数据库管理第347期:OCI的崛起,远不止软件层面(20240709)
 胖头鱼的鱼缸4_01.png
胖头鱼的鱼缸4_01.png
先给出一个核心判断:一个优秀的云平台,绝不仅仅是软件层面的简单叠加,硬件底座同样至关重要。提到Oracle的硬件,许多人第一时间想到的是当年收购SUN的事件,再近一些,大概就是数据库一体机Exadata和ODA。而在Oracle云(OCI)中,Exadata同样扮演着硬件底盘的重要角色,为云端提供强大的数据库服务,甚至通过多云合作将相同的数据库能力迁移到其他公有云上。结合Oracle Database 23ai的融合数据库与AI向量搜索能力,这为AI应用注入了一股强劲的数据处理动力。
SuperCluster:从传统大型机到AI算力集群
不过今天更值得一提的远不止Exadata。AI时代除了数据处理能力,算力才是真正的稀缺资源——尤其是GPU。Oracle早年曾有一套名为SuperCluster的大型机硬件架构,这在大规模部署中确实不多见。随着X86 CPU的崛起,Oracle逐步放弃了SPARC路线,SuperCluster也逐渐淡出主流视野。但有趣的是,随着OCI战略重心转向AI,SuperCluster以全新的身份强势回归:AI算力集群。
 image.png
image.png
SuperCluster的核心能力
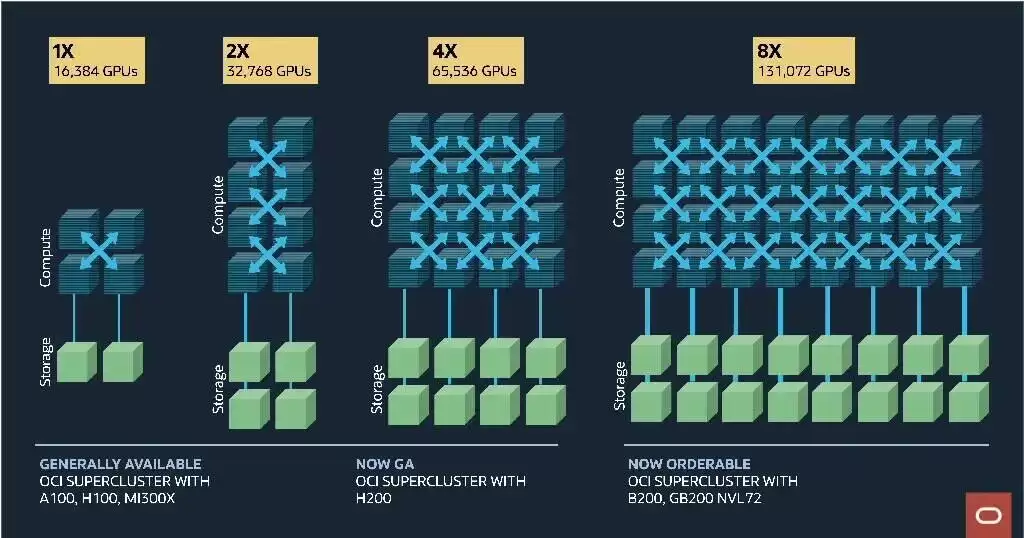
那么OCI上重生的SuperCluster究竟带来了哪些能力?简单列举几个关键数字:
- 最多可支持131072颗Nvidia BlackWell GPU(B200),峰值性能高达2.4 zettaflops
- 集群网络以每端口400Gbps的速度,提供52Pbps的非阻塞网络带宽
- 集群网络延迟低至2µs
网络性能:高速、低延迟、高可靠
 Medium.jpg
Medium.jpg
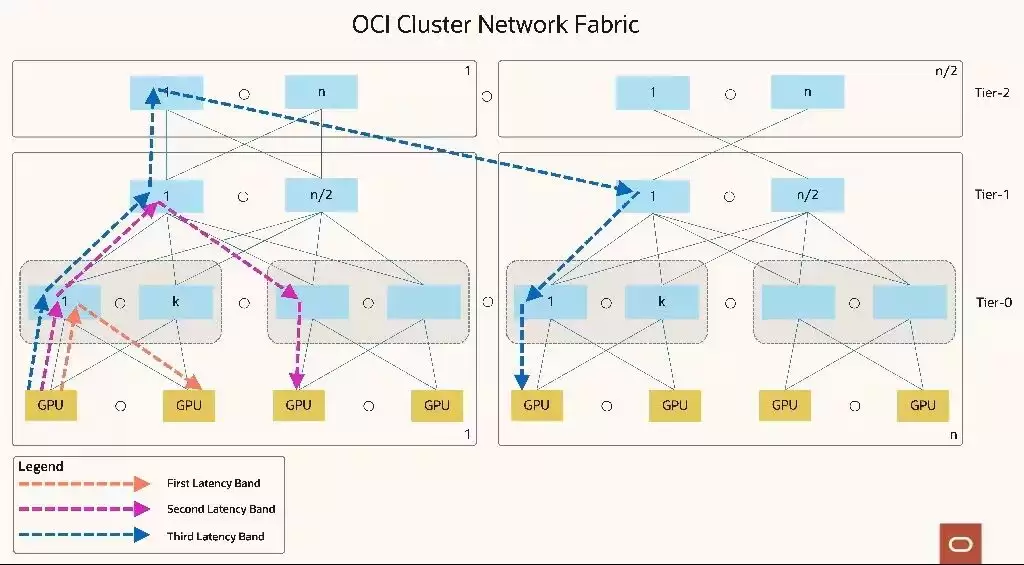
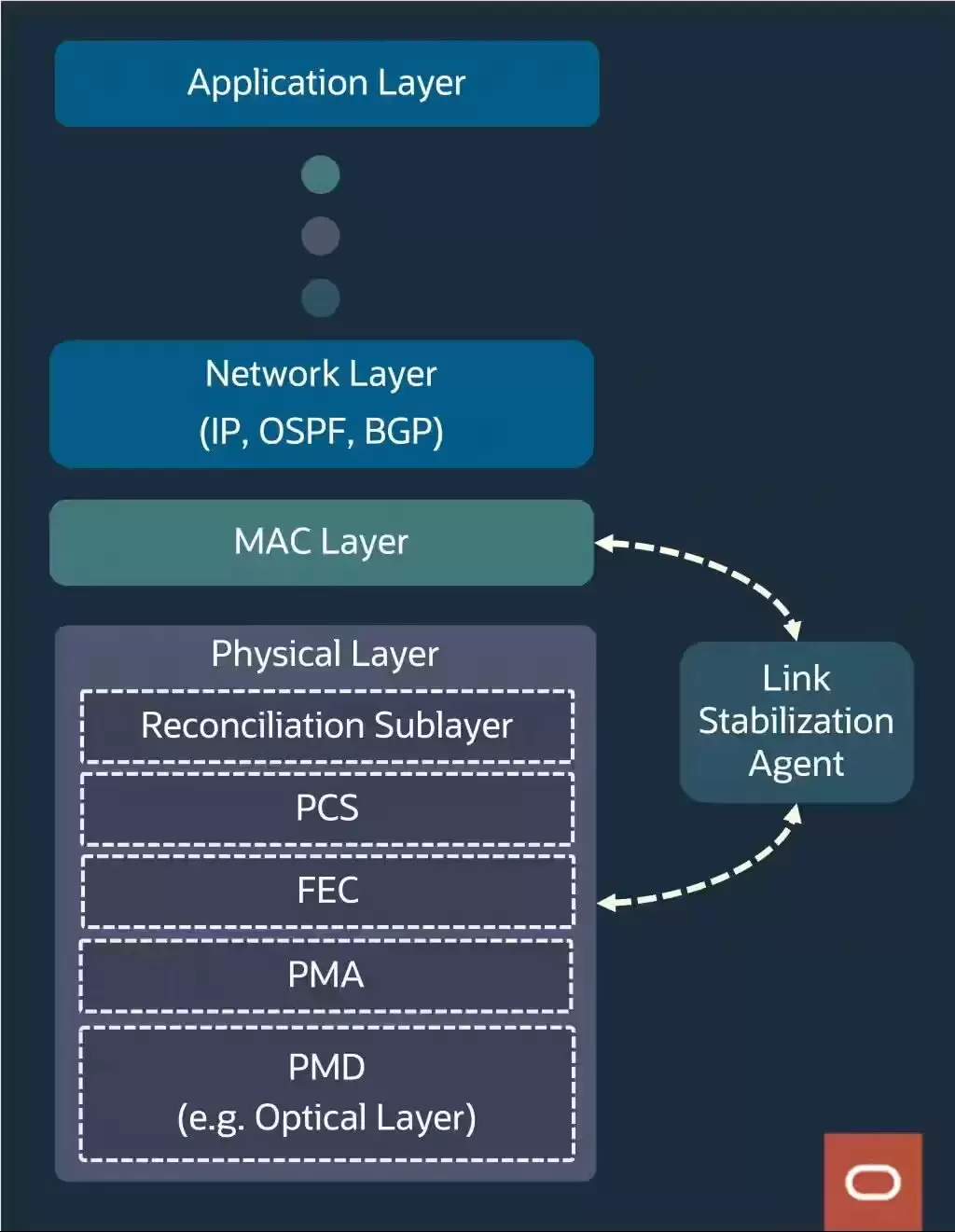
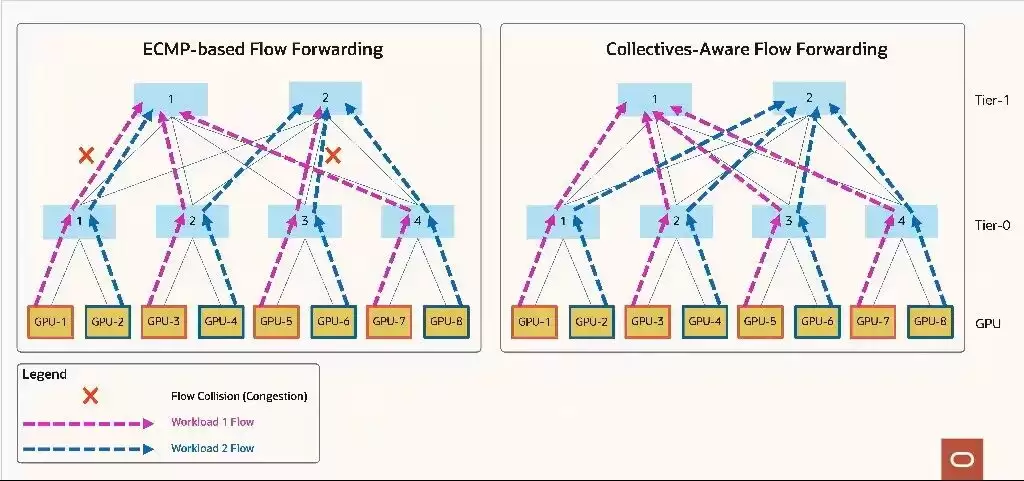
网络层面是整体性能的关键。通过RDMA(基于RoCE)技术,实现了极高的吞吐量、极低的延迟,并结合高级链路弹性保障工作负载的可靠性,以及高级流量负载平衡。简单来说,数据在节点之间传输速度极快且运行稳定。
 Medium 1.jpg
Medium 1.jpg
 Medium.jpg
Medium.jpg
 Medium 2.jpg
Medium 2.jpg
存储:高吞吐、低延迟、持续升级
再来看存储方面。通过OCI文件存储(OCI File Storage)以及新推出的高性能装载目标(HPMT)功能,在单个文件系统内可实现每秒TB级别的吞吐量。此外,即将推出的完全托管型Lustre文件服务,单秒吞吐量可飙升至数十TB。为了匹配日益增长的存储吞吐需求,OCI GPU计算前端网络容量也在持续升级:从H100的100Gbps,到H200的200Gbps,再到B200和GB200实例的400Gbps(每个NVL72机架总容量达到7200Gbps)。一步一个脚印,确保不留下任何短板。
总结:双引擎驱动,OCI的AI之路值得关注
总体来看,通过从网络到存储再到计算的全面硬件整合,OCI确实为AI应用打造了一个高算力、高吞吐、低延迟、高IO且稳定智能的GPU算力集群。再配合Oracle Database 23ai Exadata提供的融合数据库能力,在AI这条赛道上真正实现了双引擎驱动。未来值得持续关注。




