2025年4月23日,《nature medicine》国际医学期刊一天内连续发表两篇关于deepseek大模型的研究论文。这两篇文章重点探讨了deepseek在医学临床场景中的应用潜力,并与其他主流ai模型进行了系统性对比。
 图片
图片 图片评估Deepseek在医疗诊断与治疗建议方面的表现近年来,LLM大模型逐步渗透到医学领域,但由于隐私和数据安全等问题,像GPT-4o这类闭源模型难以广泛应用于实际临床场景。而开源大模型DeepSeek的推出为AI辅助医疗提供了一个新思路。
图片评估Deepseek在医疗诊断与治疗建议方面的表现近年来,LLM大模型逐步渗透到医学领域,但由于隐私和数据安全等问题,像GPT-4o这类闭源模型难以广泛应用于实际临床场景。而开源大模型DeepSeek的推出为AI辅助医疗提供了一个新思路。
图片研究团队选取了DeepSeek-V3和DeepSeek-R1两个版本,并将其与GPT-4o及Gemini 2.0 Flash Thinking Experimental进行比较,以测试其在真实医疗任务中的实用性。
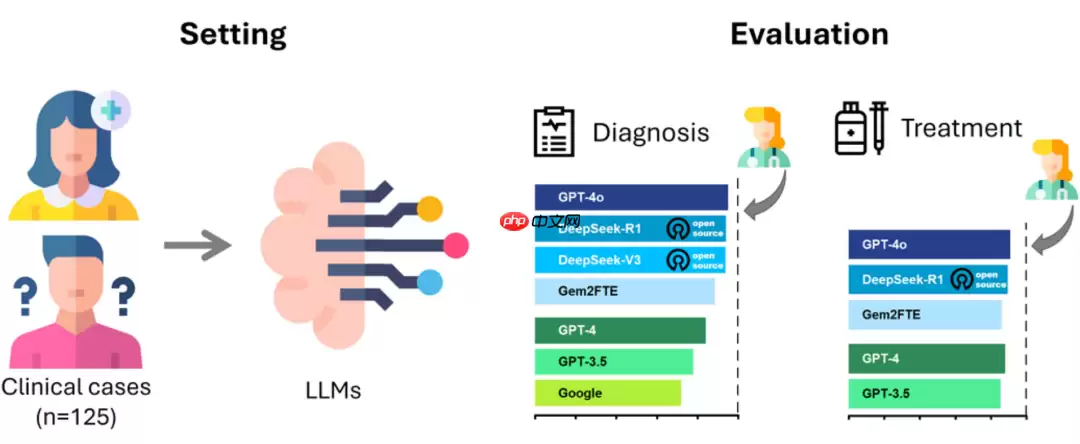 图片通过分析涵盖125个常见病与罕见病的真实病例数据,研究人员发现DeepSeek的表现可媲美甚至超越部分专有模型。
图片通过分析涵盖125个常见病与罕见病的真实病例数据,研究人员发现DeepSeek的表现可媲美甚至超越部分专有模型。
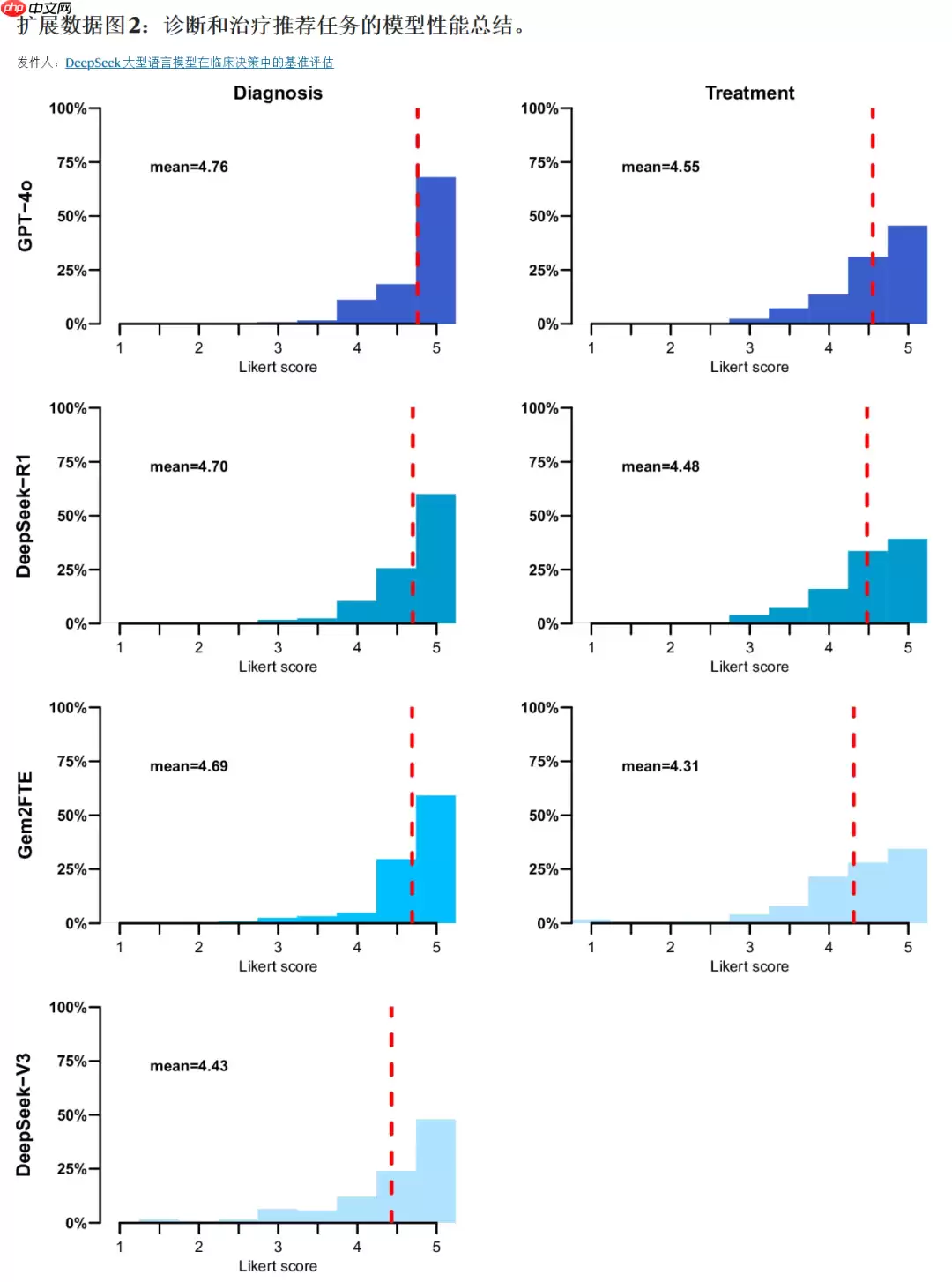
在疾病诊断任务中,DeepSeek-R1与GPT-4o展现出领先优势,两者之间无明显性能差距。
在制定治疗方案方面,DeepSeek-R1与GPT-4o同样保持一致水平,均优于其他参与测试的模型。
 图片验证DeepSeek在医学推理能力上的表现LLM凭借其强大的语言理解和生成能力,在医学教育、临床决策支持等方面显示出巨大前景。
图片验证DeepSeek在医学推理能力上的表现LLM凭借其强大的语言理解和生成能力,在医学教育、临床决策支持等方面显示出巨大前景。
作为新兴的开源LLM,DeepSeek在医疗领域的具体表现仍有待验证。
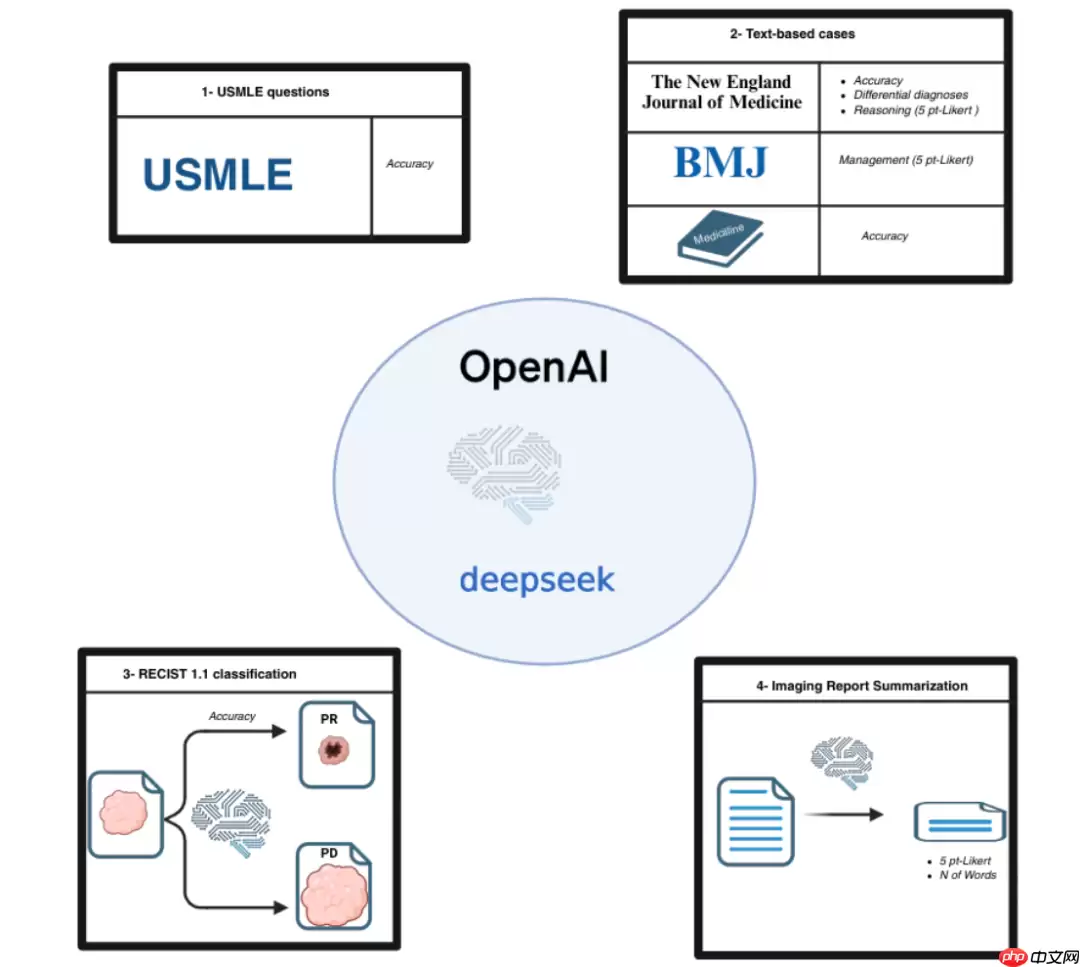
图片此次研究对DeepSeek-R1、ChatGPT-o1以及Llama 3.1-405B三种模型在四项不同医疗任务中的表现进行了全面评估。
这些任务包括:解答美国医师执照考试(USMLE)题目、根据文本信息判断病情并提出治疗建议、识别肿瘤患者对治疗的反应类型,以及撰写诊断报告摘要。
 图片在应对美国医师执照考试时,DeepSeek-R1的成绩高于Llama 3.1-405B,但略逊于ChatGPT-o1,总体来看三者之间的差异并不显著。
图片在应对美国医师执照考试时,DeepSeek-R1的成绩高于Llama 3.1-405B,但略逊于ChatGPT-o1,总体来看三者之间的差异并不显著。
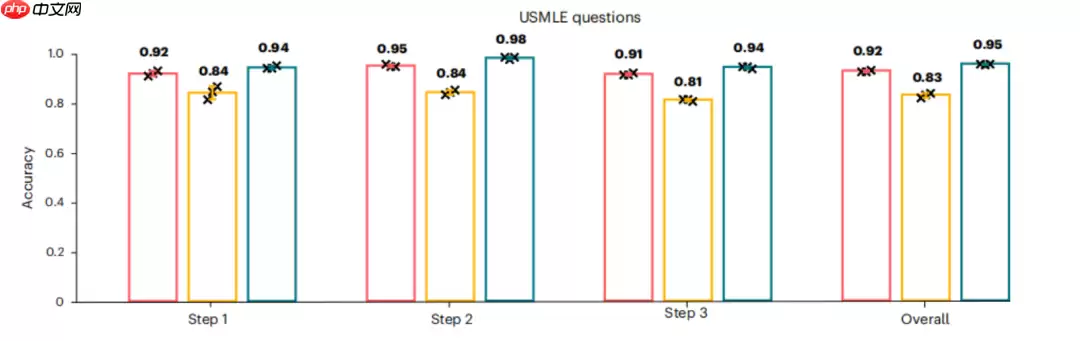 粉色为Deepseek;黄色为Llama;绿色为ChatGPT粉色为Deepseek;黄色为Llama;绿色为ChatGPT
粉色为Deepseek;黄色为Llama;绿色为ChatGPT粉色为Deepseek;黄色为Llama;绿色为ChatGPT
在基于文本信息做出诊断与治疗决策的任务中,研究人员使用NEJM和Medicilline数据库作为测试依据,结果显示DeepSeek-R1与ChatGPT-o1表现相当。
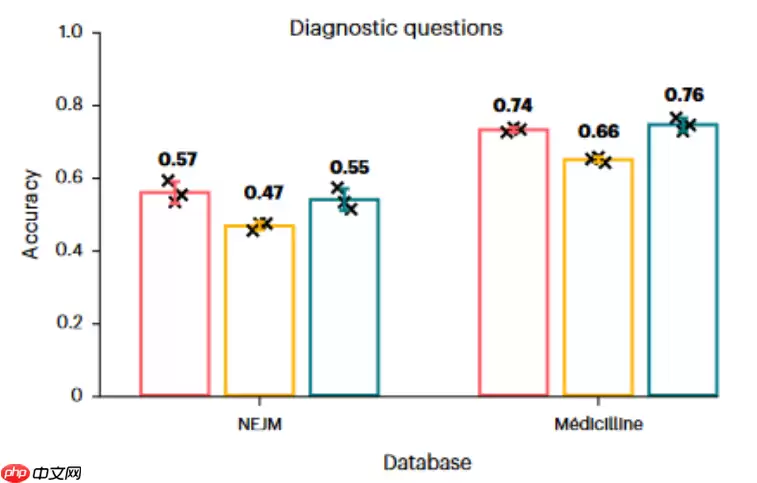 粉色为Deepseek;黄色为Llama;绿色为ChatGPT粉色为Deepseek;黄色为Llama;绿色为ChatGPT
粉色为Deepseek;黄色为Llama;绿色为ChatGPT粉色为Deepseek;黄色为Llama;绿色为ChatGPT
对于肿瘤患者治疗效果分类任务,DeepSeek-R1的整体准确率与ChatGPT-o1接近。
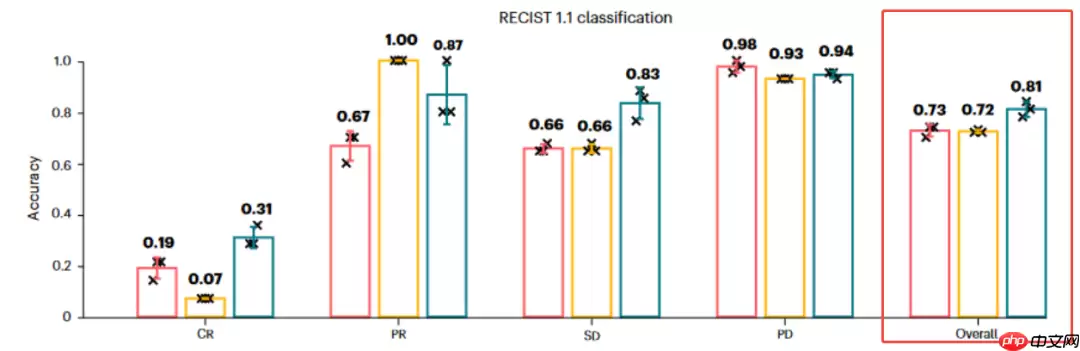 粉色为Deepseek;黄色为Llama;绿色为ChatGPT粉色为Deepseek;黄色为Llama;绿色为ChatGPT
粉色为Deepseek;黄色为Llama;绿色为ChatGPT粉色为Deepseek;黄色为Llama;绿色为ChatGPT
从最终的推理准确性评分来看,DeepSeek-R1得分更高,表明其推理结果相较其他两款模型更加精准。
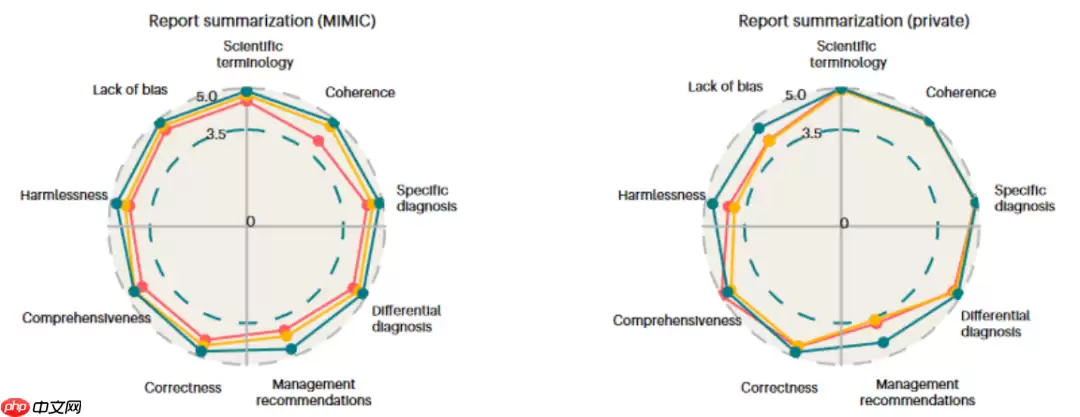
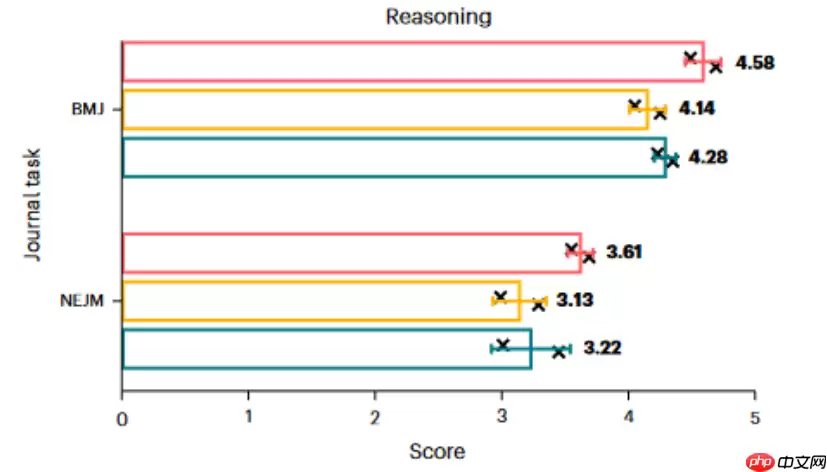 图片在最后一项任务——生成诊断报告摘要方面,研究人员从九个维度对三个模型输出的内容质量进行了打分。数据显示,DeepSeek-R1在此项任务上稍逊于ChatGPT-o1。
图片在最后一项任务——生成诊断报告摘要方面,研究人员从九个维度对三个模型输出的内容质量进行了打分。数据显示,DeepSeek-R1在此项任务上稍逊于ChatGPT-o1。
 图片综合两项研究结果可以得出,国产开源大模型DeepSeek已经具备进入临床实践的能力,标志着我国在人工智能与医疗融合方向取得了重要进展。DeepSeek不仅能够为医生提供科学的诊疗支持,也有助于提升整体医疗服务效率,加速推动AI技术在医学领域的落地应用。
图片综合两项研究结果可以得出,国产开源大模型DeepSeek已经具备进入临床实践的能力,标志着我国在人工智能与医疗融合方向取得了重要进展。DeepSeek不仅能够为医生提供科学的诊疗支持,也有助于提升整体医疗服务效率,加速推动AI技术在医学领域的落地应用。




