基于paddle复现Conv-FFD快速谣言检测模型
本文聚焦社交媒体虚假谣言检测,指出传统方法存在局限,深度学习是主流但实时性待提升。为此提出基于中文文本的Conv-FFD模型,以字为处理单元,通过卷积提取特征,经全连接层获检测结果。实验验证其效率,还复现了该模型及对比模型,给出数据集处理、模型构建、训练评估等过程,复现精度为0.8795,接近目标值。

一、论文简介
1.1 背景
社交媒体的发展在加速信息传播的同时,也带来了虚假谣言信息的泛滥,往往会引发诸多不安定因素,并对经济和社会产生巨大的影响。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
人们常说“流言止于智者”,要想不被网上的流言和谣言盅惑、伤害,首先需要对其进行科学甄别,而时下人工智能正在尝试担任这一角色。那么,在打假一线AI技术如何做到去伪存真?
传统的谣言检测模型一般根据谣言的内容、用户属性、传播方式人工地构造特征,而人工构建特征存在考虑片面、浪费人力等现象。本次实践使用基于循环神经网络(RNN)的谣言检测模型,将文本中的谣言事件向量化,通过循环神经网络的学习训练来挖掘表示文本深层的特征,避免了特征构建的问题,并能发现那些不容易被人发现的特征,从而产生更好的效果。
在现代信息物理空间中,各种社交网络服务已成为日常生活中获取信息不可或缺的一部分 。这使得社会服务用户面临着不断增长的新闻和信息量无处不在。但与此同时,各种真假新闻混杂在一起,总是让社会服务用户难以很好地辨别其本质。目前的情况无疑给网络物理社会服务的运营商带来了很大的挑战。
没有有效的技术监管手段,广大用户可能会受到威胁。一个典型案例是 2020 年早期 COVID-19 相关虚假新闻的广泛传播,带来了严重的经济和社会危害。因此,研究实用的假新闻检测方法,对于网络物理社会服务的运营商具有重要意义 。
现有的网络物理社会服务假新闻检测研究大致可分为两类:统计检索和语义计算。前者主要是对句子或段落进行分词后,搜索与异常特征相关的关键词。然后,建立一个评分模型来评估句子的真实性作为结果。然而,以这种方式拆分句子的想法很难捕捉到句子的语义特征。当没有明确的异常关键字时,很难得到理想的结果。后者更侧重于建立数学模型来以向量化形式表示句子的语义。
然后,利用机器学习中的分类或回归方法输出情感评价结果。然而,从语言学的角度来看,几乎任何一种语言都有大量的词单元,这使得向量模型的构建具有挑战性。
目前,深度学习因其先进的信息处理结构已成为语义建模的主流思想,对算法效率提出了挑战。因为在现实世界的大规模数据流中,算法的实时性对于现实实践至关重要。
1.2 方法
现实世界的大规模数据流中,算法的实时性对于现实世界的影响巨大,为弥补之间的差距,本文以基于中文文本的谣言数据为对象,提出了一种基于深度学习的社交网络假新闻快速检测模型-Conv-FFD。Conv-FFD将中文短文本中的每个字直接作为基本处理单元。使用特征提取滤波器Conv扫描句子中的每个单元字符,通过卷积运算从一个字符和相邻字符中提取联合特征表征。最后,通过全连接层映射最终获得检测结果。
它利用基于卷积的神经计算结构实现了快速假新闻检测(Conv-FFD )。对从移动社交媒体收集的真实数据集进行了一组实验,以验证所提出的 Conv-FFD 的效率。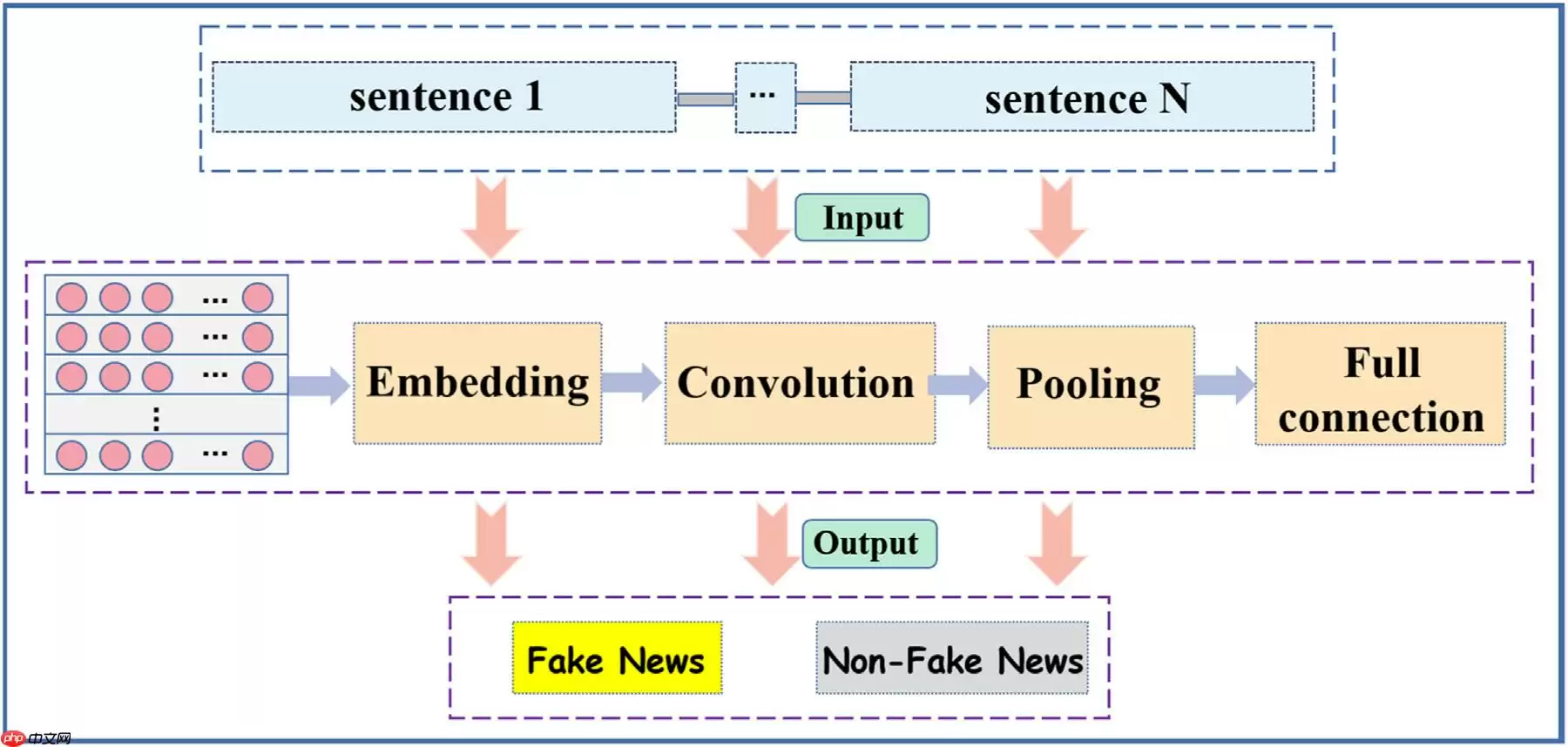
为了快速将字符级特征表示合并为句子级特征表示,选择了CNN。 CNN是一种通过卷积运算自动从目标实体中学习隐藏特征的神经网络模型。卷积算子可以看作是一个过滤器,扫描目标实体的全局特征,从而获得新的抽象特征。 CNN最常见的应用领域是计算机视觉和图像处理。由于像素级特征和词级特征都是向量的形式,因此,CNN也可以用于语义建模。
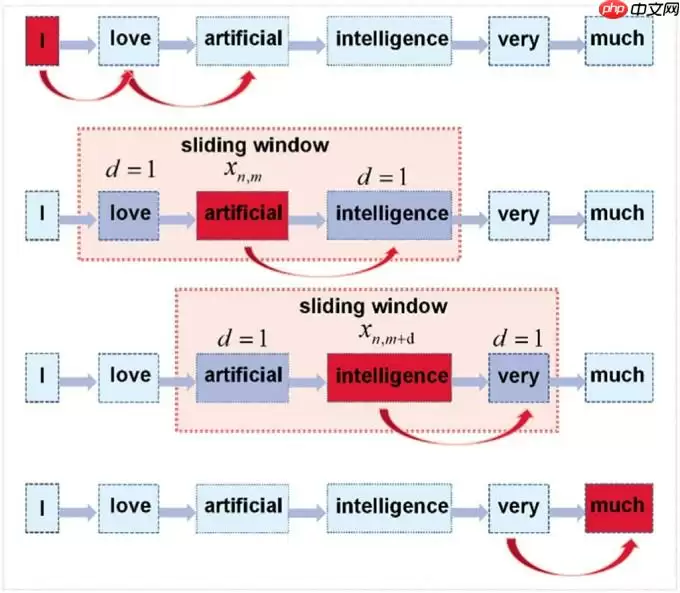
如下图所示,每个字的embedding都可以看作是一个垂直方向的向量。对于每个字符 Xn,m,假设它与其相邻的几个字符相关联。相邻字符的范围在xn,m的前d个字符和后d个字符。也就是说,xn,m−d与其相邻的2d个词组合成了一个滑动窗口。它从xn,m−d开始到字符xn,m+d结束。
1.3 实验
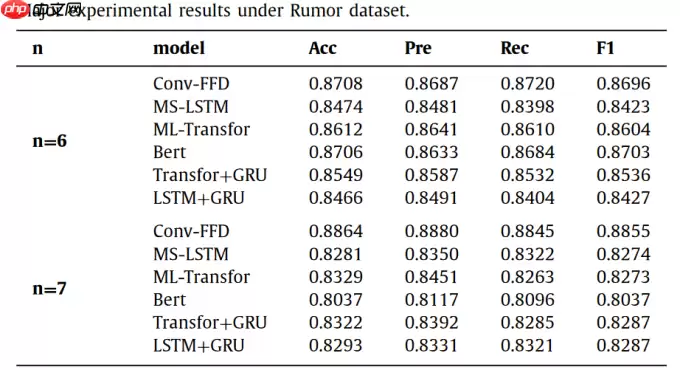
实验中提出一个参数n,将所有样本分为多组,其中1个作为测试样本,剩余n个作为训练集
论文:
[1]https://www.sciencedirect.com/science/article/pii/S0167865523000569参考项目:
https://github.com/Ctbuzhangqin/Fast-Fake-News-Detection-2二、复现精度
复现论文中的Conv-FFD,在Rumordataset数据集上精度为0.8795。 目标精度:0.8864 以及其中的几个对比模型。
三、环境设置
硬件:GPU\CPU 框架: PaddlePaddle >=2.0.0
In [ ]import paddleimport paddle.nn as nnfrom paddle.nn import Conv2D, Linear, Embeddingfrom paddle import to_tensorimport paddle.nn.functional as Fprint(paddle.__version__)import os, zipfileimport io, random, jsonimport numpy as npimport matplotlib.pyplot as plt登录后复制
四、数据集
本次实践所使用的数据是从新浪微博不实信息举报平台抓取的中文谣言数据,数据集中gong包含1538条谣言和1849条非谣言。如下图所示,每条数据均为json格式,其中text字段代表微博原文的文字内容。
更多数据集介绍请参考https://github.com/thunlp/Chinese_Rumor_Dataset。
(1)解压数据,读取并解析数据,生成all_data.txt
(2)生成数据字典,即dict.txt
(3)生成数据列表,并进行训练集与验证集的划分,train_list.txt 、eval_list.txt
(4)定义训练数据集迭代器
(1)解压数据,读取并解析数据,生成all_data.txt
In [ ]import os, zipfilesrc_path="data/data201561/Rumor_Dataset.zip"target_path="/home/aistudio/data/Chinese_Rumor_Dataset-master"if(not os.path.isdir(target_path)): z = zipfile.ZipFile(src_path, 'r') z.extractall(path=target_path) z.close()登录后复制In [ ]
import ioimport randomimport json#谣言数据文件路径rumor_class_dirs = os.listdir(target_path+"/Chinese_Rumor_Dataset-master/CED_Dataset/rumor-repost/")#非谣言数据文件路径non_rumor_class_dirs = os.listdir(target_path+"/Chinese_Rumor_Dataset-master/CED_Dataset/non-rumor-repost/")original_microblog = target_path+"/Chinese_Rumor_Dataset-master/CED_Dataset/original-microblog/"#谣言标签为0,非谣言标签为1rumor_label="0"non_rumor_label="1"#分别统计谣言数据与非谣言数据的总数rumor_num = 0non_rumor_num = 0all_rumor_list = []all_non_rumor_list = []#解析谣言数据for rumor_class_dir in rumor_class_dirs: if(rumor_class_dir != '.DS_Store'): #遍历谣言数据,并解析 with open(original_microblog + rumor_class_dir, 'r') as f: rumor_content = f.read() rumor_dict = json.loads(rumor_content) all_rumor_list.append(rumor_label+"\t"+rumor_dict["text"]+"\n") rumor_num +=1#解析非谣言数据for non_rumor_class_dir in non_rumor_class_dirs: if(non_rumor_class_dir != '.DS_Store'): with open(original_microblog + non_rumor_class_dir, 'r') as f2: non_rumor_content = f2.read() non_rumor_dict = json.loads(non_rumor_content) all_non_rumor_list.append(non_rumor_label+"\t"+non_rumor_dict["text"]+"\n") non_rumor_num +=1 print("谣言数据总量为:"+str(rumor_num))print("非谣言数据总量为:"+str(non_rumor_num))登录后复制In [ ]#全部数据进行乱序后写入all_data.txtdata_list_path="/home/aistudio/data/"all_data_path=data_list_path + "all_data.txt"all_data_list = all_rumor_list + all_non_rumor_listrandom.shuffle(all_data_list)#在生成all_data.txt之前,首先将其清空with open(all_data_path, 'w') as f: f.seek(0) f.truncate() with open(all_data_path, 'a') as f: for data in all_data_list: f.write(data)登录后复制
(2)生成数据字典,即dict.txt
In [ ]# 生成数据字典def create_dict(data_path, dict_path): with open(dict_path, 'w') as f: f.seek(0) f.truncate() dict_set = set() # 读取全部数据 with open(data_path, 'r', encoding='utf-8') as f: lines = f.readlines() # 把数据生成一个元组 for line in lines: content = line.split('\t')[-1].replace('\n', '') for s in content: dict_set.add(s) # 把元组转换成字典,一个字对应一个数字 dict_list = [] i = 0 for s in dict_set: dict_list.append([s, i]) i += 1 # 添加未知字符 dict_txt = dict(dict_list) end_dict = {"": i} dict_txt.update(end_dict) end_dict = {"": i+1} dict_txt.update(end_dict) # 把这些字典保存到本地中 with open(dict_path, 'w', encoding='utf-8') as f: f.write(str(dict_txt)) print("数据字典生成完成!") 登录后复制(3)生成数据列表,并进行训练集与验证集的划分,train_list.txt 、eval_list.txt
In [ ]# 创建序列化表示的数据,并按照一定比例划分训练数据train_list.txt与验证数据eval_list.txtdef create_data_list(data_list_path): #在生成数据之前,首先将eval_list.txt和train_list.txt清空 with open(os.path.join(data_list_path, 'eval_list.txt'), 'w', encoding='utf-8') as f_eval: f_eval.seek(0) f_eval.truncate() with open(os.path.join(data_list_path, 'train_list.txt'), 'w', encoding='utf-8') as f_train: f_train.seek(0) f_train.truncate() with open(os.path.join(data_list_path, 'dict.txt'), 'r', encoding='utf-8') as f_data: dict_txt = eval(f_data.readlines()[0]) with open(os.path.join(data_list_path, 'all_data.txt'), 'r', encoding='utf-8') as f_data: lines = f_data.readlines() i = 0 maxlen = 0 with open(os.path.join(data_list_path, 'eval_list.txt'), 'a', encoding='utf-8') as f_eval,open(os.path.join(data_list_path, 'train_list.txt'), 'a', encoding='utf-8') as f_train: for line in lines: words = line.split('\t')[-1].replace('\n', '') maxlen = max(maxlen, len(words)) label = line.split('\t')[0] labs = "" # 每8个 抽取一个数据用于验证 if i % 5 == 0: for s in words: lab = str(dict_txt[s]) labs = labs + lab + ',' labs = labs[:-1] labs = labs + '\t' + label + '\n' f_eval.write(labs) else: for s in words: lab = str(dict_txt[s]) labs = labs + lab + ',' labs = labs[:-1] labs = labs + '\t' + label + '\n' f_train.write(labs) i += 1 print("数据列表生成完成!") print(maxlen)登录后复制In [ ]# 把生成的数据列表都放在自己的总类别文件夹中data_root_path = "/home/aistudio/data/" data_path = os.path.join(data_root_path, 'all_data.txt')dict_path = os.path.join(data_root_path, "dict.txt")# 创建数据字典create_dict(data_path, dict_path)# 创建数据列表create_data_list(data_root_path)登录后复制In [ ]
def load_vocab(file_path): fr = open(file_path, 'r', encoding='utf8') vocab = eval(fr.read()) #读取的str转换为字典 fr.close() return vocab登录后复制In [ ]
# 打印前2条训练数据vocab = load_vocab(os.path.join(data_root_path, 'dict.txt'))def ids_to_str(ids): words = [] for k in ids: w = list(vocab.keys())[list(vocab.values()).index(int(k))] words.append(w if isinstance(w, str) else w.decode('ASCII')) return " ".join(words)file_path = os.path.join(data_root_path, 'train_list.txt')with io.open(file_path, "r", encoding='utf8') as fin: i = 0 for line in fin: i += 1 cols = line.strip().split("\t") if len(cols) != 2: sys.stderr.write("[NOTICE] Error Format Line!") continue label = int(cols[1]) wids = cols[0].split(",") print(str(i)+":") print('sentence list id is:', wids) print('sentence list is: ', ids_to_str(wids)) print('sentence label id is:', label) print('---------------------------------') if i == 2: break登录后复制(4)定义训练Dataset和Dataloader
In [ ]vocab = load_vocab(os.path.join(data_root_path, 'dict.txt'))class RumorDataset(paddle.io.Dataset): def __init__(self, data_dir): self.data_dir = data_dir self.all_data = [] with io.open(self.data_dir, "r", encoding='utf8') as fin: for line in fin: cols = line.strip().split("\t") if len(cols) != 2: sys.stderr.write("[NOTICE] Error Format Line!") continue label = [] label.append(int(cols[1])) wids = cols[0].split(",") if len(wids)>=150: wids = np.array(wids[:150]).astype('int64') else: wids = np.concatenate([wids, [vocab[""]]*(150-len(wids))]).astype('int64') label = np.array(label).astype('int64') self.all_data.append((wids, label)) def __getitem__(self, index): data, label = self.all_data[index] return data, label def __len__(self): return len(self.all_data)batch_size = 32train_dataset = RumorDataset(os.path.join(data_root_path, 'train_list.txt'))test_dataset = RumorDataset(os.path.join(data_root_path, 'eval_list.txt'))train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), return_list=True, shuffle=True, batch_size=batch_size, drop_last=True)test_loader = paddle.io.DataLoader(test_dataset, places=paddle.CPUPlace(), return_list=True, shuffle=True, batch_size=batch_size, drop_last=True)#checkprint('=============train_dataset =============') for data, label in train_dataset: print(data) print(np.array(data).shape) print(label) breakprint('=============test_dataset =============') for data, label in test_dataset: print(data) print(np.array(data).shape) print(label) break 登录后复制五、项目运行
本项目提供了论文所提出的Conv_FFD模型,其余的对比模型放在model_utils.py文件中
首先需要加载模型 运行哪个模型就加载哪个即可In [ ]## 导入模型from model_utils import Transformer,LSTM,GRU,CNN登录后复制
1. Conv_FFD
In [ ]#定义卷积网络class Conv_FFD(nn.Layer): def __init__(self,dict_dim): super(Conv_FFD,self).__init__() self.dict_dim = dict_dim self.emb_dim = 128 self.hid_dim = 128 self.fc_hid_dim = 96 self.class_dim = 2 self.channels = 1 self.win_size = [3, self.hid_dim] self.batch_size = 32 self.seq_len = 150 self.embedding = Embedding(self.dict_dim + 1, self.emb_dim, sparse=False) self.hidden1 = paddle.nn.Conv2D(in_channels=1, #通道数 out_channels=self.hid_dim, #卷积核个数 kernel_size=self.win_size, #卷积核大小 padding=[1, 1] ) self.relu1 = paddle.nn.ReLU() self.hidden3 = paddle.nn.MaxPool2D(kernel_size=2, #池化核大小 stride=2) #池化步长2 self.hidden4 = paddle.nn.Linear(128*75, 2) #网络的前向计算过程 def forward(self,input): #print('输入维度:', input.shape) x = self.embedding(input) x = paddle.reshape(x, [32, 1, 150, 128]) x = self.hidden1(x) x = self.relu1(x) #print('第一层卷积输出维度:', x.shape) x = self.hidden3(x) #print('池化后输出维度:', x.shape) #在输入全连接层时,需将特征图拉平会自动将数据拉平. x = paddle.reshape(x, shape=[self.batch_size, -1]) out = self.hidden4(x) return out登录后复制In [ ]model = Conv_FFD(dict_dim=vocab["登录后复制"])
2. transformer
In [ ]vocab_size = len(vocab) maxlen = 200 seq_len = 200batch_size = 32epochs = 3pad_id = vocab['登录后复制']embed_dim = 128 # Embedding size for each tokennum_heads = 2 # Number of attention headsfeed_dim = 128 # Hidden layer size in feed forward network inside transformerclasses = ['0', '1']model = Transformer(maxlen,vocab_size,embed_dim,num_heads,feed_dim)paddle.summary(model,(200,128),"int64")
3. LSTM
In [ ]model = LSTM(dict_dim=vocab["登录后复制"])
4. BiGRU
In [ ]batch_size = 32epochs = 3#词汇表总数vocab_size = len(vocab) + 1print(vocab_size)emb_size = 256#句子固定长度seq_len = 150#补齐词的id编号pad_id = vocab["登录后复制"]#类别classes = ['negative', 'positive']model = GRU(vocab_size=vocab_size,emb_size=emb_size)
模型训练
In [ ]def draw_process(title,color,iters,data,label): plt.title(title, fontsize=24) plt.xlabel("iter", fontsize=20) plt.ylabel(label, fontsize=20) plt.plot(iters, data,color=color,label=label) plt.legend() plt.grid() plt.show()登录后复制In [ ]def train(model): model.train() opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()) steps = 0 Iters, total_loss, total_acc = [], [], [] for epoch in range(3): for batch_id, data in enumerate(train_loader): steps += 1 sent = data[0] label = data[1] logits = model(sent) loss = paddle.nn.functional.cross_entropy(logits, label) acc = paddle.metric.accuracy(logits, label) if batch_id % 50 == 0: Iters.append(steps) total_loss.append(loss.numpy()[0]) total_acc.append(acc.numpy()[0]) print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy())) loss.backward() opt.step() opt.clear_grad() # evaluate model after one epoch model.eval() accuracies = [] losses = [] for batch_id, data in enumerate(test_loader): sent = data[0] label = data[1] logits = model(sent) loss = paddle.nn.functional.cross_entropy(logits, label) acc = paddle.metric.accuracy(logits, label) accuracies.append(acc.numpy()) losses.append(loss.numpy()) avg_acc, avg_loss = np.mean(accuracies), np.mean(losses) print("[validation] accuracy: {}, loss: {}".format(avg_acc, avg_loss)) model.train() paddle.save(model.state_dict(),"model_final.pdparams") draw_process("trainning loss","red",Iters,total_loss,"trainning loss") draw_process("trainning acc","green",Iters,total_acc,"trainning acc")登录后复制In [ ]import timestart_time=time.time()train(model)end_time=time.time()running_time=end_time-start_timeprint("running_time is {}".format(running_time))登录后复制六、模型评估
In [ ]model_state_dict = paddle.load('model_final.pdparams')model.set_state_dict(model_state_dict) model.eval()accuracies = []losses = []for batch_id, data in enumerate(test_loader): sent = data[0] label = data[1] logits = model(sent) loss = paddle.nn.functional.cross_entropy(logits, label) acc = paddle.metric.accuracy(logits, label) accuracies.append(acc.numpy()) losses.append(loss.numpy())avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)print("[validation] accuracy: {}, loss: {}".format(avg_acc, avg_loss))登录后复制In [ ]import numpy as npfrom sklearn.metrics import roc_curve, auc, accuracy_score, precision_score, recall_score, f1_score,confusion_matrixmodel_state_dict = paddle.load('model_final.pdparams')model.set_state_dict(model_state_dict) model.eval()predictions = []r = []for batch_id, data in enumerate(test_loader): sent = data[0] gt_labels = data[1].numpy() for i in gt_labels: r.append(i) results = model(sent) for probs in results: # 映射分类label idx = np.argmax(probs) predictions.append(idx) confusion_matrix(r, predictions)from sklearn.metrics import classification_reporttarget_names = ["0","1"]acc = accuracy_score(r, predictions).round(4)pre = precision_score(r, predictions).round(4)rec = recall_score(r, predictions).round(4)F1 = f1_score(r, predictions).round(4)print('acc:{},pre:{},rec:{},f1:{}'.format(acc,pre,rec,F1))CR=classification_report(r, predictions, target_names=target_names,digits=4)print(CR)登录后复制七、模型预测
In [ ]label_map = {0:"谣言", 1:"不是谣言"}model_state_dict = paddle.load('model_final.pdparams')model.set_state_dict(model_state_dict) model.eval()for batch_id, data in enumerate(test_loader): sent = data[0] gt_labels = data[1].numpy() results = model(sent) predictions = [] for probs in results: # 映射分类label idx = np.argmax(probs) labels = label_map[idx] predictions.append(labels) for i,pre in enumerate(predictions): print('数据: {} \n\n预测: {} \n原始标签:{}'.format(ids_to_str(sent[0]).replace(" ", "").replace("",""), pre, label_map[gt_labels[0][0]])) break break 登录后复制八:复现过程
步骤一:创建字典,由于中文文本中有超过 4000 个字符,使用如此高维的向量直接对每个字符进行编码仍然很困难。或者,将每个字符转换为具有固定维度的向量是一种理想的编码方案,称为词嵌入。但词嵌入实际上是一种并行矩阵变换,将初始汉字映射为特定的代表向量。这个过程实际上是一个特征学习过程,因为在训练过程中需要学习一些用于映射的参数。所以复现的时候是将中文文本直接以字为单位进行分割,不进行分词。对于每个词Xn,m,可以表示为一个onehot向量vn,m,其维数等于所有潜在汉字B的个数。对于vn,m,其对应字的元素设置为1等元素全部为0。公式如下$$v_{n,m}=\left[\underbrace{1,0,0,\cdots0}_{B-1}\right]$$ 接着,通过一下计算,将vn,m抽象为另一个向量表示Vn,m:
Vn,m=σ(WV⋅vn,m+bV)
其中Wv和bv是要学习的参数,(⋅)是激活函数。
σ(ζ)={ζ,ζ≥00,ζ
这样做的好处是,可以将不同向量都转换成相同维度的向量。
步骤二:用paddle编写训练代码 参数设置全部参照作者论文代码中的设置。
步骤三:模型训练
模型代码比较基础,cpu/gpu抖能跑,速度确实比大模型快很多。
遇到的问题 原代码使用的paddle的接口已经失效,目前最新的已经没有,因此执行的时候报错,将代码改为
self.relu = paddle.fluid.dygraph.Linear(feed_dim, 20, act='relu')登录后复制
改后
self.linear1 = nn.Linear(feed_dim, 20)self.relu = nn.ReLU()登录后复制
相关攻略

最近又折腾了下 Obsidian 的 Git 插件,虽然也有点麻烦,但它是适合我的。下面介绍下怎么配置和使用。 第一次使用 Obsidian 是在 2024 年,这是翻阅之前的文章 《Obsidia

这项由华为技术有限公司、南洋理工大学、香港大学和香港中文大学联合完成的突破性研究发表于2026年1月,论文编号为arXiv:2601 01426v1。研究团队通过一种名为SWE-Lego的创新训练方

12 月 27 日消息,科技媒体 NeoWin 今天(12 月 27 日)发布博文,报道称 AI 代码编辑器 Windsurf 本周发布 Wave 13 版,通过大幅升级多智能体工作流、性能可访问

NEO(小蚁区块链)旨在构建智能经济网络。NEO通过资产数字化和智能合约实现自动化管理,用户需在支持NEO交易的平台注册账户并获取数字货币,选择合适的交易对后,即可下单交易并确认。交易完成后,可在账户中查看NEO资产,或转移至个人数字储存中安全保管NEO。

五月加密市场整体数据下滑,但以太坊逆势高光。五月加密市场链上交易额、稳定币交易额、比特币矿工收入等数据均下滑,NFT和CEX现货交易额也下跌,币安市场份额上升。然而,以太坊质押收入上涨,期货未平仓量和期权交易额创新高,现货ETF获批是关键因素,政策和创新驱动以太坊发展,值得关注。
热门专题







热门推荐

可通过电子税务局 、随申办App 小程序、个税APP三种方式查询下载个税纳税记录:电子税务局需登录后搜索或按路径进入,下载PDF用身份证后6位解密;随申办依托统一认证,支持直接保存

3月26日,在SEMICON China 2026“半导体智能制造-未来工厂”论坛上,一场关于半导体制造AI未来形态的思想碰撞引发行业瞩目。智现未来董事长兼CEO管健博士受邀登台,发表题为《从“+A

南都讯 记者李洁琼 3月28日,珠海天际航空科技有限公司在金湾区天章产业园开业。作为珠海低空经济产业的新锐力量,天际航空智能制造基地的投运,标志着金湾区在载人级飞行器制造领域迈出关键一步,为珠海“天

来源:中国新闻网中新社杭州3月27日电 (鲍梦妮)随着机器人产业发展以及春晚机器人表演等热点带动,今年以来,中国多地机器人租赁业务持续升温。在上海上线的全球首个开放式机器人租赁平台“擎天租”,自去年

大象新闻·大象财富记者 李莉 张迪驰315消费者权益日刚过,广东李女士在某平台购买的“全新”打印机频繁报错,维修无果。她查询最新质保发现,整机标注保修三年,系统却显示剩余保修期不足两年,经售后核实确