1.下载ollama
Ollama 是一个开源的大型语言模型(LLM)本地化部署框架,旨在简化用户在本地运行和管理大模型的流程。
https://ollama.com/download登录后复制
2.安装Ollama
安装过程与普通软件类似,只需双击exe文件即可完成安装。安装成功后,打开命令提示符,如下图所示。

3.下载并运行模型
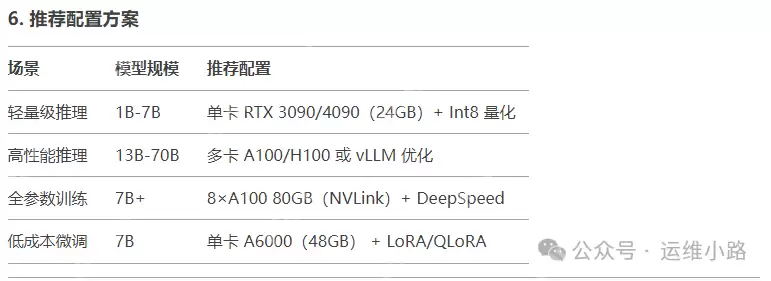
有多种模型可供选择,不同模型对配置的要求不同。如果仅使用CPU或只是体验功能,可以选择1.5b模型。下图展示了DeepSeek模型的推荐配置。
本次演示的服务器配置:CPU:I5 8400;内存:32G;显卡:两个显示器,一个接主板集成显卡,一个接独立显卡(亮机卡)。
https://ollama.com/library/deepseek-r1登录后复制
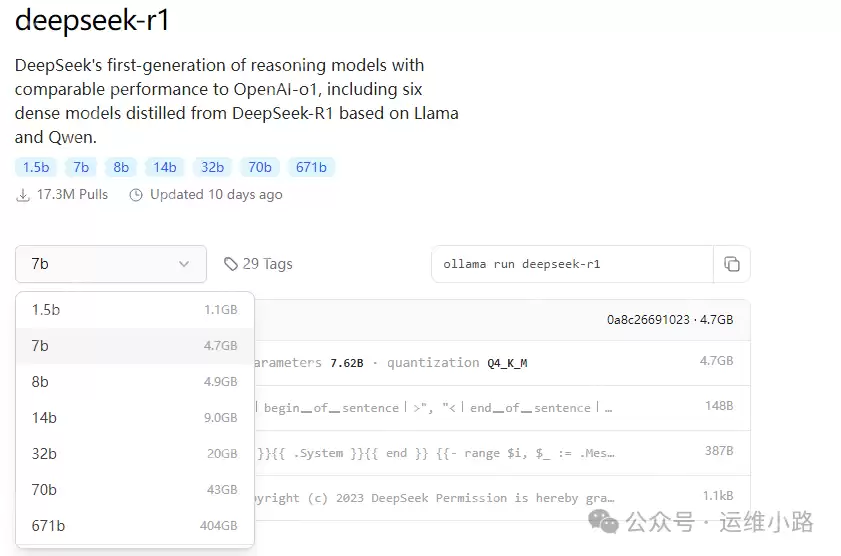

ollama run deepseek-r1:1.5b登录后复制
执行此命令后,模型会开始下载。下载速度开始时较快,后续会变慢。下载完成后会显示如下图所示的界面(由于我这里是关闭后重新运行的,所以看不到下载界面)。
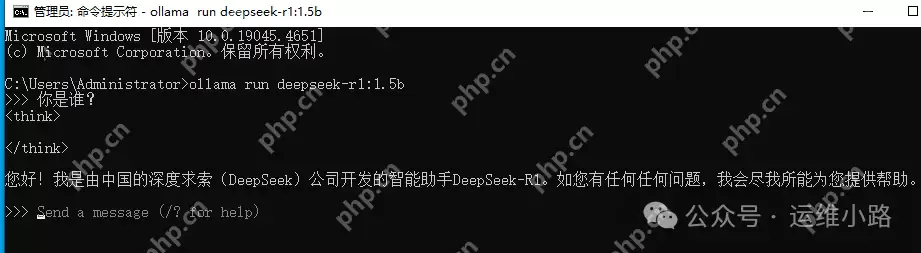
4.提问
由于没有其他接口来调用这个API,这里只能通过控制台进行访问。
5.接入第三方工具
https://cherry-ai.com/#下载并安装客户端登录后复制
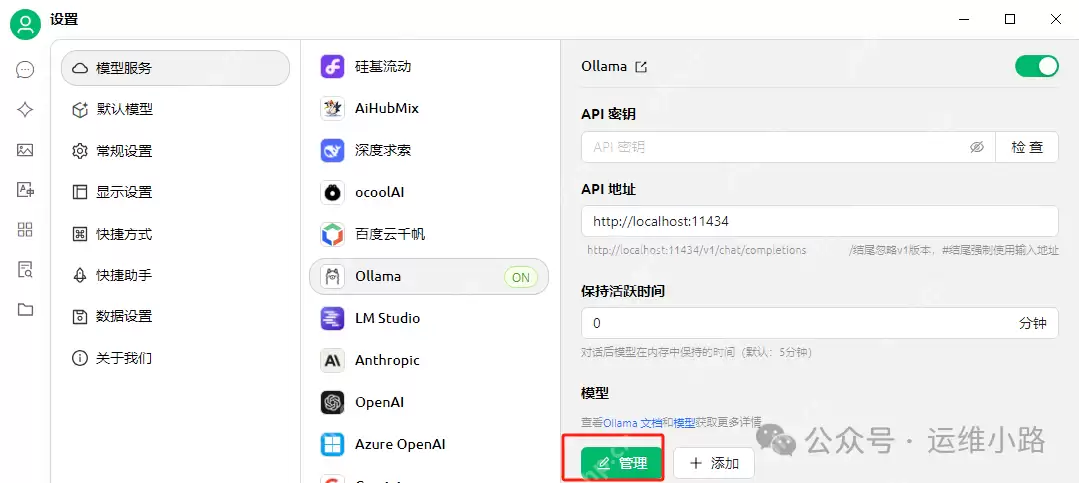
参考下图进行配置,选择管理,然后点击添加你本地的模型(它会自动识别你本地安装过的模型)。
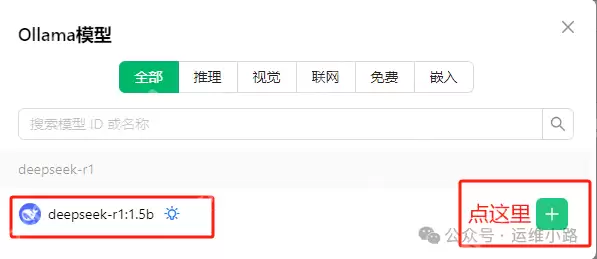
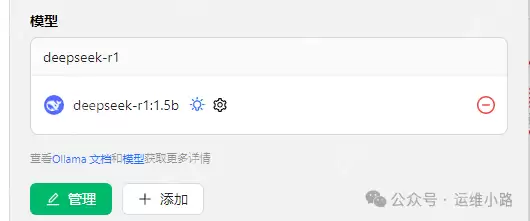
添加成功后,你可以看到本地的模型版本。
6.开始对话
回到工具左上角的对话界面,就可以进行对话。这里我们可以选择一个较为复杂的逻辑进行测试。
7.资源监控
从这里可以看到在回答问题时,CPU占用率很高,但内存占用率不是很高。当然,我选择的低配模型回答效果可能不如高配模型,但对于入门体验是足够的。