最近,随着Palantir将Ontology(本体论)这一概念带入公众视野,用友也迅速推出了自有的ontology-driven agent(基于本体的智能体),一时间让人们误以为Ontology是什么前沿的AI黑科技。然而,如果我们拉长时间线,就会发现一个截然不同的故事。
实际上,Ontology是一个早在2002年就被提出、2004年正式标准化的互联网时代“老古董”。2005年,美国中央情报局(CIA)为情报系统开展大数据分析,找到了Palantir。于是,刚刚完成标准化的Ontology,作为当时的前沿技术,被Palantir部署在底层数据核心中。
一、Ontology:上一次互联网泡沫时代的产物
二十多年前,互联网蓬勃发展,大量结构化数据被产生——但这些数据几乎都被各个系统私有化地使用。每个系统都能解释自己的数据,却无法让其他系统真正理解它们。即使两个系统都使用了“customer”这个词,机器也无法判断它们指的是同一类对象,还是纯粹名称上的巧合。这种问题在跨机构数据共享、科研协作和政府信息系统中被不断放大。系统需要一种方式来判断概念定义是否冲突、数据使用是否违反了原本的语义假设——语义不仅要被描述,还要能被机器验证。
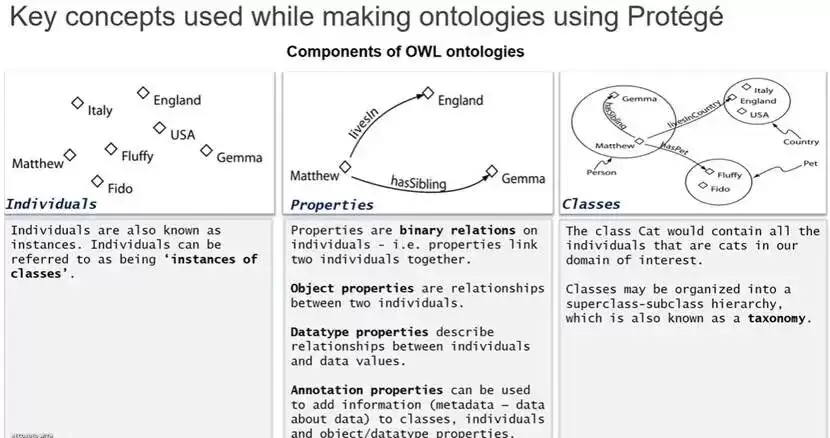
正是在这样的背景下,2002年,World Wide Web Consortium(W3C)在语义网络(Semantic Web)领域推出了Web Ontology Language(OWL)。它的设计目标非常清晰:用一套形式化、可计算的语言,将“什么是一个概念”定义清楚,并保证这些定义在逻辑上是自洽的。class、entity、properties等元素构成了OWL的核心表达能力,而描述逻辑则为其提供了严谨的理论基础。
 图形用户界面, 文本, 应用程序AI 生成的内容可能不正确。
图形用户界面, 文本, 应用程序AI 生成的内容可能不正确。
二、Ontology不玄乎,人人可构建
即使回到20年前,Ontology也不是只有少数人才能触及的东西。以Stanford推出的本体建模工具Protégé为例,它曾是当时最流行、至今仍免费可用的Ontology在线编辑器(https://protege.stanford.edu/)。
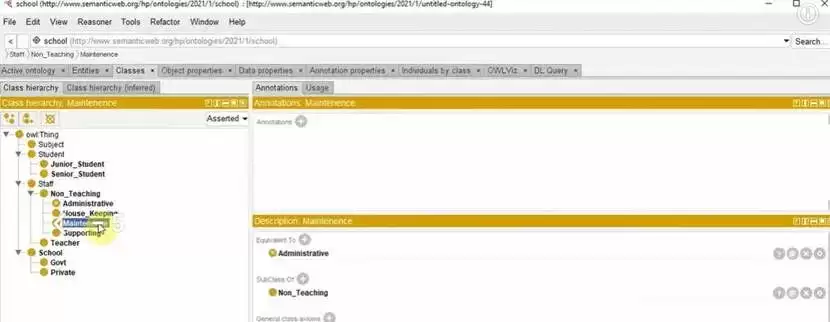
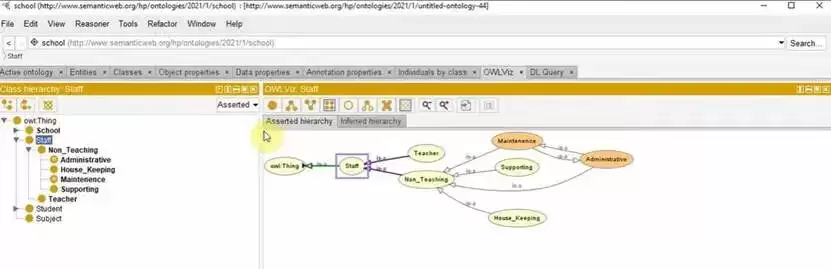
在Protégé中,构建Ontology的过程高度结构化。建模者需要先梳理领域概念,再将这些概念抽象为类,明确它们之间的继承关系和属性约束。随后,建模者会运行推理器,对整个模型进行一致性检查,确保不存在自相矛盾或不可满足的定义。
 图形用户界面, 文本AI 生成的内容可能不正确。
图形用户界面, 文本AI 生成的内容可能不正确。
在工具中,只需手动一个个创建instance,再将instances通过properties连接,再通过class组合,就能建立起一个完整的Ontology。
 图形用户界面, 应用程序AI 生成的内容可能不正确。
图形用户界面, 应用程序AI 生成的内容可能不正确。
 文本AI 生成的内容可能不正确。
文本AI 生成的内容可能不正确。
整个过程更像是在完成一项“语义工程”,而非搭建一个系统。建模完成后,Ontology本身往往以文件或模型的形式存在,很少直接参与到业务系统的运行过程中。它的价值更多体现在定义是否严谨,而非使用是否频繁。
三、OWL Ontology过去真正落地的场景
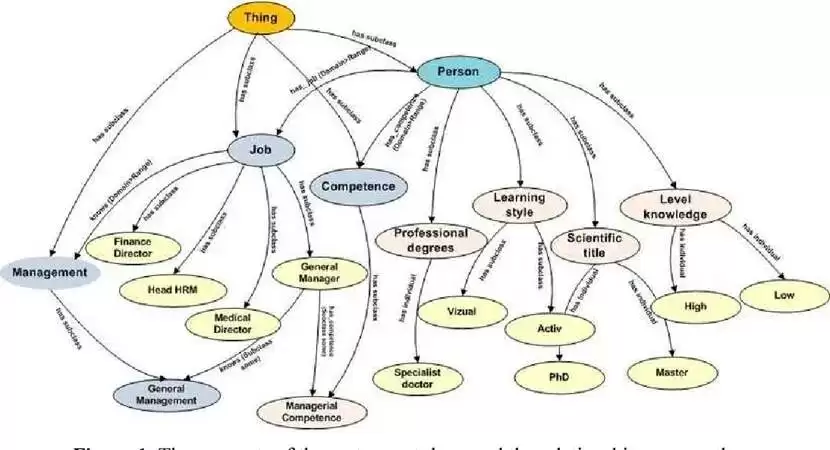
从实际应用来看,OWL Ontology并没有在企业业务系统中大规模铺开,但在一些特定领域取得了长期且稳定的应用效果。生物医药、医疗术语、科研数据管理和图书情报系统,是最典型的例子。
2005年,CIA作为第一大客户,正是因情报系统的大数据分析需求而找上了Palantir。因此,Palantir选用当时最新的技术标准Ontology作为产品的底层数据核心,也算是顺理成章。
 图示AI 生成的内容可能不正确。
图示AI 生成的内容可能不正确。
这些领域有一个显著的共同点:概念相对稳定,变化周期长,且参与方对概念一致性的要求极高。在这样的场景下,Ontology的作用不是驱动流程,而是作为共识载体,确保不同系统、不同机构在讨论同一对象时,至少在语义层面不会出现偏差。
也正因如此,OWL Ontology很少被用来描述企业日常运营中的对象和关系。企业关心的是订单状态如何变化、流程如何推进、系统之间如何联动——而这些问题并不在OWL的设计关注范围之内。
四、Ontology一直在,只是角色变了
早期OWL语境下的Ontology是一套静态的概念模型,其核心职责在于定义对象的类型与语义边界,并通过逻辑约束保证这些定义在形式上是自洽的。它存在于系统设计阶段,很少随着真实业务数据的变化而动态调整,因此也很难进入企业运行体系的核心位置。它在对概念准确性要求极高的领域发挥了长期价值,但并不以支撑业务运行本身为目标。
而Palantir所使用的Ontology则被设计为一个持续存在于系统中的业务对象模型。它同样围绕对象、关系和语义展开,但这些语义不再停留在抽象定义层面,而是与真实数据和业务实例紧密绑定,并随着业务过程不断演进。需要强调的是,将这两个Ontology放在一起直接对比,很容易产生误解——它们用了同一个词,在概念定义方式上也高度相似,但试图解决的问题以及所依赖的技术条件已经发生了根本变化。
从这个角度看,今天重新被频繁讨论的Ontology,并不只是对OWL的重复,而是在大模型、数据湖和实时数据体系成熟之后,对Ontology在企业系统中角色的一次重新定位。当Ontology从一份静态的语义描述,演变为一个与企业长期共存、持续更新的模型,它自然会呈现出与二十年前完全不同的形态。
反过来说,如果企业内只是跟风推动建立Ontology模型,却没有跟上配套的技术能力和体系,那不过是搬出了个20年前的老古董装装样子罢了。




