在当今数据驱动的时代,数据分析已成为企业决策和业务优化的关键。deepseek 作为一款强大的数据分析工具,能够帮助我们快速从海量数据中提取有价值的信息。本文将详细介绍如何将 ollama+python+deepseek 与数据库结合,进行高效的数据分析。
2、环境准备这里我自己使用的是Windows11操作系统,因此接下来全部以Windows11操作系统为例。
windows11,配置8vCPU,16GB内存,512G磁盘Mysql数据库,这里使用了MySQL5.7版本Python环境,这里使用的是Python 3.11执行器3、本地部署3.1、安装ollama首先,到ollama官网下载对应版本,windows操作系统需要windows10及以上的版本。下载完成后,直接点击安装即可。
安装完成后,在终端窗口输入以下命令:
代码语言:bash复制ollama -v登录后复制
可以看到对应的ollama版本,即表示安装成功。
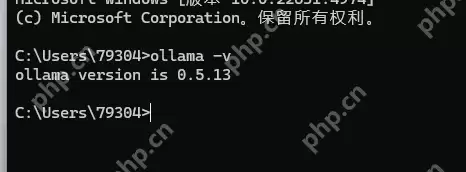
在ollama官网,搜索我们要部署的模型,这里选择deepseek-r1模型,可以看到列出所有蒸馏版本,我们这里由于配置原因,选择1.5b版本。
立即学习“Python免费学习笔记(深入)”;
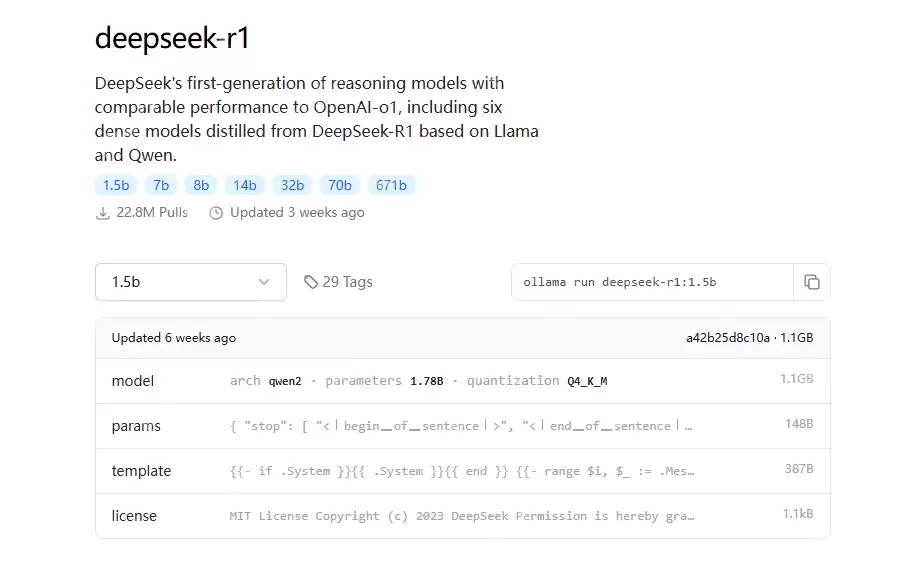
接着输入以下命令,进行拉取模型:
代码语言:bash复制ollama pull deepseek-r1:1.5b# 当然也可以一部到位直接启动ollama run deepseek-r1:1.5b登录后复制
显示success,即表示拉取成功。

拉取成功后,启动该模型:
代码语言:bash复制ollama run deepseek-r1:1.5b登录后复制
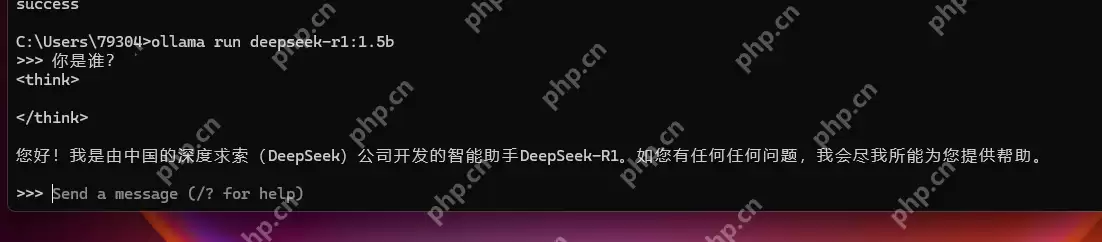
到此,已经启动成功:
可以进行对话了:
这里先给出Python这次所需要的一些依赖库,requirements.txt:
代码语言:bash复制mysql-connector-python==8.1.0ollama==0.1.6python-dotenv==1.0.0登录后复制
通过命令安装依赖库:
代码语言:bash复制pip install -r requirements.txt登录后复制4.1、示例代码
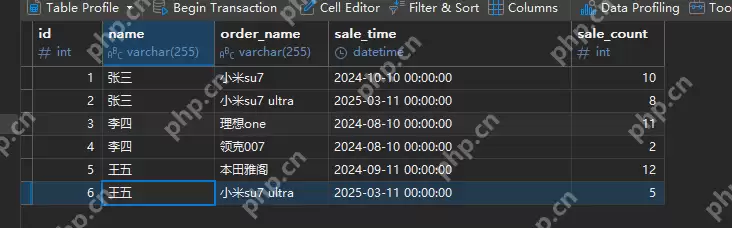
假设我们有一张表sale_orders的DDL如下:
代码语言:sql复制CREATE TABLE `wxmapp`.`Untitled` ( `id` int NOT NULL, `name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '销售人员名称', `order_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '订单车型', `sale_time` datetime NULL DEFAULT NULL COMMENT '销售日期', `sale_count` int NULL DEFAULT NULL COMMENT '销售数量', PRIMARY KEY (`id`) USING BTREE) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;登录后复制
预生成的数据:
接着,我们尝试让DeepSeek分析出销量最高的订单车型。以下是完整代码:
代码语言:python代码运行次数:0运行复制import mysql.connectorimport ollama# 数据库连接配置(使用mysql.py中的配置)config = { 'user': 'xxx', 'password': 'xxx', 'host': 'xxx', 'database': 'xxx', 'raise_on_warnings': True, 'charset': 'utf8mb4'}# 连接数据库try: conn = mysql.connector.connect(**config) cursor = conn.cursor() cursor.execute("SELECT order_name, sale_count FROM sale_orders") rows = cursor.fetchall() # 使用 DeepSeek 处理数据 result = ollama.generate(model='deepseek-r1:1.5b', prompt=f'有一张销售订单数据:{rows}。其中order_name表示订单车型名称,sale_count表示销售数量。现在请分析销量前三的订单车型。直接给出结果,不需要给出推理过程').get( 'response', '') print(f"DeepSeek Analysis: {result}")except mysql.connector.Error as err: print(f"Error: {err}")finally: # 关闭连接 if conn.is_connected(): cursor.close() conn.close()登录后复制运行后得到结果:
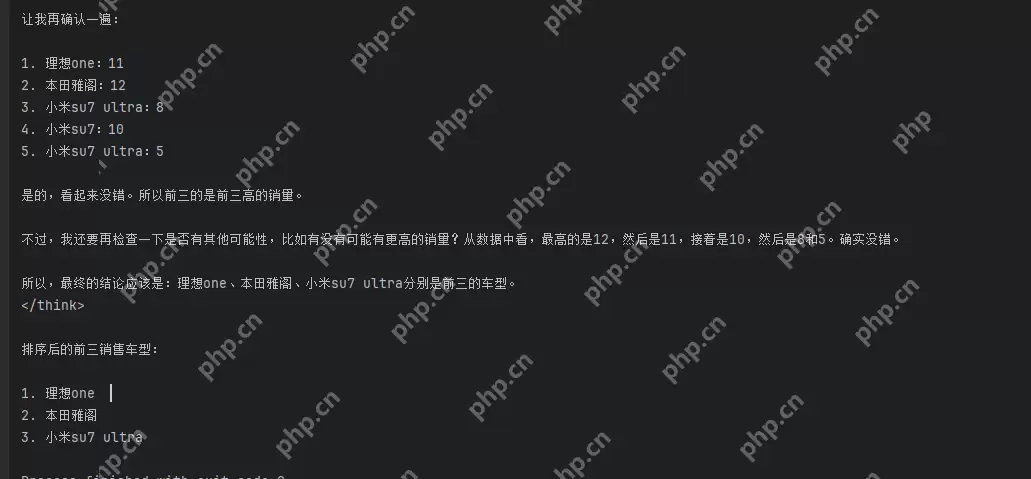
上面是简单的DeepSeek进行数据分析的功能,对于数据量小的来说可能还行,但是对于数据量大的来说还是够呛。但是我们可以用他来进行一些数据结构的完整性检查、有效性检查以及给出一些合理的建议。
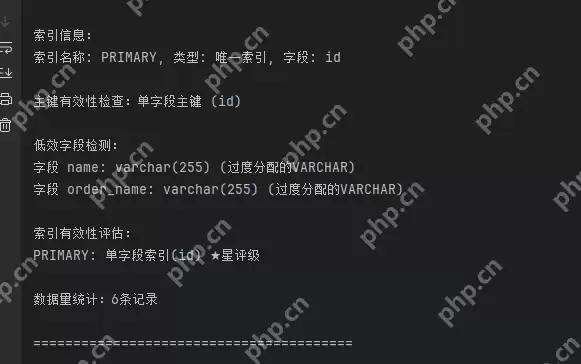
这里我添加了一些额外的功能,用于扫描库表是否包含了主键,是否字段长度过长没有约束,是否时间类型用了字符串等。
代码语言:python代码运行次数:0运行复制# 连接数据库try: conn = mysql.connector.connect(**config) cursor = conn.cursor() # 执行查询 # 获取索引信息 cursor.execute("SHOW INDEX FROM sale_orders") indexes = cursor.fetchall() print("\n索引信息:") for index in indexes: print(f"索引名称: {index[2]}, 类型: {'唯一索引' if index[1] == 0 else '普通索引'}, 字段: {index[4]}") # 增强主键检测 cursor.execute(""" SELECT GROUP_CONCAT(DISTINCT COLUMN_NAME) FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE TABLE_NAME = 'sale_orders' AND CONSTRAINT_NAME = 'PRIMARY'""") pk_info = cursor.fetchall() # 多层空值检查和类型验证 if pk_info and len(pk_info) > 0 and pk_info[0] and len(pk_info[0]) > 0: primary_key = pk_info[0][0] if isinstance(primary_key, str): columns = primary_key.split(',') columns_count = len(columns) columns_str = primary_key else: columns_count = 0 columns_str = '' else: columns_count = 0 columns_str = '' status_desc = ( f'复合主键({columns_count}个字段)' if columns_count > 1 else '单字段主键' if columns_count == 1 else '无主键' ) print(f"\n主键有效性检查:{status_desc} ({columns_str})") # 字段类型效率检查(扩展白名单机制) cursor.execute(""" SELECT COLUMN_NAME, COLUMN_TYPE, DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = 'sale_orders' AND (DATA_TYPE IN ('text','blob') OR COLUMN_TYPE LIKE '%varchar(255)%' OR NUMERIC_SCALE IS NULL AND DATA_TYPE = 'decimal' OR (COLUMN_NAME LIKE '%time%' AND DATA_TYPE NOT IN ('date','datetime','timestamp')))""") inefficient_columns = cursor.fetchall() print("\n低效字段检测:") for col in inefficient_columns: reason = 'TEXT/BLOB类型' if col[2] in ('text','blob') else \ '过度分配的VARCHAR' if 'varchar(255)' in col[1] else \ '不精确的DECIMAL类型' if col[2] == 'decimal' and NUMERIC_SCALE is None else \ '时间字段使用字符串类型' if 'time' in col[0].lower() and col[2] in ('varchar','text') else '未知类型' print(f"字段 {col[0]}: {col[1]} ({reason})") # 索引有效性评估 cursor.execute("SHOW INDEXES FROM sale_orders") indexes = {} for idx in cursor.fetchall(): if idx[2] not in indexes: indexes[idx[2]] = {'columns': [], 'unique': idx[1]} indexes[idx[2]]['columns'].append(idx[4]) print("\n索引有效性评估:") for idx_name, meta in indexes.items(): coverage = '复合索引' if len(meta['columns'])>1 else '单字段索引' score = '★'*(3 if meta['unique'] else 2 if len(meta['columns'])>1 else 1) print(f"{idx_name}: {coverage}({','.join(meta['columns'])}) {score}星评级") # 数据量统计 cursor.execute("SELECT COUNT(*) FROM sale_orders") record_count = cursor.fetchone()[0] print(f"\n数据量统计:{record_count}条记录{' (超过500万建议分表)' if record_count > 5000000 else ''}") print("\n" + "="*40 + "\n")except mysql.connector.Error as err: print(f"Error: {err}")finally: # 关闭连接 if conn.is_connected(): cursor.close() conn.close()登录后复制这里只是对单张表的检查:
如果重新封装一下,可以对我们整个库进行扫描,以及对我们数据进行基本的分析:
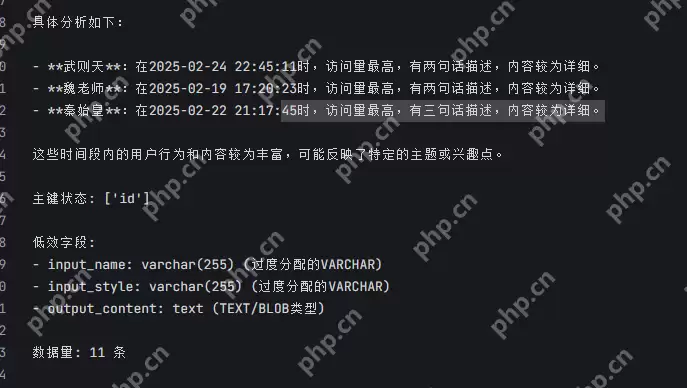
甚至给出了数据中访问量最高的分析,预测了主题趋势和兴趣点。
不仅支持MySQL数据库,同样支持主流的PostgreSQL和SQLite等。
4.3.1、PostgreSQL 示例代码语言:python代码运行次数:0运行复制import psycopg2# 数据库连接配置conn = psycopg2.connect( dbname="your_database", user="your_username", password="your_password", host="your_host", port="your_port")cursor = conn.cursor()cursor.execute("SELECT * FROM your_table")rows = cursor.fetchall()for row in rows: print(row)cursor.close()conn.close()登录后复制4.3.2、SQLite 示例代码语言:python代码运行次数:0运行复制import sqlite3# 连接 SQLite 数据库conn = sqlite3.connect('your_database.db')cursor = conn.cursor()cursor.execute("SELECT * FROM your_table")rows = cursor.fetchall()for row in rows: print(row)cursor.close()conn.close()登录后复制5、总结如今AI火热的年代,大模型+数据分析必然是个趋势。构建从数据提取,到智能分析,再到可视化呈现的全流程自动化,以及风险预测和识别也将成为另一个业务价值呈现点。




