上周,豆包正式进入收费模式。推出的专业版有三档价格,最高级的套餐年费直接标到了5088元。
紧接着,一向以“价格屠夫”形象出圈的DeepSeek,也宣布更换计价方式。实行新的峰谷定价后,每天上午9点到12点、下午2点到6点算高峰时段,调用成本直接翻倍。

图源:DeepSeek开放平台
所有看似免费的午餐,其实都在暗中标好了价格。ChatGPT今年2月就开始在免费用户的对话框里塞广告,前几天还跑到法国大举招商,广告推送的密度明显增加。
白嫖AI的时代,看来真的要结束了。去年这会儿,各家还在打价格战,现在大家想的是同一个问题:怎么让AI这门生意,不再是一个只进不出的无底洞?
1、商业化落地两头堵
一家AI公司想赚钱,无非两条路:要么多收钱,要么少花钱。但现在,两头都堵上了。
过去几年,大家的思路很统一:先把用户规模冲上去。互联网那套打法太深入人心了——前期疯狂烧钱拉用户,亏钱不要紧,等规模大了,成本自然摊薄。但互联网的边际成本几乎是零,多一个用户访问,服务器成本几乎不涨。
但AI产品的逻辑,更接近制造业。用户规模冲上去,算力成本也跟着冲上去。AI的成本是刚性的——多一个用户问一句话,模型就得实打实跑一次推理,烧一次算力。用户越多,对话越多,烧得就越多。
月活用户9亿的OpenAI,去年净亏损385亿美元。到了今年第一季度,情况也没见好转——每收入1美元,就要赔1.22美元。豆包这边,日均token调用量已经达到180万亿,但日收入却不足100万元。
在ChatGPT询问“如何学习AI”的回答底部出现了广告
另一方面,算力供给本身就是稀缺资源,这让算力价格一直居高不下,总成本根本降不下来。
现在来看,算力供给的约束是一道很硬的物理墙,没那么容易突破。先说电——Gartner预测,2030年全球数据中心用电量将超过1200TWh,届时电网供电将无法满足需求。再说芯片——全球高阶AI芯片的先进封装几乎全靠台积电,但台积电的产能扩得再快,英伟达一家就能吃掉六成以上,剩下那四成还要被几十家公司抢,有钱也排不到号。
更麻烦的是,AI形态正在从一问一答的Chatbot,转向需要持续运行的Agent。Agent要将人类给的几行任务,转化成后台成百上千次的自我推理、工具调用与记忆吞吐——这个转变对算力的需求是数量级的跃升。
算力成本正面临双重夹击:调用量涨多少,成本就跟着涨多少,规模无法摊薄成本;供给又还无法满足持续攀升的需求,成本降不下来。
那就涨价,多收钱不就行了吗?
在To B的生产力场景,提价没问题。客户买的是解决复杂专业问题的能力,智能上限和真实能力是第一约束,企业能接受为此付出高成本。Anthropic的ARR暴涨、智谱的股价上天、workbuddy的广受好评,都说明了这一点。
但在ToC场景里,情况完全不同。2025年ChatGPT的9亿周活跃用户中,个人订阅用户约5000万,占比仅约5%。
国内的付费意愿更低。在“免费+广告”的互联网模式长期浸泡下,国内用户没有养成为独立软件付费的习惯。5月初豆包试水订阅时,“豆包 笨还收费”直接冲上了热搜。
说白了,现在普通用户对ToC的AI产品没有忠诚度,谁用起来方便顺手就用谁。别说提价了,就算从免费到付费,都能赶跑一堆人。
那留给企业的路其实只有一条:在AI完成同等任务时,能不能消耗更少的算力资源?
这就是整个行业正在干的事情:效率优先。
2、让每一分算力都花得值
从里到外,现在行业每一层都在沿着效率思路做事。
在最底下的硬件层,连英伟达都觉得光靠GPU不够了。今年英伟达在GTC大会上推出了一种叫LPU的新芯片,基于它去年获得技术授权的Groq打造,专门优化AI推理场景。
怎么理解?GPU擅长高并发的大规模计算,像一支万人方阵一起冲锋,现在更多是用在大模型的预训练上,去提高智能上限。LPU像一个精锐小队,擅长快速出击完成任务。日常面向普通用户的推理场景,其实不需要千军万马同时出击——响应快、又省钱,才是性价比最高的方案。
芯片之上是模型架构。MoE(混合专家架构)这两年成了主流。它的妙处在于:模型的总参数可以堆到万亿级别,保证脑容量够大,但每次干活只激活其中一小撮参数,做到又强又省。这就像一家公司接到任务后,按需调用,从全体人员中挑出最合适这个任务的那几个专家去干活。
把激活率压低难,更难的是要选对“专家”——不然该激活的没激活,答案质量就崩了。比如,DeepSeek V4 Pro总参数1.6万亿,每次只激活490亿,相当于只动用了3%的精锐员工。结果呢?编码能力逼近顶级闭源模型,输出价格只有GPT-5.5的八分之一。
腾讯前段时间开源的hy3 preview也是这个路数。295B参数,激活仅21B——能力接近300B级模型,成本却是20B级别。上了OpenRouter之后开发者涌进来用,除了免费,也是因为在这个体量下性价比确实能打。
这个方向显然走通了。最近腾讯灰度内测的AI助手“小微”,用的也是同样的思路。小微背后的模型叫WeLM,总参数800亿,但每次只激活30亿,激活率低到3.75%,比目前国内极致成本性能的代表DeepSeek-V4-Flash(激活率4.6%)还要低。
为什么要把激活率压这么低?微信月活14亿的体量,一旦“小微”全量开放,每天的推理量是天文数字。模型性价比不够高的话,光电费就能把利润吃干净。所以小微绝大多数日常请求交给又快又便宜的WeLM,碰上真正的硬骨头也有合作模型兜底。
在模型运行过程中,还能靠工程巧劲再榨一轮算力。比如DeepSeek等都在用的一招叫KV缓存复用——你跟AI反复聊同一个话题,系统提示词、常用前缀这些重复内容,不需要每次都从头算,直接调上次的计算结果就行。就像你通勤次数多了,熟悉路线后就不用每次都重新导航。
除了工程手段,DeepSeek还给出一个新招:用价格杠杆来优化算力调度。在DeepSeek新的计价方式下,平峰时段价格不变,缓存命中依然压到接近免费。这等于用价格信号把一部分负载从白天引导到夜间低谷期,让原本闲置的算力被利用起来。同一批GPU,24小时整体利用率更高,单位成本自然就降低了。
前面说到,到了Agent时代,算力的问题更棘手。Agent干活时,大量token其实花在了重复搬运信息上,而不是真正生产新东西。多个Agent协作时更夸张——它们聚在一起就像开低效会议一样,反复确认已经讨论过的背景。任务越长程,空转越严重。
谷歌的A2A协议和Anthropic的MCP协议,就是冲着解决这个问题来的。简单说:MCP能让单个Agent内部复用上下文,不用每次从头来过;A2A让多个Agent之间共享已有成果,避免重复劳动。一个管内耗,一个管重复,配合起来减少Agent协作时的无效推理。
效率优先不只是企业的一厢情愿,用户的需求本身也在分化。
有一个衡量市场AI付费意愿的指标叫“LLM Token支出指数”,最近持续走低。指标回落的背后,是用户在加速离开那些昂贵的、参数巨大的前沿模型,转头涌向性价比高、专门优化过的轻量级和MoE模型。
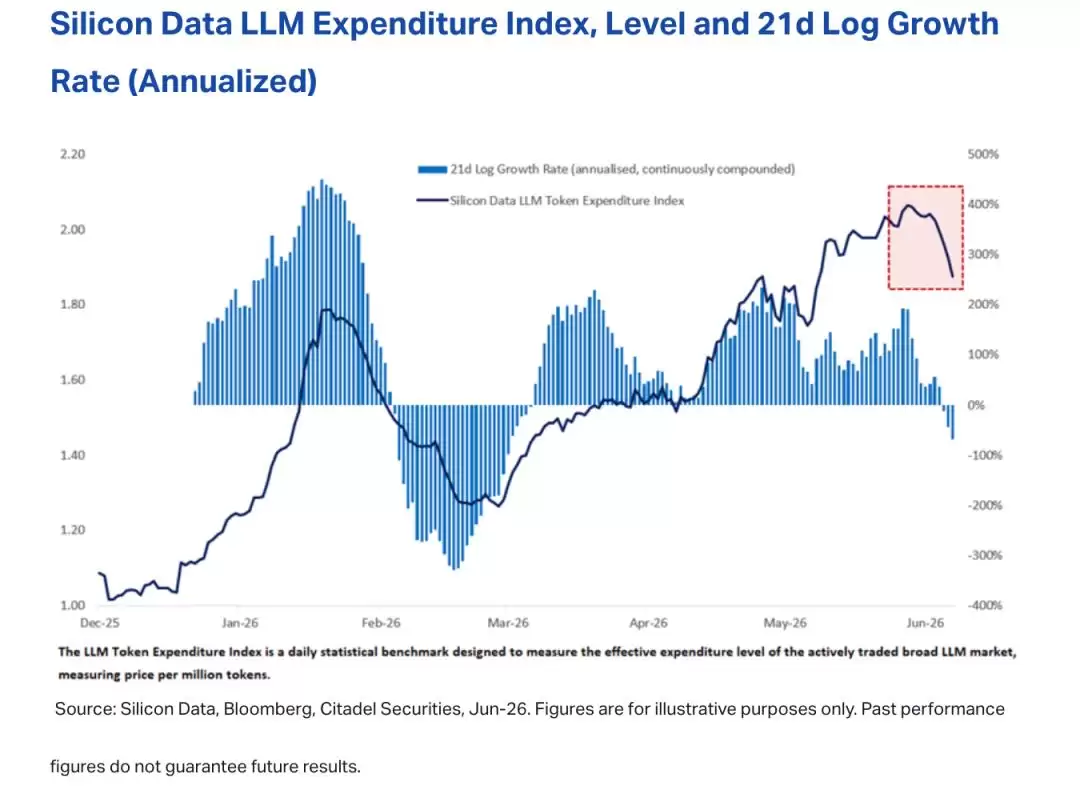
图源:Citadel Securities的报告《Tokennomics》
针对这些现象,最近Citadel Securities给出的判断一针见血:前沿人工智能和“日常”人工智能的使用,正在出现分化的迹象。换句话说,前沿AI追求的是智能上限,日常AI追求的是极致效率,已经不能用同一把尺子来比较两种AI路线了。
这倒不是说前沿模型不重要了。头部大模型依然会不断追求智能上限,这部分的需求也还在。但大家已经意识到,只有少数专业或复杂的场景值得调用昂贵的AI模型,大多数场景下其实可以主动降级到性价比更高的模型。
一家公司不会让首席分析师去接前台电话——模型使用也是一样,大炮打蚊子只会浪费资源。
而效率优先做成了,企业和用户两头都能受益。企业这头,单次推理成本压下来,利润就能看得见。另一边,成本降下来后,还能反过来打开降价空间。价格一降,原本被价格挡在门外的用户进来了,付费规模才能健康地往上走,形成正向循环。
3、做人人可用的AI
这段时间,除了To C端AI产品涨价,巨头们也在缩减内部员工的token使用量。
微软已经开始取消内部的Claude Code许可,让员工转向自家内部更便宜的Copilot CLI。亚马逊明确要求员工不要为了用AI而用AI,Meta也撤下了内部的token消耗排行榜。
结果就是,大家被逼着去学习如何最大化利用token。一个懂行的工程师,确实能把AI的账单压得很低——他知道怎么精简提示词、控制上下文长度、避免让模型反复读同一份资料。对他来说,这些都是顺手的事。
近期社区上有关节省token的技术帖子
但有多少普通用户能读懂这些省token的技术帖子,又能每次有意识地控制token使用?他们更可能是一直在为远超实际需要的算力买单,自己也不知道如何解决。
这个落差不应该由用户来填。怎么更高性价比地使用AI,应该从用户身上挪到机制层面。理想的情况是,用户不需要知道背后有几种模型在跑——系统能判断这个简单任务交给便宜的小模型,那个任务复杂才调用贵的模型。就像你用搜索引擎不需要知道后面有多少台服务器在响应你一样。
只有这样,更多像你我一样用AI的普通人,才能真正从这项新技术中受益。
说到底,技术的价值,从来不在于它能做到多极致,而在于它能触达多少人。如果AI能力不能为人人所用,它就只是一场精英的狂欢。
就像电力没有走进每一个家庭之前,它只是工厂的特权;互联网铺到每一个县城之前,信息鸿沟照样横亘在那里。AI也是一样——效率优先不只是一个商业命题,它更是一个技术平权的问题。
从少数人的工具变成所有人的基础设施,这是每一次技术革命的关键时刻。而AI的普及,不取决于最强的模型理论上能做什么,而取决于大规模跑AI的成本能压到多低。现在,AI正站在这个时刻的门口,效率优先就是推开这扇门的那双手。




