大家好~,这里是ai粉嫩特攻队!今天我们来探讨一个引人入胜的话题——deepseek-r1究竟是何时“动脑”,又在何时选择“省力”?
最近有小伙伴提问:“听说现在的AI已经能‘推理’了,那它们每次回答问题都要经历一整套复杂的思维链(CoT)吗?”嗯……这个问题看似简单,其实背后隐藏着R1设计中的精妙逻辑。
举个例子,当你向R1打个招呼“你好”时,它肯定不会甩出一堆哲学推演吧?但如果问题是“如何用量子力学解释薛定谔的猫”,那它可能就得认真梳理一下思路了。
那么,这种智能行为背后的机制是什么?为什么有时候它像个严谨的学者,而有时又像个随意的聊天伙伴?
实际上,R1的训练数据分为两类:一类是推理类数据(包含问题、思考过程和答案),另一类则是非推理类数据(只有问题和答案)。来看看R1论文中相关的节选内容:
 图片红线标记的内容对应以下三点:
图片红线标记的内容对应以下三点:
在这个阶段(与初期冷启动时专注于推理不同),引入了其他领域的内容,从而提升模型在写作、角色扮演等通用任务上的表现。 对于非推理任务,如写作、事实问答、自我认知和翻译等,采用了DeepSeek-V3的流程,并部分使用了V3的监督微调(SFT)数据集。 不过像“你好”这类简单的对话,就不会触发思维链输出啦。 亲自动手试试
先问问它是谁,果然这个问题不需要深度思考!再问一个数学题,emmm,开始看到推理过程了~
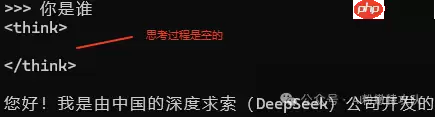 图片
图片 图片总结来说,像R1这样的模型并不会机械地每次都生成推理步骤,而是根据任务复杂度灵活调整输出方式——该深入时深入,该简洁时简洁。
图片总结来说,像R1这样的模型并不会机械地每次都生成推理步骤,而是根据任务复杂度灵活调整输出方式——该深入时深入,该简洁时简洁。
关于DeepSeek-R1“思考”机制的探索就到这里。AI的发展就像一座不断挖掘的知识宝库,我们的学习也永不止步。感谢大家一路同行,共同揭开这个有趣AI世界的面纱。




