o3-mini数学推理暴打DeepSeek-R1?AIME 2025初赛曝数据集污染大瓜
新智元报道
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
编辑:编辑部 JHYZ
【新智元导读】刚刚发布的AIME 2025 I数学竞赛大模型参赛结果显示,o3-mini以78%的成绩拔得头筹,DeepSeek R1则以65%的成绩位列第四。然而,一位教授却发现了惊人的事实:一些仅1.5B参数的小模型居然也能达到50%的成绩。这是否意味着数据集存在污染?大语言模型究竟是真正学会了解决数学问题,还是仅仅记住了答案?
关于LLM的「Generalize VS Memorize」之争,近日有了新的进展。
苏黎世联邦理工学院的研究员Mislav Balunović在X上公布了一系列顶级AI推理模型在AIME 2025 I比赛中的表现。
 其中,o3-mini (high)以极低的成本解决了78%的问题,令人印象深刻。
其中,o3-mini (high)以极低的成本解决了78%的问题,令人印象深刻。
DeepSeek-R1解决了65%的问题,其蒸馏变体也表现出色,确立了其在开源模型中的领先地位。
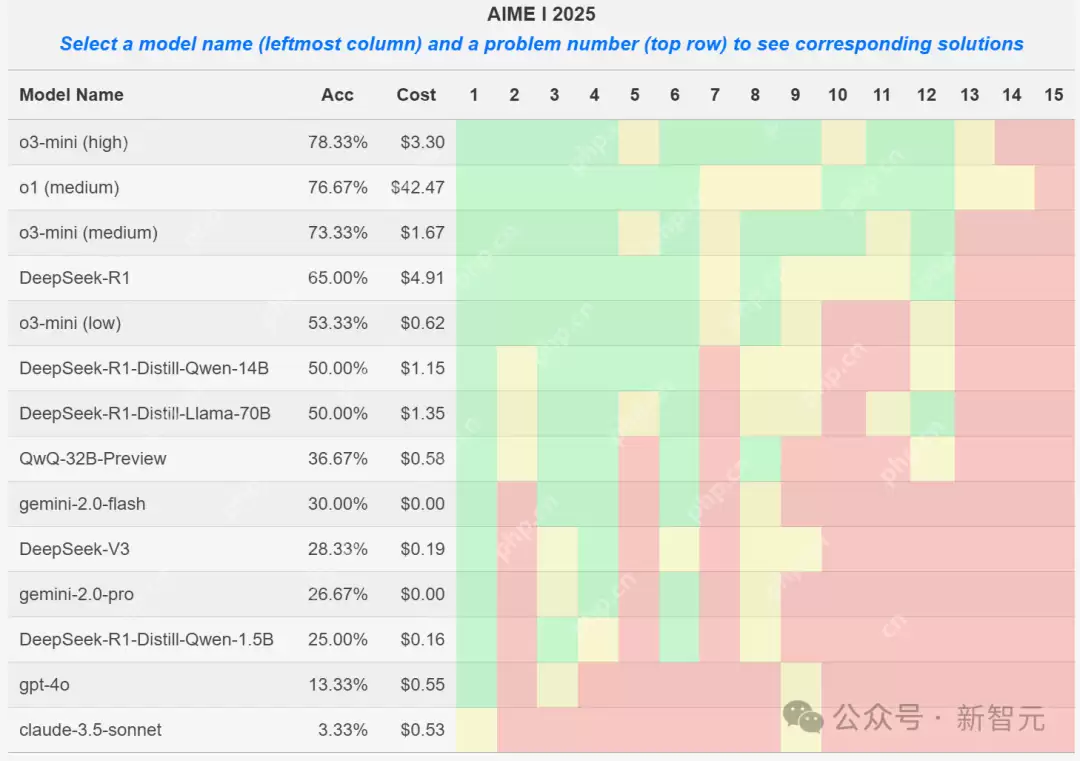 图中,绿色代表解答率超过75%,黄色代表解答率在25%-75%之间,红色代表解答率低于25%。
图中,绿色代表解答率超过75%,黄色代表解答率在25%-75%之间,红色代表解答率低于25%。
然而,这些结果是否真的可信?
 AI能够解决奥数题,是因为题目已经在网上泄露了吗?
AI能够解决奥数题,是因为题目已经在网上泄露了吗?
威斯康星大学麦迪逊分校的教授,现任微软研究员的Dimitris Papailiopoulos对此结果提出了质疑。
 教授对AI模型在数学题上的表现感到惊讶。
教授对AI模型在数学题上的表现感到惊讶。
他原本认为,小型蒸馏模型在面对这些题目时应该表现不佳,没想到它们却取得了25%到50%的分数。
这真是出乎意料!
要知道,如果这些题目是全新的,模型在训练过程中从未见过,那么小模型能拿到0分以上的分数就已经很不错了。
一个1.5B参数的模型连三位数的乘法都做不好,却能解决奥数题,这合理吗?
这不禁让人怀疑其中是否有问题。
 AIME I指的是2025年首场美国邀请数学考试,学生需要在三个小时内挑战15道难题。
AIME I指的是2025年首场美国邀请数学考试,学生需要在三个小时内挑战15道难题。
猜猜发生了什么?
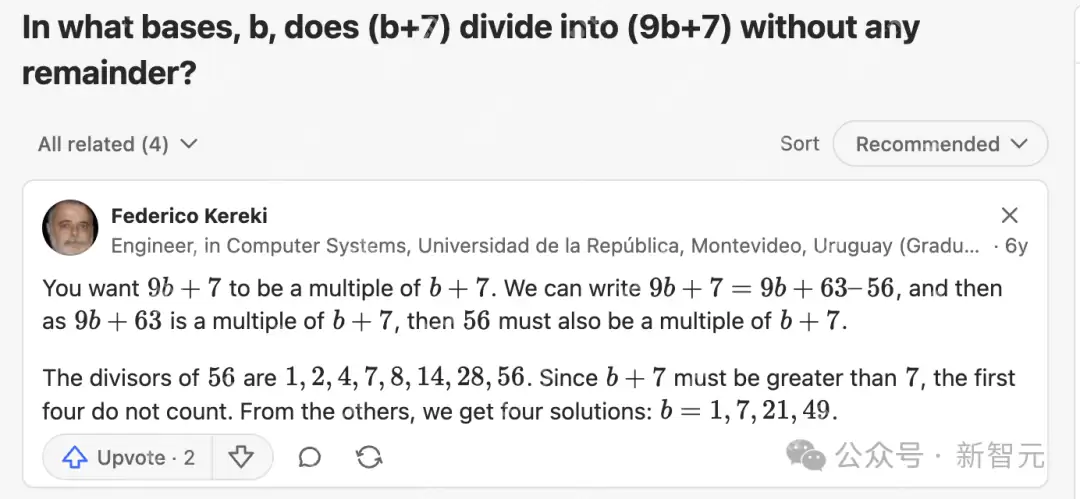
教授使用OpenAI Deep Research进行搜索后发现,AIME 2025的第1题在Quora上已经有了「原题」!
 而且这并非巧合,教授再次使用Deep Research查找了第3题,结果在math.stackexchange上找到了一个非常相似的问题:
而且这并非巧合,教授再次使用Deep Research查找了第3题,结果在math.stackexchange上找到了一个非常相似的问题:
 仍然感到怀疑的教授,使用DeepResearch继续查找了第7题。
仍然感到怀疑的教授,使用DeepResearch继续查找了第7题。
结果发现,一个完全相同的问题出现在2023年佛罗里达在线数学公开赛的第9题中。
 接下来,教授放弃了,因为p值已经低得不能再低。
接下来,教授放弃了,因为p值已经低得不能再低。
他提出了疑问:这对数学基准意味着什么?对RL的快速发展又意味着什么?
教授表示自己并不确定,但他也不排除GRPO(一种强化学习优化策略)在增强模型记忆的同时,也提高了其数学技能的可能性。
至少,这件事表明了一点:数据净化非常困难。
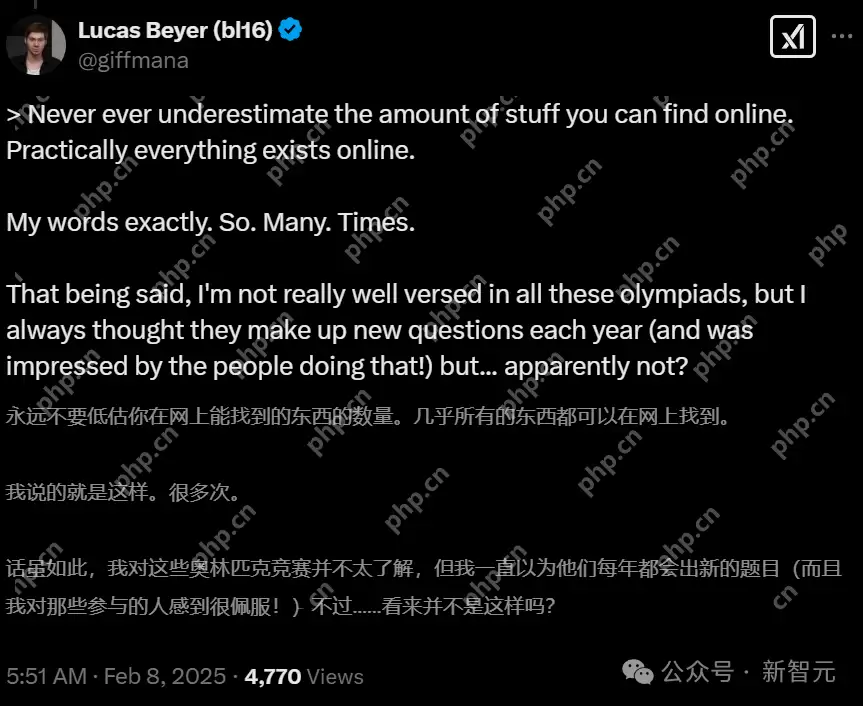
永远不要低估你在互联网上能找到的东西。几乎所有东西都能在网上找到。
网友们也表示,虽然数学奥赛每年都会出新题,但根本无法100%保证之前没有同样的问题出现过。
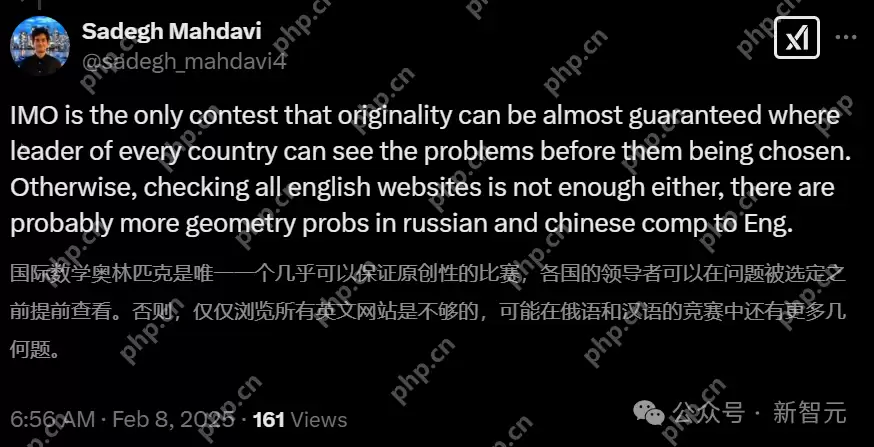 还有好奇的网友也进行了搜索。
还有好奇的网友也进行了搜索。
其中,第6题似乎有原题,第8题和第10题都有略微相似的题型。
 这不禁让人想起OpenAI秘密资助某数据集的旧闻:如果没有特殊目的,为什么不告诉出题的数学家呢?
这不禁让人想起OpenAI秘密资助某数据集的旧闻:如果没有特殊目的,为什么不告诉出题的数学家呢?
难道真如网友Noorie所言「数据去污才是新的Scaling Law」?
 什么是MathArena?
什么是MathArena?
MathArena是一个用于评估大模型在最新数学竞赛和奥林匹克竞赛中的表现的平台。
它的核心使命是,对LLM在「未见过的数学问题」上的推理能力和泛化能力进行严格评估。
为了确保评估的公平性和数据的纯净性,研究人员仅在模型发布后进行竞赛测试,避免使用可能泄漏的或预先训练的材料进行回溯评估。
 通过标准化评估,MathArena能够确保模型的得分可以实际比较,而不会受到模型提供方特定评估设置的影响。
通过标准化评估,MathArena能够确保模型的得分可以实际比较,而不会受到模型提供方特定评估设置的影响。
与此同时,研究人员会为每个竞赛发布一个排行榜,显示不同模型在各个单独问题上的得分。
此外,他们还将公开一个主表格,展示各个模型在所有竞赛中的整体表现。
为公平评估模型的表现,针对每个问题,每个模型均会进行4次重复评估,最后计算出平均得分以及模型运行成本(以美元计)。
参考资料:
https://www.php.cn/link/ef368049651bc5781718a8d879d9cd24
https://www.php.cn/link/4739d8dbd05dddb73604f6240b83ea68
https://www.php.cn/link/db03d49be7f821909335a60ea7fb7c59
https://www.php.cn/link/ca708d0d44450d9cb93c897bf6515cd3
相关攻略

近期,数字资产市场出现了一个备受瞩目的现象:一款名为$ani的ai伴侣概念币,在短时间内展现了惊人的涨幅,有数据显示其价格飙升了50倍。这种爆发式的增长,引发了市场对于此类新兴概念资产的广泛关注。 AI伴侣概念币$ANI的兴起 先说一个核心判断:AI伴侣概念,正成为数字货币领域一个引人遐想的新分支。

AI智能体:不止于代码的“智能实体” 提起“AI智能体”,你脑海中浮现的是科幻电影里的机器人形象,还是手机里那个能对话的语音助手?其实,这个概念比我们想象的更为广泛。简单来说,它是一种能够模拟人类智能、感知环境、处理信息并自主做出反应的技术实体或系统。根据能力范围,业内通常将其分为两类:专注于特定任

在Theodore Kane教授引领下,Marquess全球资产学院正通过人工智能与区块链技术重塑财富管理方式 金融科技的浪潮从未停歇,而这一次,由Theodore Kane领军的Marquess全球资产学院,正站在浪潮之巅。他们将尖端的AI分析能力与坚如磐石的区块链安全性深度融合,悄然开启了一种全

Floki或将迎来15%的上涨,对称三角形形态是否即将突破?能否冲破阻力? Floki 可能出现突破信号:对称三角形模式酝酿上行? Floki当前正展现出一些值得玩味的潜在上涨迹象。市场分析普遍关注一个关键点:如果那个顽固的阻力位能被有效突破,FLOKI的价格或许能迎来一波可观的涨幅,目标直指15%

4月24日,2026(第十九届)北京国际汽车展览会盛大启幕 作为行业年度重磅盛会,这场展会早已超越了传统汽车产业的范畴,成为跨领域科技融合的前沿阵地。一个引人注目的跨界亮点,是荣耀携人形机器人“闪电”“元气仔”,以及阿尔法战略落地的首个新物种Robot Phone集体亮相。这并非简单的展台陈列,而是
热门专题







热门推荐

RPA:跨系统迁移的高效引擎 谈到企业系统升级或整合,数据与业务流程的迁移往往是块难啃的硬骨头。好在,RPA(机器人流程自动化)的出现,为这项繁琐工程提供了高效且精准的自动化解决方案。它就像一位不知疲倦的数字搬运工,在异构系统间架起了一座桥梁。 那么,RPA究竟能在哪些迁移场景中大显身手呢?范围其实

RPA如何重塑营销?九大核心应用场景深度解析 说到营销领域的效率革命,RPA(机器人流程自动化)正悄然改变游戏规则。它不再是实验室里的概念,而是实实在在地渗透到营销工作的毛细血管中,从数据收集到广告优化,为团队按下“加速键”。让我们具体拆解一下,这技术究竟能在哪些核心环节大显身手。 数据收集与处理:

在RPA中实现高效自动化的核心:多机器人协作 说到RPA(机器人流程自动化)如何真正提升效率,秘诀往往不在于单个机器人的能力有多强,而在于多个机器人如何“拧成一股绳”协同工作。这正是多机器人协作这门学问的价值所在,它通常围绕几个关键环节展开。 任务分配与调度:需要一个“智慧大脑” 第一步,需要一个中

RPA技术在多店铺批量铺货中的实战操作指南 想要用RPA给多个店铺批量铺货,听起来似乎复杂,其实只要思路清晰、步骤对路,自动化流程搭建起来并不难。核心在于,你得把整个流程看成一条标准化的流水线,让机器人精准地执行每个环节。下面,咱们就拆解一下具体的实现步骤。 第一步:统一数据源——打好自动化地基 这

要自动获取发票信息并将相关信息存储到表格中 这事儿听起来技术含量不低,但说白了,核心就是让机器看懂发票、读懂内容,再规规矩矩地放进表格里。咱们一步步拆解来看,其实思路可以梳理得非常清晰。 数据获取:打通信息来源 首先得解决发票从哪儿来的问题。电子发票自然是最方便的,通过系统对接或者自动抓取电子邮件附