刚刚,DeepSeek公布推理时Scaling新论文,R2要来了?
机器之心报道
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
机器之心编辑部
这会是 DeepSeek R2 的雏形吗?本周五,DeepSeek 提交到 arXiv 上的最新论文正在 AI 社区逐渐升温。
当前,强化学习(RL)已广泛应用于大语言模型(LLM)的后期训练。最近 RL 对 LLM 推理能力的激励表明,适当的学习方法可以实现有效的推理时间可扩展性。RL 的一个关键挑战是在可验证问题或人工规则之外的各个领域获得 LLM 的准确奖励信号。
本周五提交的一项工作中,来自 DeepSeek、清华大学的研究人员探索了奖励模型(RM)的不同方法,发现逐点生成奖励模型(GRM)可以统一纯语言表示中单个、成对和多个响应的评分,从而克服了挑战。研究者探索了某些原则可以指导 GRM 在适当标准内生成奖励,从而提高奖励的质量,这启发我们,RM 的推理时间可扩展性可以通过扩展高质量原则和准确批评的生成来实现。
 论文标题:Inference-Time Scaling for Generalist Reward Modeling 论文链接:https://www.php.cn/link/0723c0809ca062085a93e8970e58804d GRM 中有效的推理时间可扩展行为。通过利用基于规则的在线 RL,SPCT 使 GRM 能够学习根据输入查询和响应自适应地提出原则和批评,从而在一般领域获得更好的结果奖励。
论文标题:Inference-Time Scaling for Generalist Reward Modeling 论文链接:https://www.php.cn/link/0723c0809ca062085a93e8970e58804d GRM 中有效的推理时间可扩展行为。通过利用基于规则的在线 RL,SPCT 使 GRM 能够学习根据输入查询和响应自适应地提出原则和批评,从而在一般领域获得更好的结果奖励。
基于此技术,DeepSeek 提出了 DeepSeek-GRM-27B,它基于 Gemma-2-27B 用 SPCT 进行后训练。对于推理时间扩展,它通过多次采样来扩展计算使用量。通过并行采样,DeepSeek-GRM 可以生成不同的原则集和相应的批评,然后投票选出最终的奖励。通过更大规模的采样,DeepSeek-GRM 可以更准确地判断具有更高多样性的原则,并以更细的粒度输出奖励,从而解决挑战。
除了投票以获得更好的扩展性能外,DeepSeek 还训练了一个元 RM。从实验结果上看,SPCT 显著提高了 GRM 的质量和可扩展性,在多个综合 RM 基准测试中优于现有方法和模型,且没有严重的领域偏差。作者还将 DeepSeek-GRM-27B 的推理时间扩展性能与多达 671B 个参数的较大模型进行了比较,发现它在模型大小上可以获得比训练时间扩展更好的性能。虽然当前方法在效率和特定任务方面面临挑战,但凭借 SPCT 之外的努力,DeepSeek 相信,具有增强可扩展性和效率的 GRM 可以作为通用奖励系统的多功能接口,推动 LLM 后训练和推理的前沿发展。
这项研究的主要贡献有以下三点:
研究者们提出了一种新方法:Self-Principled Critique Tuning(SPCT),用于提升通用奖励模型在推理阶段的可扩展性,并由此训练出 DeepSeek-GRM 系列模型。同时,他们进一步引入了一种元奖励模型(meta RM),使 DeepSeek-GRM 的推理效果在超越传统投票机制的基础上得到进一步提升。实验证明,SPCT 在生成质量和推理阶段的可扩展性方面,明显优于现有方法,并超过了多个强大的开源模型。SPCT 的训练方案还被应用到更大规模的语言模型上。研究者们发现推理阶段的扩展性收益甚至超过了通过增加模型规模所带来的训练效果提升。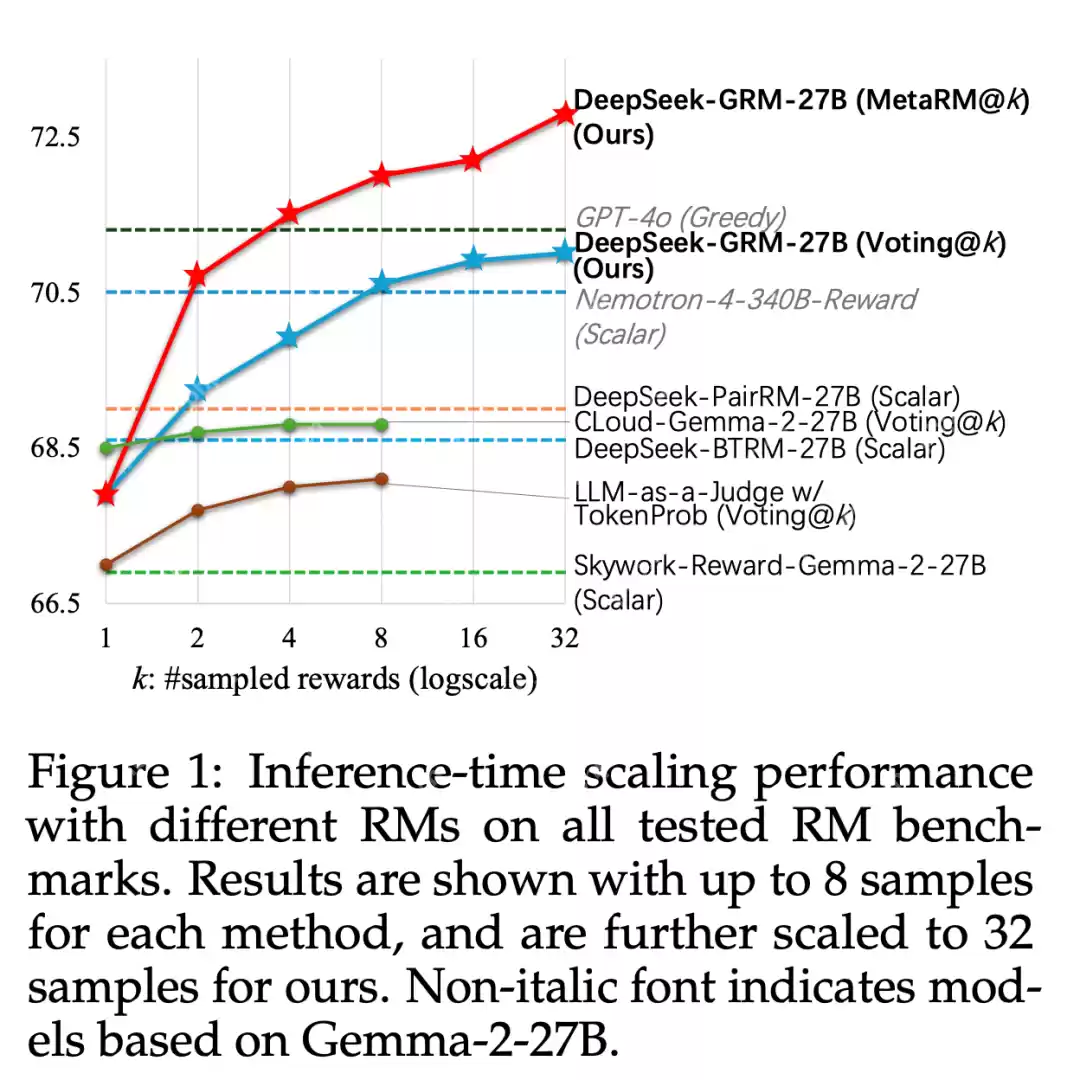 技术细节
技术细节
我们一起来看看这篇论文所讨论的技术细节。
Self-Principled Critique Tuning (SPCT)
受到初步实验结果的启发,研究者提出了一种用于逐点通用奖励模型的新方法,能够学习生成具有适应性和高质量的原则,以有效引导批评内容的生成,该方法被称为自我原则批评调整(SPCT)。
如图 3 所示,SPCT 包含两个阶段:
1. 拒绝式微调(rejective fine-tuning),作为冷启动阶段;
2. 基于规则的在线强化学习(rule-based online RL),通过不断优化生成的准则和评论,进一步增强泛化型奖励生成能力。
此外,SPCT 还能促使奖励模型在推理阶段展现出良好的扩展能力。
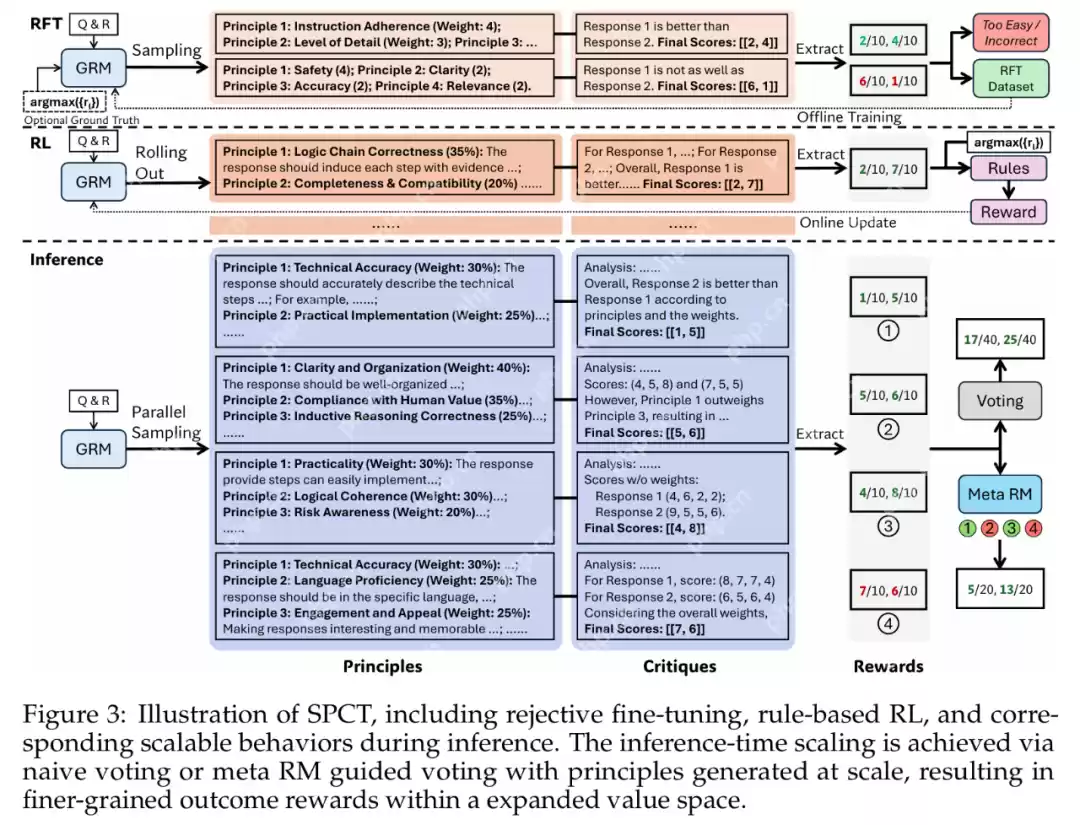 研究者们观察到,高质量的准则能够在特定评判标准下有效引导奖励的生成,是提升奖励模型表现的关键因素。然而,对于通用型奖励模型而言,如何自动生成适应性强、指导性强的准则仍是一个核心难题。
研究者们观察到,高质量的准则能够在特定评判标准下有效引导奖励的生成,是提升奖励模型表现的关键因素。然而,对于通用型奖励模型而言,如何自动生成适应性强、指导性强的准则仍是一个核心难题。
为此,他们提出将准则的作用由传统的理解阶段的辅助性输入,转变为奖励生成过程中的核心组成部分。具体而言,这项研究不再将准则仅作为模型生成前的提示信息,而是使模型能够在生成过程中主动生成并运用准则,从而实现更强的奖励泛化能力与推理阶段的可扩展性。
在该研究的设定中,GRM 可以自主生成准则,并在此基础上生成对应的批评内容,其过程可形式化表示为:
 其中,p_θ 表示由参数 θ 所定义的准则生成函数,该函数与奖励生成函数 r_θ 共享同一模型架构。这样的设计使得准则可以根据输入的 query 和响应自适应生成,从而动态引导奖励的生成过程。此外,准则及其对应批评的质量与细粒度可以通过对 GRM 进行后训练进一步提升。
其中,p_θ 表示由参数 θ 所定义的准则生成函数,该函数与奖励生成函数 r_θ 共享同一模型架构。这样的设计使得准则可以根据输入的 query 和响应自适应生成,从而动态引导奖励的生成过程。此外,准则及其对应批评的质量与细粒度可以通过对 GRM 进行后训练进一步提升。
当模型具备大规模生成准则的能力后,GRM 便能够在更合理的准则框架下输出更细致的奖励评价,这对于推理阶段的可扩展性具有关键意义。
基于规则的强化学习
为同步优化 GRM 中的原则生成与批判生成,DeepSeek 提出 SPCT 框架,整合了拒绝式微调与基于规则的强化学习。拒绝式微调作为冷启动阶段。
拒绝式微调(冷启动阶段) 的核心目标是使 GRM 能够生成格式正确且适配多种输入类型的原则与批判。
不同于 Vu 等人(2024)、Cao 等人(2024)和 Alexandru 等人(2025)将单响应、配对响应和多响应格式的 RM 数据混合使用的方案,DeepSeek 采用第 2.1 节提出的逐点 GRM,能以统一格式为任意数量响应生成奖励。
数据构建方面,除通用指令数据外,DeepSeek 还通过预训练 GRM 对 RM 数据中不同响应数量的查询 - 响应对进行轨迹采样,每个查询 - 响应对采样
 次。拒绝策略也采用统一标准:拒绝预测奖励与真实值不符(错误)的轨迹,以及所有
次。拒绝策略也采用统一标准:拒绝预测奖励与真实值不符(错误)的轨迹,以及所有
次轨迹均正确(过于简单)的查询 - 响应对。形式化定义为:令
 表示查询 x 第 i 个响应
表示查询 x 第 i 个响应
 的真实奖励,当预测逐点奖励
的真实奖励,当预测逐点奖励
 满足以下条件时视为正确:
满足以下条件时视为正确:
 这里需确保真实奖励仅包含一个最大值。然而,与 Zhang 等人(2025a)的研究类似,DeepSeek 发现预训练 GRM 在有限采样次数内难以对部分查询及其响应生成正确奖励。
这里需确保真实奖励仅包含一个最大值。然而,与 Zhang 等人(2025a)的研究类似,DeepSeek 发现预训练 GRM 在有限采样次数内难以对部分查询及其响应生成正确奖励。
因此,他们选择性地在 GRM 提示中追加
 image.webp(称为暗示采样),期望预测奖励能与真实值对齐,同时保留非暗示采样方式。对于暗示采样,每个查询及其响应仅采样一次,仅当预测错误时才拒绝轨迹。相较于 Li 等人(2024a)和 Mahan 等人(2024)的研究,我们观察到暗示采样轨迹有时会简化生成的批判(尤其在推理任务中),这表明 GRM 在线强化学习的必要性和潜在优势。
image.webp(称为暗示采样),期望预测奖励能与真实值对齐,同时保留非暗示采样方式。对于暗示采样,每个查询及其响应仅采样一次,仅当预测错误时才拒绝轨迹。相较于 Li 等人(2024a)和 Mahan 等人(2024)的研究,我们观察到暗示采样轨迹有时会简化生成的批判(尤其在推理任务中),这表明 GRM 在线强化学习的必要性和潜在优势。
通过基于规则的在线 RL,研究者对 GRM 进行了进一步的微调。与 DeepSeek R1 不同的是,没有使用格式奖励。相反,为了确保格式和避免严重偏差,KL 惩罚采用了较大的系数。从形式上看,对给定查询 x 和响应
 的第 i 次输出 o_i 的奖励为:
的第 i 次输出 o_i 的奖励为:
 逐点奖励是
逐点奖励是
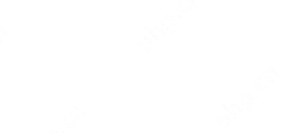 从 o_i 中提取的。
从 o_i 中提取的。
奖励函数鼓励 GRM 通过在线优化原则和批判来区分最佳响应,从而实现有效的推理时间扩展。奖励信号可以从任何偏好数据集和标注的 LLM 响应中无缝获取。
SPCT 的推理时扩展
为了进一步提高 DeepSeek-GRM 在使用更多推理计算生成通用奖励方面的性能,研究者探索了基于采样的策略,以实现有效的推理时可扩展性。
利用生成奖励进行投票。回顾第 2.1 节中的方法,逐点 GRM 的投票过程定义为奖励总和:
 其中,
其中,
 是第 i 个响应(i = 1, ..., n)的最终奖励。由于 S_i,j 通常设置在一个较小的离散范围内,例如 {1,...,10},因此投票过程实际上将奖励空间扩大了 k 倍,并使 GRM 能够生成大量原则,从而有利于提高最终奖励的质量和粒度。
是第 i 个响应(i = 1, ..., n)的最终奖励。由于 S_i,j 通常设置在一个较小的离散范围内,例如 {1,...,10},因此投票过程实际上将奖励空间扩大了 k 倍,并使 GRM 能够生成大量原则,从而有利于提高最终奖励的质量和粒度。
一个直观的解释是,如果每个原则都可以被视为判断视角的代表,那么更多的原则可能会更准确地反映真实的分布情况,从而提高效率。值得注意的是,为了避免位置偏差和多样性,在采样之前会对回答进行洗牌。
元奖励模型指导投票。DeepSeek-GRM 的投票过程需要多次采样,由于随机性或模型的局限性,少数生成的原则和评论可能存在偏差或质量不高。因此,研究者训练了一个元 RM 来指导投票过程。
引导投票非常简单: 元 RM 对 k 个采样奖励输出元奖励,最终结果由 k_meta ≤ k 个元奖励的奖励投票决定,从而过滤掉低质量样本。
奖励模型 Benchmark 上的结果
不同方法和模型在奖励模型基准测试上的整体结果如表 2 所示。
 不同方法在推理阶段的扩展性能结果如表 3 所示,整体趋势可见图 1。
不同方法在推理阶段的扩展性能结果如表 3 所示,整体趋势可见图 1。
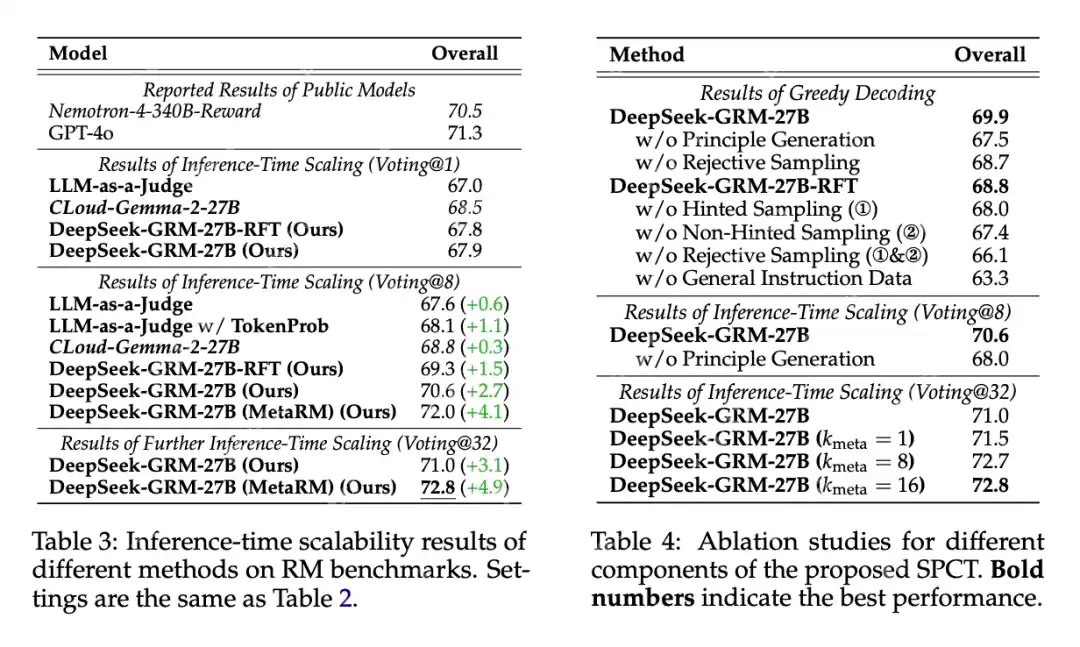 表 4 展示了 SPCT 各个组成部分所做的消融实验结果。
表 4 展示了 SPCT 各个组成部分所做的消融实验结果。
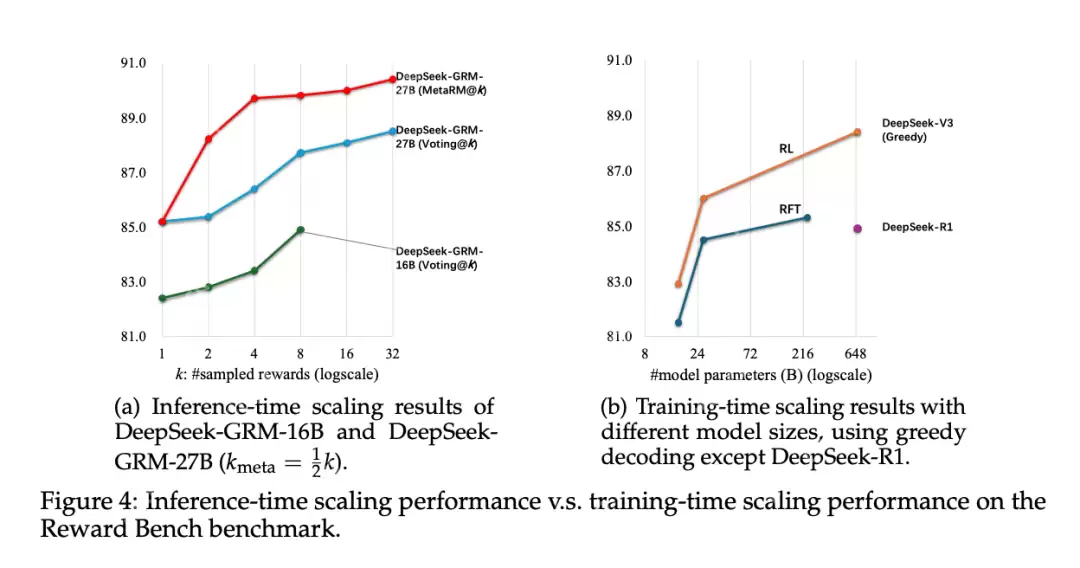
研究者们还进一步研究了 DeepSeek-GRM-27B 在推理阶段和训练阶段的扩展性能,通过在不同规模的 LLM 上进行后训练进行评估。所有模型均在 Reward Bench 上进行测试,结果如图 4 所示。
 更多研究细节,可参考原论文。
更多研究细节,可参考原论文。
© THE END
转载请联系本公众号获得授权
相关攻略

PHPMailer 邮件发送失败的常见原因与完整调试指南 本文深入解析使用PHPMailer时,表单提交成功但收不到邮件的典型故障。我们将重点排查主题字段缺失、SMTP服务器配置错误、HTML内容转义问题及安全策略拦截等核心原因,并提供可直接部署的修复代码与生产环境最佳实践方案。 许多PHP开发者在

AI艺术提示生成器是什么 简单来说,你可以把它理解为一个永不枯竭的创意火花塞。这个基于前沿AI技术的工具,专为破解创作瓶颈而生,无论你是专业画师还是灵感偶尔“罢工”的爱好者,它都能派上用场。它的工作原理并不复杂:依托当前顶级的OpenAI模型,将你的初步想法“催化”成一系列具体、新颖且富有启发性的艺

Vose AI是什么 说起AI绘画工具,市面上的选择已经不少了。但今天要聊的这个Vose AI,还真有点不一样。它是由Vose团队精心打造的一个AI图像生成平台,核心目标很明确:把你脑子里那些天马行空的创意点子,变成实实在在、令人眼前一亮的图像作品。无论你是靠画笔和灵感吃饭的专业艺术家、设计师,还是

Kanaries AI Exploratory Data Analysis是什么 提到数据探索分析,很多人脑子里立马会蹦出复杂的代码和令人眼花缭乱的报表。但今天要聊的这款工具——Kanaries AI Exploratory Data Analysis(简称Kanaries AI EDA),正致力于

提案精灵是什么 如果你也在自由职业平台找过活,大概率体会过刷完项目、撰写提案、反复修改这个过程的耗时耗力。提案精灵(Proposal Genie)的出现,就是想把自由职业者从这个重复劳动中解放出来。简单说,它就是一款专门为Upwork、Freelancer com这类平台量身定制的AI工具,核心任务
热门专题







热门推荐

“我们的代码,终将写入繁星”:追觅科技成立天文BU,构建从地面到太空的生态闭环 “我们的代码,终将写入繁星。”这句来自追觅科技的宣言,不只是一句诗意的口号,更是一份清晰的战略升级路线图。就在9月10日,这家中国科技企业正式宣告成立天文业务单元(BU),由此完成了一次至关重要的战略跃迁。这标志着其“全

Just Learn是什么 提起用AI为教育赋能,Just Learn这款工具是个绕不开的名字。它由Just Learn公司开发,核心目标非常明确:一手帮教师扩展专业能力,一手为学生打造个性化的学习旅程。说到底,它的价值在于通过AI驱动学习和24 7全天候辅导这两大核心,把教育资源重新“盘活”,让老

Vue 渲染机制深度解析:Patch 函数核心逻辑与优化策略 Vue js 的响应式系统实现了数据驱动视图的核心理念。然而,当数据发生变化时,视图是如何被高效且准确地更新的呢?这背后的核心引擎,正是虚拟 DOM 体系中的 Patch 函数。它并非直接操作真实 DOM,而是通过深度比对新旧虚拟节点(V

《空之轨迹SC》完全重制版《空之轨迹 the 2nd》正式定档2026年9月17日,登陆多平台 日本Falcom官方正式公布,经典日式角色扮演游戏《空之轨迹SC》的完全重制版——《空之轨迹 the 2nd》,将于2026年9月17日全球同步发售。本作将登陆任天堂Switch 2、Switch、Pla
AI艺术提示生成器是什么 简单来说,你可以把它理解为一个永不枯竭的创意火花塞。这个基于前沿AI技术的工具,专为破解创作瓶颈而生,无论你是专业画师还是灵感偶尔“罢工”的爱好者,它都能派上用场。它的工作原理并不复杂:依托当前顶级的OpenAI模型,将你的初步想法“催化”成一系列具体、新颖且富有启发性的艺