大模型的上下文腐烂(context rot)——这个术语听起来很专业,但本质很简单:随着输入文本长度增加,模型的理解与推理能力不升反降。
提供给大模型的信息越多,它反而愈发混乱,而非变得更聪明。如同食物逐渐腐败,这种衰退是渐进式的——随输入序列长度的增长,模型的性能逐步恶化。
典型症状包括:遗忘核心指令、在中段内容中迷失方向、选择性忽略关键信息、逻辑断裂、前后矛盾、幻觉大幅增加、陷入重复循环、以及风格与人格偏移。

举个例子来说明。假设你向大模型一次性输入一份长达20万字的商业报告,并在提示语的起始位置明确要求:“请以表格形式输出总结,并务必提取报告中提到的财务造假证据。”
结果如何?大模型输出了一大段普通的纯文本。表格格式?完全被忽略。它准确提炼了报告开头的背景和结尾的结论,但对隐藏在数十万字中间部分的财务造假证据却视而不见。更糟糕的是,它甚至依据行业惯例编造了一个无关的常规风险来敷衍用户。
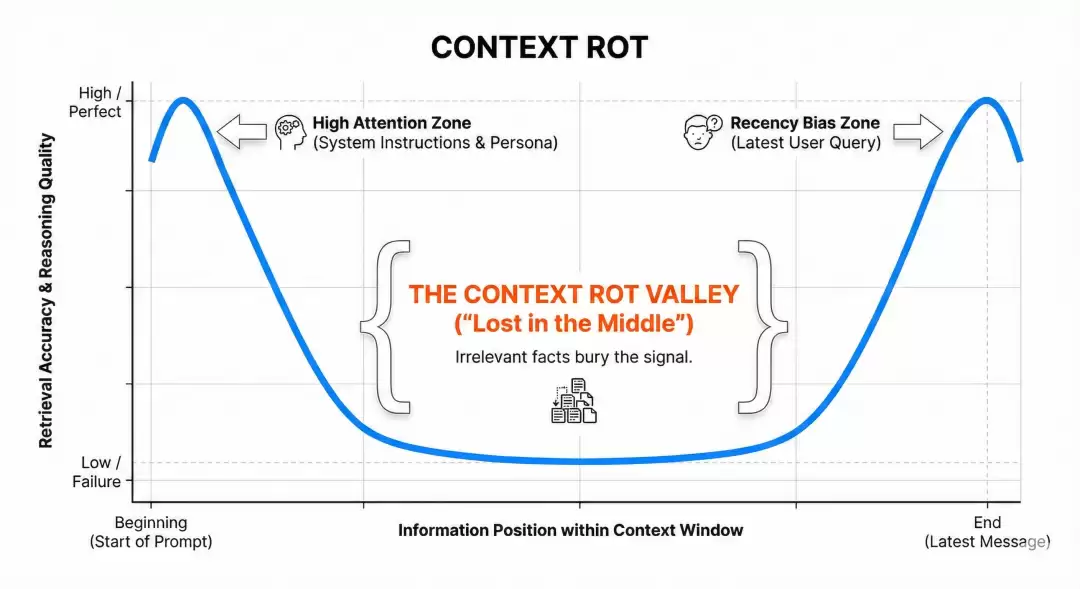
从这张示意图可以清晰看到:在单次输入中,大模型对不同位置信息的处理能力呈现明显的U型曲线。开头部分质量较高,中间核心区域最差,结尾部分又有所回升。
这一现象的数学根源在于:位置编码的偏置将注意力权重聚集到序列两端,而softmax操作进一步放大了这种差距,模型有限的容量导致中间部分最先被压缩。简而言之,上下文腐烂是Transformer架构与生俱来的缺陷,由其数学形式直接决定。
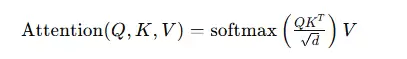
即使将工程优化做到极致,也只能在一定程度上缓解这一问题,彻底根治?几乎不可能。

其深层原因主要有三个,我们逐一分析。
原因1:Attention资源有限
Transformer的注意力机制并非平均分配。序列前部享有结构性的注意力权重,后部获得位置时间性权重,而中间部分却缺乏特殊关注。模型天然认为开头定义了任务目标,结尾指向当前要解决的问题,中间的大段文本则常常被当作背景噪声。
这就像你阅读一份冗长的材料,然后回答相关问题。开头必须仔细阅读以理解规则或背景,结尾也需要认真看以明确问题是什么。人的精力有限,中间部分自然就一扫而过。

原因2:信号被噪声淹没
中间位置通常放置长文档、RAG检索内容或历史对话。问题在于:相关信息并不等同于显著信息。模型无法稳定判别中间部分哪些句子是关键信息,哪些是冗余内容。
想象一下,如果让你在100句话中找出最有用的那一句——你未必能一眼锁定最重要的。模型的问题更为严重:它并非基于理解进行筛选,而是先计算相似度,再决定关注对象。然而,关键语句 ≠ 与问题最相似的语句,有时废话反而更像。因此,模型并非找不到信息,而是无法区分信息的重要性。

原因3:压缩和总结机制带来的信息损失
长上下文会被大模型隐式压缩,其中中间部分最容易被模糊化。这好比让一个人记住100页的内容然后回答问题——他不可能逐字记忆,一定会进行总结、抽象并忽略细节,尤其是中间部分。
大模型也是如此。长上下文输入后,本质上会被转化为一个低维压缩表示。在这一过程中,细节被丢弃,相似内容混合在一起,中间部分最容易被平均化,最终压缩成一团难以区分的信息。




