当你对手机语音助手说“帮我设一个明天早上6点的闹钟”,它听懂了指令并顺利执行。紧接着你又说道“改成7点半吧”——如果这个设备使用的是普通AI,它大概率会陷入困惑:啥改成7点半?改什么对象?因为它压根不记得你刚才提过“闹钟”,它只捕捉到了孤零零的一句“改成7点半”。
这个场景恰恰暴露了当前人工智能在处理连续信息时的一个短板:要么目光短浅,只关注当前这一句话;要么就得耗费巨大算力,强行将上下文数据硬塞入模型。而且,一旦涉及声音、手势、动作这类随时间流动的信息,问题就变得更加棘手。
帝国理工学院博士后孙鹏飞和苏黎世联邦理工博士后苏哲,携手他们的合作者,从人类大脑皮层中找到了一个有效的解决方案。两人在瑞士苏黎世联邦理工和苏黎世大学神经信息所相识,随即联手深入探索这一课题。他们发现,人脑在处理信息时,并非依靠一个统一的速度来运转。

图 | 左起;孙鹏飞、苏哲(来源:资料图)
具体来说:前额叶皮层处理信息的速度较慢,因此能够承担起整合长期上下文的重任;而初级感官皮层处理信息的速度较快,负责捕捉当下的即时刺激。正是这种快慢节奏的巧妙搭配,让大脑既能及时响应外界变化,又能牢牢记住上下文。
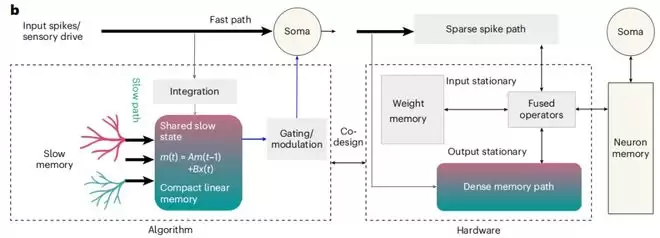
他们将这一机制构建成了一个名为“双重记忆路径”的类脑网络,并设计了一款配套芯片。在处理语音识别任务时,这颗芯片的能效比此前最优的方案提升了5倍之多。简而言之,他们等于将一项从大脑“偷师”而来的技术,发展到了可以装入芯片的程度,使得AI无需过长的上下文也能准确理解你的指令。
(来源:《自然·机器智能》)
孙鹏飞目前在帝国理工学院继续从事博士后研究,苏哲则加入了美国波士顿的一家芯片公司。近日,他们的研究成果发表于《自然·机器智能》。
就像开头那个例子所展示的,当前的AI在处理时序信息时存在一个“能力瓶颈”。处理一张图片它非常出色——比如著名的“看猫实验”,给AI观看一万张猫的照片,它就能学会识别猫。但处理一段声音或视频则完全不同:声音是一秒一秒流动过来的,上一秒的声音很可能影响下一秒的理解,AI必须记住“刚才发生了什么”,才能理解“现在到底发生了什么”。
(来源:《自然·机器智能》)
孙鹏飞和苏哲从大脑中获得了灵感。人类大脑皮层不同区域的神经元拥有不同的时间常数——有些区域处理信息快,对当下的刺激反应迅速;有些区域处理得慢,能够整合过去几秒甚至更长时间的信息。正是这种快慢分区机制,让大脑既能及时响应环境变化,又能保持对上下文的清晰感知。
他们在类脑网络的每一层里都增加了一个共享的小型慢速记忆模块。这个模块利用一个维度极低的状态向量来概括过去一段时间的信息——低维度意味着体积很小,仅需占用极少的存储和计算资源。这个状态向量能通过网络内部的连接反馈给该层的所有神经元,为它们提供“刚才到底发生了什么”的上下文信息。
这一思路也体现了两位博士对AI系统的深刻理解:神经网络模块应当是异构的,而对应的部署硬件也应当是异构融合的。为了进一步提升能效,他们还主张将记忆与计算相分离——记忆模块专注于存储和维持上下文,计算模块专注于处理当前输入,两者各自独立优化,避免相互干扰和资源争抢,从而使整体架构更加精简高效。
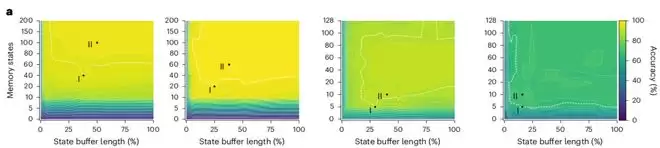
这个记忆模块的大小仅占整个网络参数的5%–10%,但效果却相当出色。在那些需要处理长时程信息的基准测试中,这套网络的准确率从10%迅速提升到了90%以上。在顺序MNIST数据集上,它更是达到了99%的准确率,比此前最好的同类模型高出近30%。
这个架构还有一个关键优势:由于记忆模块是共享的,它的开销不会随着神经元数量的增加而线性增长——网络规模越大,这个优势就越发明显。在参数量相同的情况下,双重记忆路径网络在准确率上明显优于传统的循环网络和延时网络。
算法设计完成后,硬件该如何实现?类脑计算领域一直存在一个尴尬局面:算法上的创新往往不考虑硬件是否能够实际落地。一些论文固然能够发表,但人们会很快发现那些精巧的设计在芯片上要么功耗过高,要么占用面积太大,最终只能停留在仿真阶段。
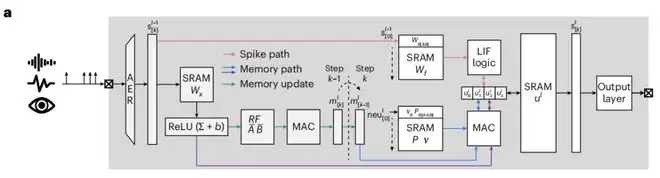
孙鹏飞和苏哲从一开始就在考虑硬件实现的问题。设计算法时,他们就在思考:这个记忆模块在芯片上如何存储?如何读取?如何计算?苏哲博士期间研究的正是类脑芯片设计,正是这一背景让他成为了算法与硬件之间的“翻译官”。
基于此,他们在算法层面做了几件事来降低硬件开销:
首先,既然记忆模块很小,就可以把它放在芯片的片上存储中,无需频繁访问外部内存;
其次,记忆更新和记忆读取可以并行处理,无需浪费时间排队等待;
再次,让稀疏的脉冲计算和密集的矩阵计算分别采用不同的数据流优化策略,各自进行针对性优化。
这些设计选择也相应地反映在了芯片架构上。他们研发的芯片采用了近存计算架构,将计算单元和存储单元放置得非常近,从而大幅缩短了数据搬运的距离。芯片内部设有四条并行的计算路径,分别负责处理脉冲积分、记忆读取、记忆更新和输出——这四条路径可以同时工作,无需互相等待。
他们将芯片在22纳米工艺上完成后布局仿真,结果显示:这套方案在处理语音识别任务时,能效比同类最好的设计高出5倍以上,吞吐量高出4倍,面积效率也比循环网络架构高出1倍——原因在于省去了存储循环权重矩阵的空间。
这些数字意味着什么?对于需要长时间连续工作的设备,例如智能手表、AR眼镜和助听器,能效提升5倍就能让电池续航时间延长数倍。对于需要实时响应的场景,比如语音助手和手势控制,吞吐量提升4倍则意味着更短的延迟和更流畅的用户体验。
这个芯片架构还有一个优势:它不依赖于底层的物理实现方式。既可以像文章介绍的那样,直接在特定工艺下实现优化策略以达成效率最大化,也可以将整套优化策略放在编译器层面实现,再映射到传统计算芯片上。
(来源:《自然·机器智能》)
但这篇论文的意义远不止于能效提升。它实际上展示了一种更为根本的思路:算法的设计从一开始就要考虑硬件的限制,而硬件的设计也要适配算法的特点——两者之间是相互塑造的关系。
硬件的限制乍看之下是个麻烦,但反过来却能推动智能的产生。我们的大脑本身就是在各种约束条件下进化出来的——能量预算仅有20瓦左右,却能完成超级计算机都难以胜任的任务。可以说,正是因为能量有限,大脑才进化出了一些极为高效的编码方式。
据了解,这项研究仍在继续深入。孙鹏飞未来会继续探索“将时间作为一种计算资源”,研究轴突延迟、系统级异构网络融合及其与异构硬件的适配。苏哲在新公司里也继续研究异构AI系统,类脑计算是其中一个重要的方向。目前,该工作已引起多家美国芯片公司的浓厚兴趣。
同时,这篇论文的全部代码和硬件设计已经开源,其他同行可以在此基础上继续改进,也可以集成到更大的系统中。这一做法在类脑计算领域并不常见——此前大多数工作只公开算法,硬件设计往往留在实验室中。对于个人未来的发展,孙鹏飞和苏哲对学术圈和工业界均持开放态度,渴望与优秀的同行共事,也并不排斥可能的创业机会。
参考资料:
相关论文 https://www.nature.com/articles/s42256-026-01255-3




