从“唯模型论”到“数据说了算”
面对一个新问题,很多人会不假思索地选择眼下表现最好的模型。这是人之常情。在当下这个节点,极限梯度提升几乎成了“靠谱”的代名词,而它也确实在许多任务中战功赫赫。
所以,当你看到我拿五个分类器在同一个任务上做对比,而那个只有一行代码的线性模型居然赢了Kaggle冠军时——这个结果,对于在真实数据上摸爬滚打过的工程师来说毫不意外,但对于还在学习阶段的人来说,却多少有点碘伏常识。
问题是这样的:五个分类器,相同的特征,预测国际足球比赛的结果——是主队获胜、打平还是客队赢。参选的模型包括:逻辑回归、随机森林、K近邻、小型神经网络,还有极限梯度提升。
最后,最简单的那个赢了。比“它赢了”更有意思的是“它为什么会赢”——而这背后藏着一个在应用机器学习中最实用的原理。下面就是这个实验的过程、结果以及拆解它的理论框架。
实验设置
这个发现在构建一个包含十一组世界杯预测模型时诞生。我当时需要一个结果分类器,并想搞清楚哪个模型家族最值得信赖。每个模型都使用相同的三个特征,数据来自358场国际比赛——包括2010年至2022年的世界杯,再加上2020年和2024年的欧洲杯。这三个特征是:球队之间的实力差距、球队总实力值以及是否属于淘汰赛。预测目标是主胜、平局、客胜三种结果。
我用5折交叉验证来评分,核心指标是log-loss,而非准确率。这个选择非常关键,它在后续分析中扮演了重要角色,所以有必要在开始时就挑明。准确率只关心预测概率最高的那个类别是否正确,而log-loss则对整个概率向量进行打分,并且会严厉惩罚那些自信却错误的预测:
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import log_loss, accuracy_score
proba = cross_val_predict(model, X, y, cv=5, method="predict_proba")
print(log_loss(y, proba), accuracy_score(y, proba.argmax(1)))
对于一个以输出校准概率为天职的预测模型来说,log-loss才是诚实的成绩单,而准确率只能算是个辅助参考。记住一个数字:ln(3) ≈ 1.099——这是你什么都不懂,直接猜三个结果各三分之一概率时得到的log-loss值。低于这个值,说明模型确实学到了一些东西;高于它,那还不如直接瞎猜来得靠谱。
实验结果
下面这张表格里有两个点会让你感到不安。
首先,领奖台上的冠军是平平无奇的逻辑回归,而极限梯度提升——那个在Kaggle竞赛中屡屡夺冠的模型——排到了最后。其次,还有一件更奇怪、也容易被人忽略的事:极限梯度提升不仅输了,它的评分居然高于1.099,也就是说,它还不如那个“均匀瞎猜”的基线模型。一个有48%准确率的模型,在这个任务真正关键的指标上,居然比三面的硬币还糟糕。
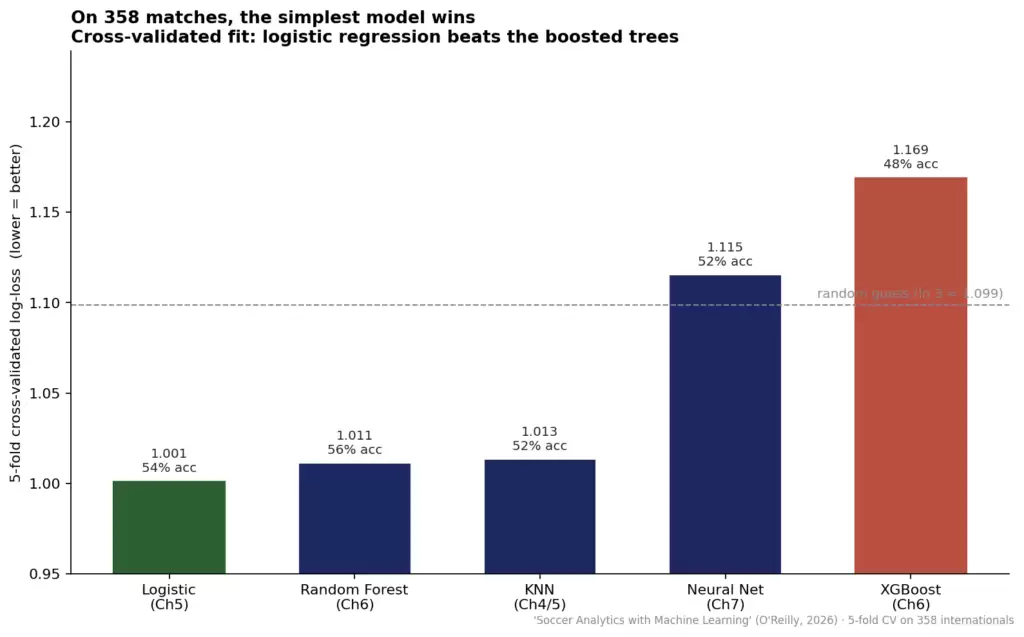
| 模型 | 交叉验证log-loss(越低越好) | 交叉验证准确率 |
|---|---|---|
| 逻辑回归 | 1.001 | 54% |
| 随机森林 | 1.011 | 56% |
| K近邻 | 1.013 | 53% |
| 神经网络 | 1.115 | 52% |
| 极限梯度提升 | 1.169 | 48% |
这两个事实的根源是相同的,而这正是本文最有价值的地方。
“无聊”的模型为何获胜:偏差与方差
理解这个问题最清晰的角度是偏差-方差分解。模型在样本外的预期误差可以被拆解为三个部分:
误差 = 偏差² + 方差 + 不可约噪声
- 偏差:由错误的假设导致的误差——模型过于僵化,无法捕捉数据中的真实结构。
- 方差:由模型对特定训练样本的敏感性导致的误差——模型过于灵活,会拟合那些在下次采样时不会重现的噪声。
- 不可约噪声:是预测目标本身携带的、不可消除的随机性。在足球比赛中,这个噪声量级巨大:一次错误的射门就可能改变整场淘汰赛的结果。任何模型都无法撼动这个部分,这也是为什么即使是最好的分类器,在这个任务中的准确率也只在50%附近徘徊。
整个模型选择的游戏,就是在前两项之间做权衡。高容量模型(如提升树或神经网络)通过足够的灵活性来拟合数据中的任何形态,从而换得较低的偏差。但这种灵活性的代价是方差,而只有当数据量不足以牢牢锁定模型时,这个代价才会显现出来。
而我们现在的情况正是如此:358个样本,分布在三个目标类别上,平均每类只有大约120个匹配。与此同时,一个极限梯度提升集成模型,其数千个有效参数分布在各个树上。信号根本不足以约束它们,所以它们会贪婪地抓住那些恰好出现在某个交叉验证折中、却在下一折中消失的细节。这就是教科书级的过拟合,它解释了第一个令人不安的结果:交叉验证正在尽职尽责地工作,它抓住了这些灵活模型在未见数据上的“狐狸尾巴”。
那么,为什么极限梯度提升会掉到随机水平以下,而不仅仅是在中游徘徊呢?这正是log-loss指标的妙处所在。它对单个样本的惩罚是 -ln(p_true_class),并且这个函数的凸性极其强烈。预测最终结果时,如果你给一个50%的“谨慎”概率,你付出的代价是 -ln(0.5) = 0.69。但如果你自信满满地给出10%的概率,而这个预测却错了,那么你付出的代价是 -ln(0.1) = 2.30——是前者的三倍多。一个过于灵活的模型在小数据上,不仅仅会犯错,它还会“充满信心”地犯错,给出60%-70%的尖锐概率,并且频繁出错。这种凸性惩罚会将其平均分拖到那个“谨慎”的1/3基准线以下。
这种失败的学名叫作“自信的错误校准”,它是模型容量远超数据容量的典型症状。极限梯度提升偶尔因大胆预测而获得的准确率红利,完全无法抵消它因过度自信而在其他地方造成的巨大亏损。
为什么逻辑回归恰恰合适
知道灵活模型会“吃瘪”只是故事的一半。线性模型不只是避开了陷阱,对于这个问题来说,它根本就是正确的工具。两个结构性原因证明了这一点:
- 真实关系在log-odds尺度上接近线性。预测结果的最主要因素是“双方实力差距有多大”,而获胜概率会随着实力差距的增大而平滑且单调地增长——这正是逻辑回归所假设的函数形式。当模型的归纳偏置与数据生成过程一致时,你只需要更少的数据就能很好地拟合它。相比之下,树模型需要用分段常数的方式去“发现”那条平滑曲线,它们浪费宝贵的数据来逼近逻辑回归能免费获得的东西。
- 特征少,交互弱。树和神经网络的优势在于捕捉大量特征之间的交互作用。但在这个问题里,只有三个特征,而且它们之间几乎没有交互。那么这些复杂模型的“特长”就毫无用武之地——它们只会增加方差,却拿不出任何信号上的回报。
经典统计学中有一条值得牢记的经验法则:稳定估计参数,大约需要每个参数对应10到20个观测样本。逻辑回归只用几个系数来建模358场比赛——完全在预算范围内。而一个提升集成模型,其参数数量则超出这个预算好几个数量级。这个不匹配,在第一个模型开始训练之前就已经注定了结局。
如何诚实看待这张成绩单
在从这张表格中得出结论之前,有两个需要注意的地方——因为同样是这个小数据集,它让极限梯度提升跌落神坛,但同时也让表中的数字比看上去更不稳定。
第一是指标本身的方差。358场比赛,五折交叉验证,每折只保留了大约72场比赛,所以交叉验证得到的分数本身就会上下波动。逻辑回归、随机森林和K近邻之间的差距——1.001对1.011对1.013——完全在这个波动范围内。它们的表现其实是难分伯仲的。
真正稳健且可重复的是表格的两端:简单的线性模型稳定地坐在最上面,而最灵活的模型稳定地垫底。看领奖台,别纠结于“冲线瞬间”。
第二是准确率这一列,你应该完全抵制住过度解读它的冲动。三结果制的足球预测本身就非常困难,因为平局是一个真实存在的、且几乎没有强预测因子的结果。历史上,大约27%的这类比赛会打平,而且单靠球队实力几乎不可能提前判断出平局。一个知道每支球队真实获胜概率的模型,其准确率也很难被推高到超过五成以上。因为不可约噪声实在太大了。从这个角度看,逻辑回归54%的准确率一点也不平庸——它几乎已经是这套特征组合能达到的实用天花板了。模型之间的真正差异从来不在于它们猜对头名的频率,而在于它们的校准度——这正是log-loss能够精确衡量,而准确率所掩盖的东西。所以,用更合理的评分规则来主导评估,把准确率当作一个直觉上的参考检查。
树模型能被拯救吗?可以,但需要约束。
所有这些都不是对极限梯度提升的否定。它说的是一个关于“配置与数据规模”的故事。同样的算法,如果用不同的方式处理,可以把差距缩小很多。关键在于正则化:用一点点偏差换回一些方差。
- 对于极限梯度提升:使用更浅的树(max_depth=2-3),设置更强的min_child_weight,采用低于1的subsample和colsample_bytree,加上L2惩罚项(lambda),设置较低的学习率并配合早停(early stopping)在一个验证集上,并减少迭代轮数。
- 对于逻辑回归:L2惩罚项(C)本身已经在默默地做正则化——这也是它开箱即用就非常稳定的一个原因。
如果我们把正则化调整到极致,一个经过仔细调参的极限梯度提升模型很可能与逻辑回归打个平手。但请注意,这里的核心教训是“经过仔细调参后能与一行代码的模型持平”,而不是说它是个反例。
(另一个方向的注脚是:非常大的、过度参数化的模型可能会进入一个“双重下降”的区间,在越过插值阈值后误差再次下降——但这已经远远超出了358场比赛的数据和参数规模。)
那么,你如何从经验上判断,什么时候树模型才真正值得投入呢?画一条学习曲线:对每个模型,绘制其在留出集上的log-loss随训练集大小变化的曲线。
有两个诊断性的模式。一个高偏差模型(比如逻辑回归)会早早地进入平台期——更多的数据几乎帮不上什么忙,因为偏差地板已经压住了它。一个高方差模型(比如极限梯度提升)开始时表现可能更差,但会随着数据的增长而持续改善——因为更多的样本正是驯服其方差的关键。两条曲线交叉的点,就是灵活模型开始获胜的“数据预算”阈值。
在358场国际比赛的规模上,我们显然位于那个交叉点的左侧。如果给这个极限梯度提升模型投喂数以万计、特征更丰富的俱乐部比赛数据——比如预期进球、休息天数、阵容名单——那么它很可能会反超逻辑回归。同样的算法,不同的数据规模,相反的结论。这种“条件性”才是这个问题的精髓。
核心结论:根据你的数据选择模型
模型的复杂度应该与数据相匹配,而不是与追逐的热门相匹配。在面对那些大规模、杂乱、高维特征的问题时,梯度提升和深度学习模型确实常常占据主导——这也是它们名声在外的原因,也是默认选择它们的“本能”通常是正确的。
但是,在像本问题这样的小规模、干净、低维问题上,这种“本能”就是错的。正确的纪律是:从简单模型开始,建立一个坚实的基线,用合理的评分规则来衡量,并且只在留出数据证明它确实值得时,才增加复杂度。逻辑回归在这个案例中,不是安慰奖。鉴于手头的数据,它就是正确答案。
这种“先简单、用log-loss和校准度诚实验证、有节制地扩大复杂度”的纪律,贯穿于《用机器学习做足球分析》(O'Reilly, 2026年出版)一书的建模章节中:逻辑回归和分类在第5章,树模型(包括极限梯度提升)以及它们何时真正值得使用在第6章。
所以,下次你在新项目里伸手去拿那个最强大的模型之前,先问自己两个问题:你手头到底有多少数据?以及,你如何知道复杂模型到底有没有帮上忙?有时候,那条最佳拟合线,也就是终点线本身。