深入解析PPO与GRPO一轮训练步骤究竟发生了什么
时间:2026-07-02 12:05
前面几篇已经把整张地图铺好了:HybridFlow 解释阶段,Single Controller 负责维持顺序,ResourcePool 和 WorkerGroup 放置角色,DataProto 在角色之间搬运训练“证据”。现在可以把这些层叠起来,回答第一组最后一个问题:一轮 PPO GRPO st
前面几篇已经把整张地图铺好了:HybridFlow 解释阶段,Single Controller 负责维持顺序,ResourcePool 和 WorkerGroup 放置角色,DataProto 在角色之间搬运训练“证据”。现在可以把这些层叠起来,回答第一组最后一个问题:一轮 PPO/GRPO step 到底发生了什么?
核心判断很明确:一轮 step 不是简单的“一次 forward → backward”,而是一笔分阶段交易。它从 prompt batch 出发,经过 rollout 生成、reward 打分、old/ref logprob 与 value 证据补齐、advantage 计算、actor/critic 更新,最后还要把训练权重同步回 rollout 侧。PPO 和 GRPO 的系统外壳几乎一模一样,真正的分叉主要出现在 advantage/baseline 上——PPO/GAE 需要 critic value,GRPO 则利用同一个 prompt 下多条 response 构造相对基线。
先看整张地图。读这张图时,别急着盯 loss 公式,而要看阶段边界:哪些事发生在 controller 上,哪些事通过 WorkerGroup 或 manager 去远端执行,哪些字段会回到同一个 DataProto 里。
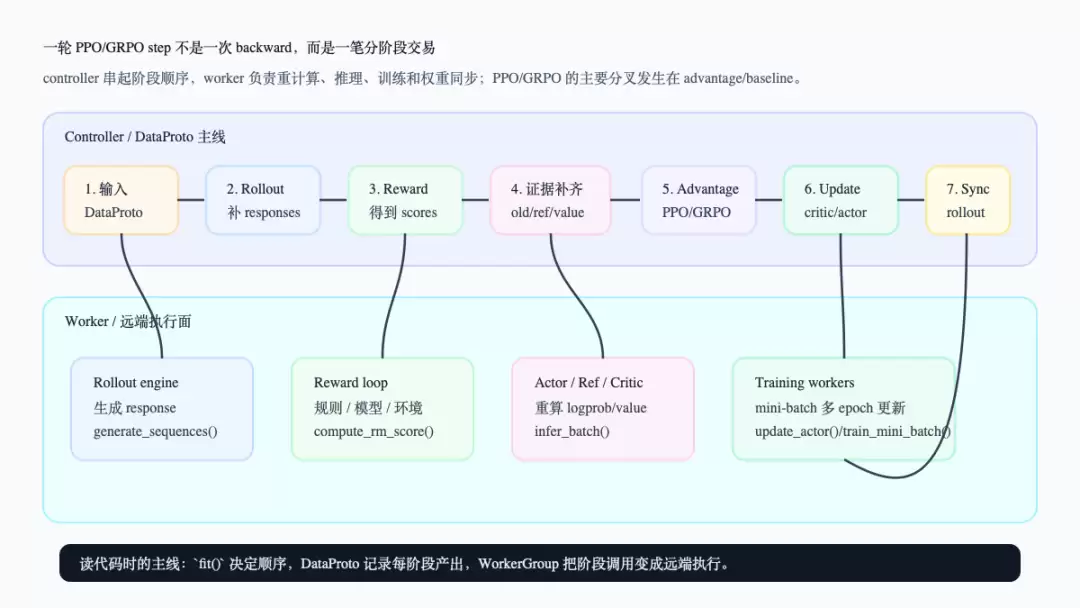
一轮 PPO/GRPO step 的阶段地图
这张图对应的是 RayPPOTrainer.fit() 的函数说明——driver 只需要通过 RPC 调用 worker group 的 compute functions 来构造 PPO dataflow,轻量 advantage 计算在 driver 上完成(`verl/trainer/ppo/ray_trainer.py:1274-1280`)。所以说,fit() 的角色不是一个 loss 函数,而是阶段编排器。
1. fit() 先把原始 batch 变成可追踪的训练样本
每一轮内层循环开始时,dataloader 产出的 `batch_dict` 会先被包成 `DataProto.from_single_dict(batch_dict)`,然后写入 rollout temperature,并给每条原始样本补一个 `uid`(`verl/trainer/ppo/ray_trainer.py:1330-1349`)。这个 `uid` 后面非常关键——因为一个 prompt 可能被 `rollout.n` 扩成多条 response,样本顺序也可能被 balance 改写。
接下来 trainer 调 `_get_gen_batch()` 准备生成输入。它会保留 reward 相关的 non-tensor key,例如 `data_source`、`reward_model`、`extra_info`、`uid`,并把 generation 不需要的对象列弹出去(`verl/trainer/ppo/ray_trainer.py:488-502`)。这一步说明 rollout 输入不是完整的训练 batch,而是一份给生成阶段裁剪过的 DataProto。
然后 `gen_batch` 会按 `rollout.n` repeat,送进 `async_rollout_manager.generate_sequences()`。生成完成后,主 batch 也按同样倍数 repeat,再和 rollout 输出 `union()`,于是原始 prompt batch 长出了 `responses` 等字段(`verl/trainer/ppo/ray_trainer.py:1351-1407`)。
下面这张图展示的是 DataProto 视角。它不是在重复第 5 篇的容器结构,而是说明一轮 step 中同一批样本如何逐段增加训练证据。
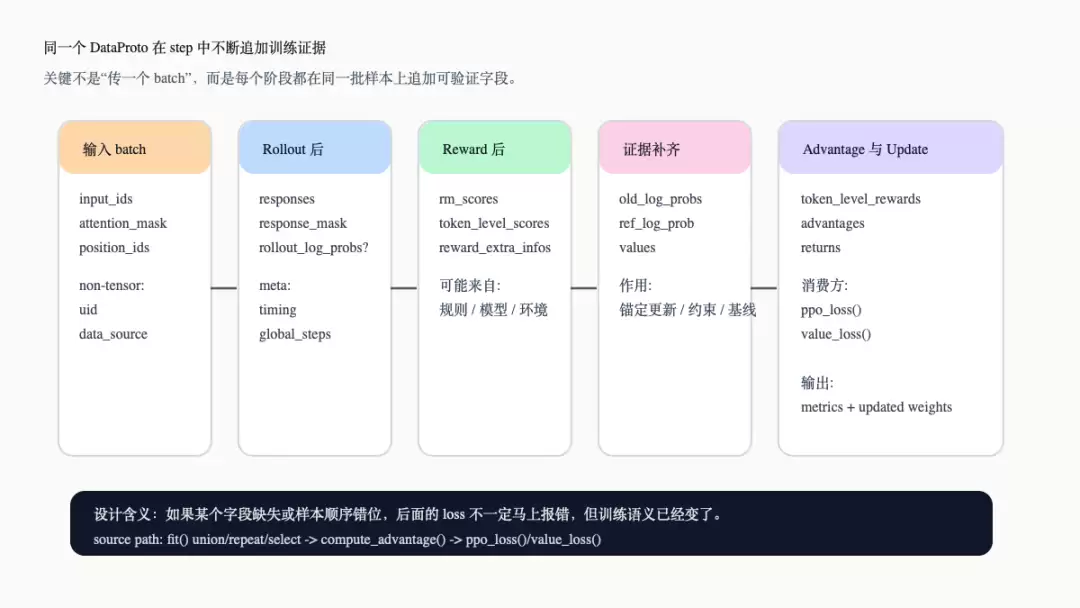
DataProto 在 step 中逐段长大
这张图的设计含义是:后面的 actor loss 不是直接消费 reward,而是消费一批已经补齐 `old_log_probs`、`advantages`、`response_mask` 等字段的训练证据。如果字段缺失、mask 错位或 uid 断裂,那问题不只是工程 bug,而是训练语义被直接改写。
2. 前半段先拿到 response 和 reward
rollout 之后,`fit()` 会确保存在 `response_mask`。如果 batch 里没有,它会用 `compute_response_mask()` 从 attention mask 的 response 区段切出 mask(`verl/trainer/ppo/ray_trainer.py:117-132`,`verl/trainer/ppo/ray_trainer.py:1408-1409`)。这一步把“哪些 token 是模型回答”固定下来,后面的 reward、advantage、actor loss 都会围绕 response tokens 计算。
如果启用了 batch balance,trainer 还会在 DP rank 之间平衡有效 token 数。源码注释明确提示,这通常会改变 batch 顺序,但 advantage 计算依赖 uid,所以不受样本顺序改变影响;loss 计算则可能因为 mini-batching 顺序变化而受影响(`verl/trainer/ppo/ray_trainer.py:1410-1415`)。一条很典型的系统事实:为了吞吐做的重排,必须被数据协议里的身份列兜住。
reward 阶段放在 rollout 后面。如果使用 reward model 且 batch 里还没有 `rm_scores`,trainer 会调用 `_compute_reward_colocate()`,再把 reward 输出 `union()` 回 batch;随后 `extract_reward(batch)` 取出训练用的 reward tensor 和额外信息(`verl/trainer/ppo/ray_trainer.py:1426-1433`)。`_compute_reward_colocate()` 本身只是转调 `reward_loop_manager.compute_rm_score(batch)`(`verl/trainer/ppo/ray_trainer.py:504-510`),说明 reward 在系统上可以是一个独立 loop,而不是 actor worker 的附属函数。
3. 中段补齐 old/ref/value,再计算 advantage
拿到 response 和 reward 还不够,PPO 更新还需要“更新前策略的锚”以及“约束或基线”。
`old_log_probs` 通常会被重新计算。`fit()` 中的默认路径会调用 `_compute_old_log_prob(batch)`,由 actor rollout worker 对当前 batch 做 logprob forward,再把 `old_log_probs` 合回 batch(`verl/trainer/ppo/ray_trainer.py:1435-1482`,`verl/trainer/ppo/ray_trainer.py:1168-1203`)。如果启用了 reference policy,trainer 会再调 `_compute_ref_log_prob()` 取得 `ref_log_prob`(`verl/trainer/ppo/ray_trainer.py:1484-1488`,`verl/trainer/ppo/ray_trainer.py:1144-1166`)。如果启用了 critic,则调 `_compute_values()` 取得 `values`(`verl/trainer/ppo/ray_trainer.py:1490-1494`,`verl/trainer/ppo/ray_trainer.py:1130-1142`)。
接下来才进入 advantage 阶段。`fit()` 先把 `reward_tensor` 写成 `token_level_scores`;如果配置 `algorithm.use_kl_in_reward`,会调用 `apply_kl_penalty()` 把 KL 惩罚并入 `token_level_rewards`,否则直接把 scores 作为 rewards(`verl/trainer/ppo/ray_trainer.py:1496-1512`)。然后它调用 `compute_advantage()`,把 `token_level_rewards`、mask、uid、values 等字段转成 `advantages` 和 `returns`(`verl/trainer/ppo/ray_trainer.py:1528-1541`)。
PPO/GRPO 的关键分叉就在这儿。下面这张图把分叉单独拉出来:左边是 GAE/PPO,右边是 GRPO。
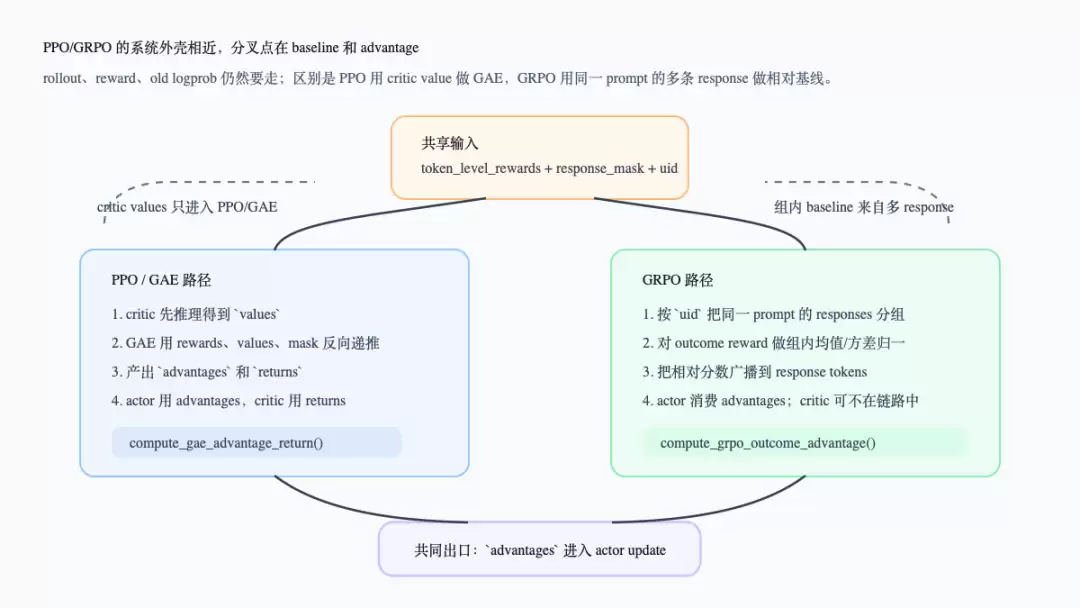
PPO 和 GRPO 在 advantage 阶段的分叉
在源码上,`compute_advantage()` 对 GAE 分支会把 `token_level_rewards`、`values` 和 `response_mask` 传给 `compute_gae_advantage_return()`,并写回 `advantages`、`returns`(`verl/trainer/ppo/ray_trainer.py:166-182`,`verl/trainer/ppo/core_algos.py:216-263`)。GRPO 分支不读 `values`,而是把 `token_level_rewards`、`response_mask` 和 `data.non_tensor_batch["uid"]` 传给 `compute_grpo_outcome_advantage()`(`verl/trainer/ppo/ray_trainer.py:183-195`)。后者会先按 uid 聚合同组 response 的 outcome reward,再做组内均值/方差归一,并把相对分数广播到 response mask 上(`verl/trainer/ppo/core_algos.py:268-331`)。
所以“GRPO 能省掉 critic”不是一句抽象的算法口号。在这条源码路径里,GRPO 的 advantage 计算不消费 `values`;系统上可以不把 critic 放进该 estimator 的必要路径。但这不等于所有配置都没有 critic,具体是否创建 critic 仍由 `need_critic(config)` 和 trainer 配置决定(`verl/trainer/ppo/ray_trainer.py:290-295`)。
4. 后半段更新模型,并把权重送回 rollout
advantage 写回 batch 后,`fit()` 进入更新阶段。若启用 critic,先调用 `_update_critic(batch)`,它会把 DataProto 转成 TensorDict、设置 mini-batch 和 epoch 信息,再调 `critic_wg.train_mini_batch()`(`verl/trainer/ppo/ray_trainer.py:1543-1548`,`verl/trainer/ppo/ray_trainer.py:1247-1272`)。worker 侧的 `train_mini_batch()` 会拆 mini-batch、多 epoch 迭代,并最终用 `engine.train_batch(data, loss_function=self.loss_fn)` 执行训练(`verl/workers/engine_workers.py:238-382`)。
如果还在 critic warmup,trainer 不更新 actor,只更新权重以唤醒 rollout replicas;否则进入 `_update_actor(batch)`。actor update 同样会设置 rollout temperature、mini-batch size、ppo epochs、shuffle 等信息,再通过 `actor_rollout_wg.update_actor(batch_td)` 触发远端 actor 训练(`verl/trainer/ppo/ray_trainer.py:1550-1557`,`verl/trainer/ppo/ray_trainer.py:1205-1245`)。actor worker 的 `update_actor()` 最终调用 actor 的 `train_mini_batch()`(`verl/workers/engine_workers.py:646-651`)。
actor 更新完成后,这轮 step 还没有结束。`fit()` 会调用 `checkpoint_manager.update_weights(self.global_steps)`,把训练后的权重同步回 rollout 侧(`verl/trainer/ppo/ray_trainer.py:1581-1586`)。这一步把训练系统和推理系统重新接上——下一轮 rollout 才会用到刚更新的策略。
最后这张图把一轮 step 放成时间线。它要表达的不是精确的耗时比例,而是优化时应该按阶段记账。
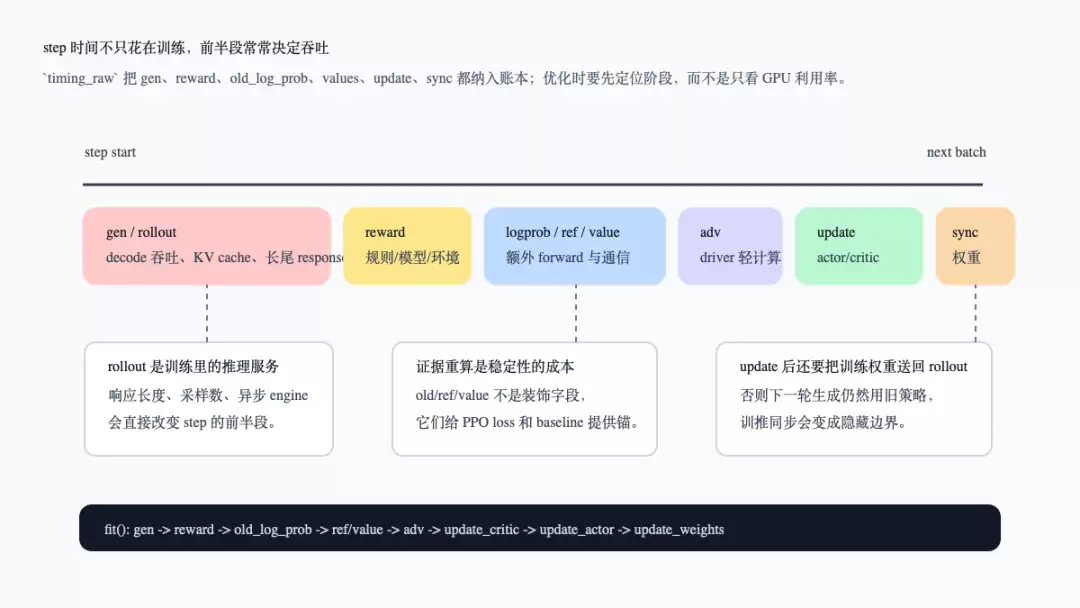
一轮 step 的瓶颈时间线
这张图对应 `fit()` 里的 `marked_timer`:`gen`、`reward`、`old_log_prob`、`values`、`adv`、`update_critic`、`update_actor`、`update_weights` 都被放进 `timing_raw`。这也是后训练 infra 的核心直觉:慢不一定慢在 backward。长尾 rollout、reward 环境、额外 forward、DataProto 搬运、权重同步,都可能让一轮 step 变长。
小结:第一组到这里形成了完整闭环
把第一组连起来看,verl 的后训练系统可以压成一条线:
training objective -> dataflow -> controller -> workers/resources-> DataProto -> PPO/GRPO step -> rollout/serving engine
一轮 PPO/GRPO step 的意义,是把前面几篇的抽象都落回同一个主循环:controller 决定顺序,DataProto 记录证据,WorkerGroup 执行远端计算,rollout engine 生成样本,reward loop 提供反馈,actor/critic worker 更新模型,weight sync 把训练结果送回生成侧。
下一组开始进入“算法如何落到工程”。第一篇先拆 PPO 在 LLM 后训练里到底训练了什么:actor、critic、reference policy、reward model 看起来都像模型,但它们在一轮 step 里的职责完全不同。
本文源码索引
- `verl/trainer/ppo/ray_trainer.py:117-132`:`compute_response_mask()` 如何取 response 区段 mask。
- `verl/trainer/ppo/ray_trainer.py:135-230`:`compute_advantage()` 的 GAE、GRPO 和其他 estimator 分支。
- `verl/trainer/ppo/ray_trainer.py:488-502`:`_get_gen_batch()` 如何裁剪 generation batch。
- `verl/trainer/ppo/ray_trainer.py:504-510`:reward loop 如何接入 `_compute_reward_colocate()`。
- `verl/trainer/ppo/ray_trainer.py:1130-1203`:value、ref logprob、old logprob 的计算路径。
- `verl/trainer/ppo/ray_trainer.py:1205-1272`:actor 与 critic update 的 trainer 侧入口。
- `verl/trainer/ppo/ray_trainer.py:1274-1586`:`fit()` 中一轮 step 的主阶段。
- `verl/trainer/ppo/core_algos.py:216-263`:GAE 如何用 reward、value、mask 计算 advantage/return。
- `verl/trainer/ppo/core_algos.py:268-331`:GRPO 如何按 uid 做组内相对 reward。
- `verl/workers/engine_workers.py:238-382`:worker 侧 mini-batch 训练如何执行。




