使用 DeepSeek R1 和 Ollama 搭建一个 RAG 系统(包含完整代码)
你有没有想过,能不能像跟人聊天一样,直接问 pdf 文件或技术手册问题?比如你有一本很厚的说明书,不想一页页翻,只想问它:“这个功能怎么用?”或者“这个参数是什么意思?”现在有了 ai 技术,这完全可以实现!
这篇文章教你如何用两个工具(DeepSeek R1 和 Ollama)来搭建一个智能系统,让它帮你从 PDF 里找答案。这个系统叫 RAG(检索增强生成),简单来说就是:先找资料,再生成答案。
为什么要用 DeepSeek R1?省钱:它比 OpenAI 的模型便宜 95%,效果却差不多。精准:每次只从 PDF 里找 3 个相关片段来回答问题,避免瞎编。本地运行:不用联网,速度快,隐私也有保障。你需要准备什么?Ollama:一个让你在电脑上本地运行 AI 模型的工具。
下载地址:https://ollama.com/
DeepSeek R1 模型:有不同大小,最小的 1.5B 模型适合普通电脑,更大的模型效果更好,但需要更强的电脑配置。
运行小模型:ollama run deepseek-r1:1.5b通用配置原则 模型显存占用(估算):
每 1B 参数约需 1.5-2GB 显存(FP16 精度)或 0.75-1GB 显存(INT8/4-bit 量化)。例如:32B 模型在 FP16 下需约 48-64GB 显存,量化后可能降至 24-32GB。内存需求:至少为模型大小的 2 倍(用于加载和计算缓冲)。
存储:建议 NVMe SSD,模型文件大小从 1.5B(约 3GB)到 32B(约 64GB)不等。
怎么搭建这个系统?第一步:导入工具包我们用 Python 写代码,需要用到一些工具包:
LangChain:处理文档和检索。Streamlit:做一个简单的网页界面。代码语言:javascript代码运行次数:0运行复制import streamlit as stfrom langchain_community.document_loaders import PDFPlumberLoaderfrom langchain_experimental.text_splitter import SemanticChunkerfrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain_community.vectorstores import FAISSfrom langchain_community.llms import Ollama登录后复制
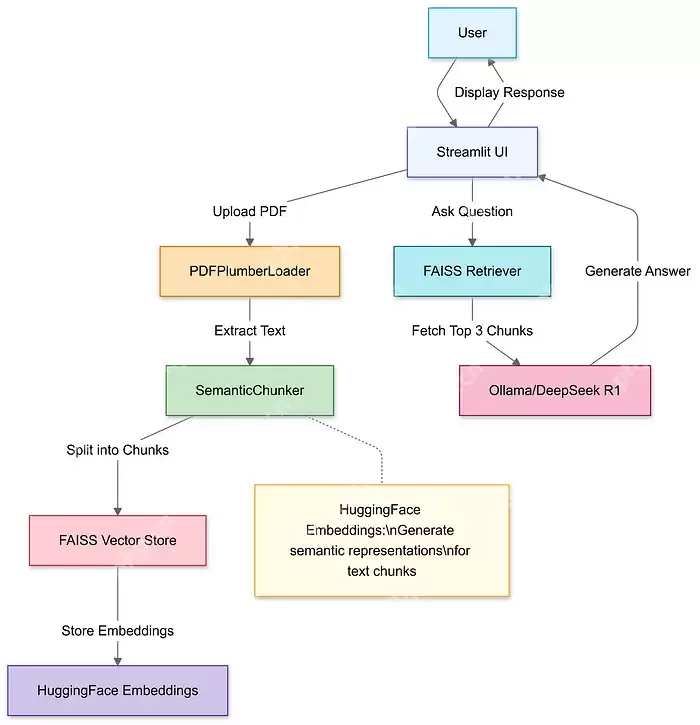
用 Streamlit 做一个上传按钮,把 PDF 传上去,然后用工具提取里面的文字。
代码语言:javascript代码运行次数:0运行复制uploaded_file = st.file_uploader("上传PDF文件", type="pdf")if uploaded_file: with open("temp.pdf", "wb") as f: f.write(uploaded_file.getvalue()) loader = PDFPlumberLoader("temp.pdf") docs = loader.load()登录后复制第三步:把 PDF 切成小块PDF 内容太长,直接喂给 AI 会吃不消。所以要把文字切成小块,方便 AI 理解。
代码语言:javascript代码运行次数:0运行复制text_splitter = SemanticChunker(HuggingFaceEmbeddings())documents = text_splitter.split_documents(docs)登录后复制
把切好的文字块转换成向量(一种数学表示),存到一个叫 FAISS 的数据库里。这样 AI 就能快速找到相关内容。
代码语言:javascript代码运行次数:0运行复制embeddings = HuggingFaceEmbeddings()vector_store = FAISS.from_documents(documents, embeddings)retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # 每次找3个相关块登录后复制第五步:设置 AI 模型用 DeepSeek R1 模型来生成答案。告诉它:只根据 PDF 内容回答,不知道就说“我不知道”。
代码语言:javascript代码运行次数:0运行复制llm = Ollama(model="deepseek-r1:1.5b")prompt = """1. 仅使用以下上下文。2. 如果不确定,回答“我不知道”。3. 答案保持在4句话以内。上下文: {context}问题: {question}答案:"""QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)登录后复制第六步:把整个流程串起来把上传、切块、检索和生成答案的步骤整合成一个完整的系统。
代码语言:javascript代码运行次数:0运行复制llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)document_prompt = PromptTemplate( template="上下文:
内容:{page_content}
来源:{source}", input_variables=["page_content", "source"])qa = RetrievalQA( combine_documents_chain=StuffDocumentsChain( llm_chain=llm_chain, document_prompt=document_prompt ), retriever=retriever)登录后复制第七步:做个网页界面用 Streamlit 做一个简单的网页,用户可以输入问题,系统会实时返回答案。
代码语言:javascript代码运行次数:0运行复制user_input = st.text_input("向你的PDF提问:")if user_input: with st.spinner("思考中..."): response = qa(user_input)["result"] st.write(response)登录后复制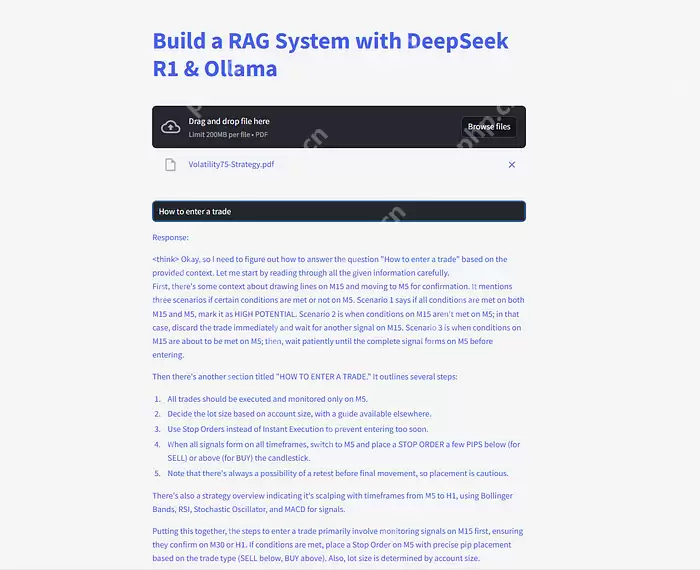
DeepSeek R1 只是开始,未来还会有更多强大的功能,比如:
自我验证:AI 能检查自己的答案对不对。多跳推理:AI 能通过多个步骤推导出复杂问题的答案。总结用这个系统,你可以轻松地从 PDF 里提取信息,像跟人聊天一样问问题。赶紧试试吧,释放 AI 的潜力!
相关攻略

Trae在Python数据分析与机器学习项目中主要通过四种方式提供支持:利用Auto模式自动生成并执行端到端分析脚本;通过AgentCLI命令行自动化机器学习建模流程;对现有代码进行智能调试与优化;借助语音交互快速构建数据处理函数。这些功能覆盖了从需求描述到代码生成、模型构建及代码优化的全流程。

在Python编程中,你是否也曾编写过类似的统计代码? 统计词频 count = {} for word in words: if word in count: count[word] += 1 else: count[word] = 1 实际上,这种高频的计数需求,完全可以通过Python内置

Trae稳定支持Python3 10至3 13版本,3 9及以下版本无法运行。Python3 14处于实验性支持阶段,核心功能可能受限。当存在多个3 10以上版本时,Trae优先选择虚拟环境中的解释器,其次为最高系统版本。此外,Trae仅兼容64位Python解释器,不支持32位架构。

在企业级数据采集与自动化运维实践中,IT团队普遍面临一个核心挑战:Python爬虫为何频繁报错,修补维护何时才能终结?随着前端技术演进与动态反爬机制的日益复杂,依赖DOM解析的传统爬虫脚本往往陷入“部署即过时,运行即异常”的困境。本文将深入解析传统爬虫代码脆弱性的根本原因,并系统介绍一种能够重塑数据

很多刚接触Docker的开发者常有一个误解:制作镜像不就是把源代码打包进去就行了吗?实际上,在企业级的标准化开发流程中,直接将源码打包进Docker镜像是非常不专业的做法。这会导致镜像体积臃肿、引入潜在安全风险,并且模糊了“构建环境”与“运行环境”的边界。本文将深入解析Java、Vue、Go、Pyt
热门专题







热门推荐

10月11日,加密货币市场经历剧烈波动,单日爆仓金额与人数双双突破历史纪录。市场行情极端变化导致大量杠杆交易者被强制平仓,凸显了加密货币投资的高风险特性。这一事件再次引发对市场波动性与风险管理的广泛关注。

过去24小时内,加密货币市场剧烈波动,导致全网大量交易者仓位被强制平仓。数据显示,爆仓人数高达162万,涉及金额巨大。市场普遍认为,此次暴跌与多重因素相关,包括宏观经济预期变化、监管政策不确定性以及部分大型投资者抛售行为。这一事件再次凸显了加密货币市场的高风险特性。

加密货币市场经历约160亿美元清算冲击后进入缓慢筑底阶段。高杠杆集中、价格波动加剧及恐慌情绪扩散引发连锁清算。比特币与以太坊反弹空间有限;瑞波币抗跌但波动加大;Solana受冲击明显。投资者应控制杠杆、分批建仓并关注市场动态。

加密货币市场剧烈波动,过去24小时内全网爆仓金额升至191亿美元,创下历史新高。市场多空博弈激烈,杠杆交易者大量被强制平仓,凸显了高杠杆交易在极端行情中面临的巨大风险。

加密货币市场剧烈震荡,比特币等主流币种价格集体下挫,导致超160万投资者被强制平仓。此次暴跌由宏观紧缩、高杠杆连锁平仓及市场恐慌情绪共同引发,形成下跌与抛售相互强化的恶性循环。建议通过降杠杆、设止损及分散资产组合以应对风险。