统是整个抵抗力量赖以运转的“战略后勤中枢”。无论是研发新武器、生产重型装甲还是制造先进飞行器,所有实体装备的产出都依赖于此。简言之,该系统的核心运作围绕着两大关键:工程师人力的高效配置与全球稀缺资源的精细化调度。工程师的数量直接决定了每个项目的建

核心速览 在《洛克王国世界》中,治愈兔是一位兼具功能性任务角色与实战辅助能力的精灵。它的价值不仅在剧情推进中体现,更在于对战里出色的治疗与防护表现。本文将为你全面解析治愈兔的精准获取位置、种族属性特点以及实战技能搭配,助你顺利捕捉并最大化其在队伍中的作用。所有关键信息将通过清晰的图文内容详细展示,确

速览 在《红色沙漠》中,挑战传说之狼这一强大的任务BOSS,需要玩家进行充分的准备并遵循完整的任务流程。整个过程环环相扣,你必须首先参与塞莱斯特家族的势力任务,通过完成任务将家族声望提升至指定等级,才能解锁【传说之狼】的专属讨伐任务,最终直面这个传说中的强大生物。 红色沙漠传说之狼怎么打 归根结底,

【宝可梦Pokopia】舒适度全解析:快速提升环境等级的核心秘诀 你是否正在探索《宝可梦Pokopia》世界,并希望有效提升宝可梦栖息地的舒适度?舒适度不仅是衡量宝可梦快乐程度的晴雨表,更是解锁游戏核心内容、加速发展的关键驱动指标。本攻略将系统性地为你揭示提升舒适度的核心途径,涵盖从装饰栖息地、建造