deepseek开源周第三天为我们带来了deepgemm,一个fp8通用矩阵乘法(gemm)库,专门为高效、干净的fp8 gemm 设计,支持密集 gemm 和 moe gemm,用于v3/r1训练和推理。
 DeepGEMM 是一个专为FP8 GEMM 设计的库,采用细粒度缩放,如DeepSeek-V3中所建议。它支持普通和混合专家(MoE)分组 GEMM。该库使用CUDA编写,通过轻量级即时(JIT)模块在运行时编译所有内核,无需在安装时编译。
DeepGEMM 是一个专为FP8 GEMM 设计的库,采用细粒度缩放,如DeepSeek-V3中所建议。它支持普通和混合专家(MoE)分组 GEMM。该库使用CUDA编写,通过轻量级即时(JIT)模块在运行时编译所有内核,无需在安装时编译。
目前,DeepGEMM 仅支持NVIDIA Hopper 张量核。为了解决FP8 张量核心累积不精确的问题,它采用了CUDA 核心两级累积(提升)。虽然它借鉴了CUTLASS 和 CuTe 的一些概念,但避免了对它们的模板或代数的严重依赖。相反,该库设计简洁,只有一个核心内核函数包含大约300行代码。这使其成为学习Hopper FP8 矩阵乘法和优化技术的干净且易于访问的资源。
尽管采用轻量级设计,DeepGEMM 的性能与各种矩阵形状的专家调优库相当或超过。
⚡ 在Hopper GPU 上高达1350+ FP8 TFLOPS
✅ 没有繁重的依赖,像教程一样干净
✅ 完全Just-In-Time 编译
✅ ~300行的核心逻辑 - 但在大多数矩阵大小中都优于专家调优的内核
✅ 支持密集布局和两种MoE 布局
适用于:
Hopper 架构GPU,必须支持 sm_90aPython 3.8 或更高版本CUDA 12.3 或更高版本,强烈建议使用12.8 或更高版本以获得最佳性能PyTorch 2.1 或更高版本CUTLASS 3.6 或以上(可由Git 子模块克隆) 在H800 上使用NVCC 12.8 测试了DeepSeek-V3/R1 推理中可能使用的所有形状(包括预填充和解码,但没有张量并行)。
在H800 上使用NVCC 12.8 测试了DeepSeek-V3/R1 推理中可能使用的所有形状(包括预填充和解码,但没有张量并行)。
DeepGEMM 在多种矩阵形状下的性能表现如下:
 普通 GEMM(密集模型)
普通 GEMM(密集模型)M N K 计算量 (TFLOPS) 内存带宽 (GB/s) 速度提升 64
2112
7168
206
1688
2.7x
64
24576
1536
289
2455
1.7x
64
32768
512
219
2143
1.8x
64
7168
16384
336
2668
1.4x
64
4096
7168
287
2320
1.4x
64
7168
2048
295
2470
1.7x
128
2112
7168
352
1509
2.4x
128
24576
1536
535
2448
1.6x
128
32768
512
358
2103
1.5x
128
7168
16384
645
2604
1.4x
128
4096
7168
533
2221
2.0x
128
7168
2048
510
2277
1.7x
4096
2112
7168
1058
527
1.1x
4096
24576
1536
990
786
1.0x
4096
32768
512
590
1232
1.0x
4096
7168
16384
1358
343
1.2x
4096
4096
7168
1304
500
1.1x
4096
7168
2048
1025
697
1.1x
分组 GEMM(连续布局,MoE 模型)分组数 每组 M N K 计算量 (TFLOPS) 内存带宽 (GB/s) 速度提升 4
8192
4096
7168
1297
418
1.2x
4
8192
7168
2048
1099
681
1.2x
8
4096
4096
7168
1288
494
1.2x
8
4096
7168
2048
1093
743
1.1x
分组 GEMM(掩码布局,MoE 模型)分组数 每组 M N K 计算量 (TFLOPS) 内存带宽 (GB/s) 速度提升 1
1024
4096
7168
1233
924
1.2x
1
1024
7168
2048
925
968
1.2x
2
512
4096
7168
1040
1288
1.2x
2
512
7168
2048
916
1405
1.2x
4
256
4096
7168
932
2064
1.1x
4
256
7168
2048
815
2047
1.2x
性能对比图: 架构特性示意图
架构特性示意图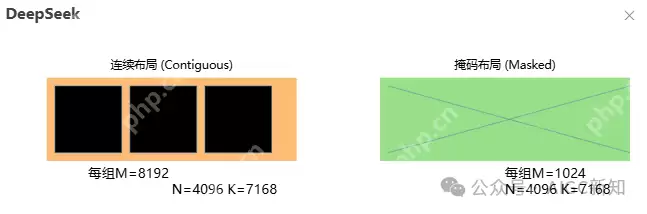 分组GEMM布局对比接口说明DeepGEMM 提供了以下主要接口:
分组GEMM布局对比接口说明DeepGEMM 提供了以下主要接口:
普通 GEMM:deep_gemm.gemm_fp8_fp8_bf16_nt,支持非分组的FP8 GEMM。分组 GEMM(连续布局):m_grouped_gemm_fp8_fp8_bf16_nt_contiguous,适用于MoE 模型的训练前向传播或推理预填充。分组 GEMM(掩码布局):m_grouped_gemm_fp8_fp8_bf16_nt_masked,适用于推理解码阶段。此外,还提供了一些辅助工具函数,例如设置最大SM 数量、获取TMA 对齐大小等。
优化技术DeepGEMM 的优化技术包括:
持久化warp 专业化:通过warp 专业化实现数据移动、Tensor Core MMA 指令和CUDA Core 提升的重叠。Hopper TMA 特性:利用Tensor Memory Accelerator(TMA)进行快速异步数据移动。统一优化的块调度器:为所有非分组和分组内核提供统一调度。完全JIT 设计:运行时即时编译,无需安装时编译,支持动态优化。未对齐块大小:针对某些形状优化SM 利用率。FFMA SASS 交错:通过修改编译后的二进制指令提升性能。如果觉得不错,欢迎点赞、在看、转发,您的转发和支持是我不懈创作的动力~




