继 Seedance、Seedream 等模型之后,字节跳动 Seed 团队此次将技术重心转向音频领域——正式发布的 Seed Audio 1.0,已不再是单纯的“语音生成”工具。它能够将语音、对白、背景音乐、环境音和音效融合至同一音轨,一次性输出完整的音频内容。对于视频创作者、游戏开发者和内容团队而言,这无疑是一套更全面的 AI 音频解决方案。
什么是 Seed Audio 1.0?
简而言之,Seed Audio 1.0 是字节跳动推出的新一代多模态 AI 音频模型,但它与传统 Text-to-Speech(TTS)截然不同。TTS 仅负责“将文字朗读出来”,而 Seed Audio 能够理解整个场景——根据用户输入的提示词,它可以直接生成:
- 自然的人声对白
- 环境声音(Environment)
- 背景音乐(BGM)
- 各类音效(SFX)
最终输出的是完整的音频片段,而非多个零散素材需要后期手动混音。
Seed Audio 1.0 的主要特点
1. 一次生成完整声音场景
传统流程是怎样的?先使用 TTS 生成语音,再前往素材库寻找音乐和音效,最后在 Premiere 或 Audition 中手动对轨、混音。而 Seed Audio 一次即可完成:用户只需输入一段描述,例如“一位老人站在海边,缓慢讲述自己的童年,远处传来海浪,背景播放轻柔钢琴。” 模型直接输出完整音频,省去了中间所有繁琐步骤。
2. 支持参考音频(Reference Audio)
除文字提示词外,Seed Audio 还允许用户上传参考素材。例如上传一段说话人的声音、一段背景音乐或一段环境音,模型会学习这些参考的风格,并基于此进行新的生成。这意味着用户可以在已有风格基础上进行定制,灵活性极高。
3. 更自然的情绪表达
传统 TTS 念出的“Hello”往往平淡无起伏,而 Seed Audio 更加注重情绪——开心、悲伤、紧张、激动、恐惧、平静……均能在语音中体现出来。生成的对白更接近真人配音的语气和表情,听起来不再像机器人。
4. 多语言能力
依托 Seed Speech 系列的技术积累,Seed Audio 支持多语言语音生成,并且在跨语言场景下也能保持自然的语音表现。
Seed Audio 能做什么?
官方定位了几类典型场景:
视频配音
例如输入提示词:“Generate a documentary narration with calm male voice, ocean ambience, cinematic background music.” 模型直接生成完整的纪录片旁白。适合 YouTube、TikTok、短视频、宣传片、广告制作等——一次完成产品介绍、转场音效、背景音乐,大幅减少后期制作时间。
AI Podcast
提示词如:“Two people discussing AI, coffee shop ambience, soft jazz background.” 生成结果包含两人对话、咖啡店环境音、轻柔爵士背景音乐,完全无需另外寻找素材。
与传统 TTS 有什么区别?
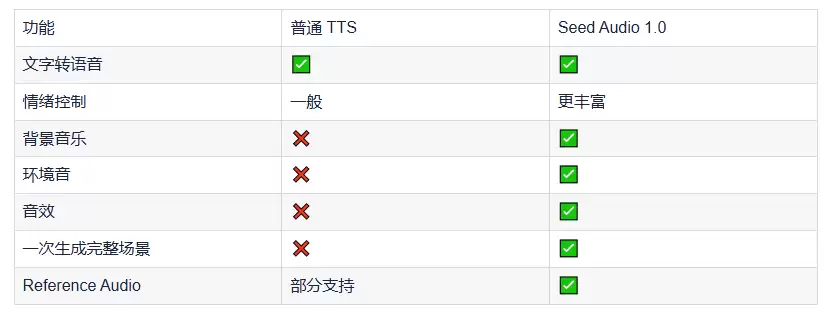
与 Seed Music 的区别
很多人容易混淆 Seed Music 和 Seed Audio,但两者定位完全不同。
- Seed Music 主要关注 AI 作曲、歌曲生成、风格迁移、歌声转换、音乐编辑,本质上是音乐创作工具。
- Seed Audio 则更侧重于语音、音效、环境声音、音乐——全场景声音生成。可以理解为:Seed Music 偏向“写歌”,而 Seed Audio 偏向“制作完整的声音内容”。
总结
Seed Audio 1.0 的目标并非取代传统 TTS,而是将语音、背景音乐、环境音和音效整合到统一的生成流程中。创作者只需编写一个提示词,即可完成整个声音场景的构建。对于视频创作、播客、有声书、广告、游戏等需要丰富音频设计的场景,它比传统的“TTS + 配乐 + 音效”分步工作流高效得多,也更符合未来多模态内容生成的发展方向。




