这篇文章只建立一个判断:AI后训练不是一次性跑完的训练脚本,而是一套持续生成轨迹、评估轨迹、组织训练信号、更新模型、再同步给推理侧的训推闭环系统。
如果只看命令行,python -m verl.trainer.main_ppo ... 这个指令,确实很容易让人以为它只是一个普通的训练入口:读配置、加载模型、跑 PPO/GRPO、保存 checkpoint。但进入 verl 源码一看,你会发现入口只是装配器;真正的系统由 TaskRunner、RayPPOTrainer.fit()、DataProto、WorkerGroup、rollout engine、reward loop 和 checkpoint/weight sync 共同组成。
第一篇的目标不是讲完 verl,而是给后续系列建立一幅地图:
training objective -> dataflow -> controller -> workers/resources -> rollout/serving engine -> weight sync -> production train/serve system
读完这篇,你应该能回答三个问题:入口脚本到底做了什么?PPO 主循环为什么必须把推理放进训练内环?后训练系统的瓶颈为什么常常出现在训练、推理、数据协议和分布式调用的连接处?
先把“训练脚本”这个错觉放下
普通监督训练的心智模型相对直:batch 进来,模型 forward,算 loss,backward,optimizer step,最后得到更新后的参数。分布式训练会让执行复杂很多,但主线仍然围绕静态数据集和一次参数更新展开。
RLHF、PPO、GRPO 后训练不一样。系统要先让当前策略模型生成 response,再把 response 交给规则、reward model、环境或 sandbox 打分;随后还要计算 old logprob、reference logprob、value、advantage,最后才轮到 actor/critic update。更新后的权重还要同步回 rollout 侧,让下一轮生成来自新策略。
下面这张图只负责建立入口心智:后训练不是一个脚本单点发力,而是一组训练、推理、评估和数据通道围成的系统。重点看中间的策略模型和周围资源之间的闭环关系,而不是把它当成源码结构图。

后训练不是脚本,而是训推闭环系统
这张图对应的是本文的核心判断:脚本只是打开系统的门。后面几节会把这个判断落到源码路径上——入口如何装配,主循环如何推进,数据协议如何承载轨迹,worker 调用如何跨 GPU 执行。
训练系统把推理放进了内环
后训练最容易被低估的变化是:推理不再是上线后的外部动作,而是训练 step 里的生产环节。在产品推理里,模型生成答案是终点;在 RL 后训练里,生成答案只是训练证据的起点。
下面这张图要看三条边:rollout 生成 response,reward/logprob/value 把 response 变成训练信号,actor 更新后通过 weight sync 影响下一轮 rollout。这个闭环解释了为什么后训练系统不能只按“训练脚本”理解。
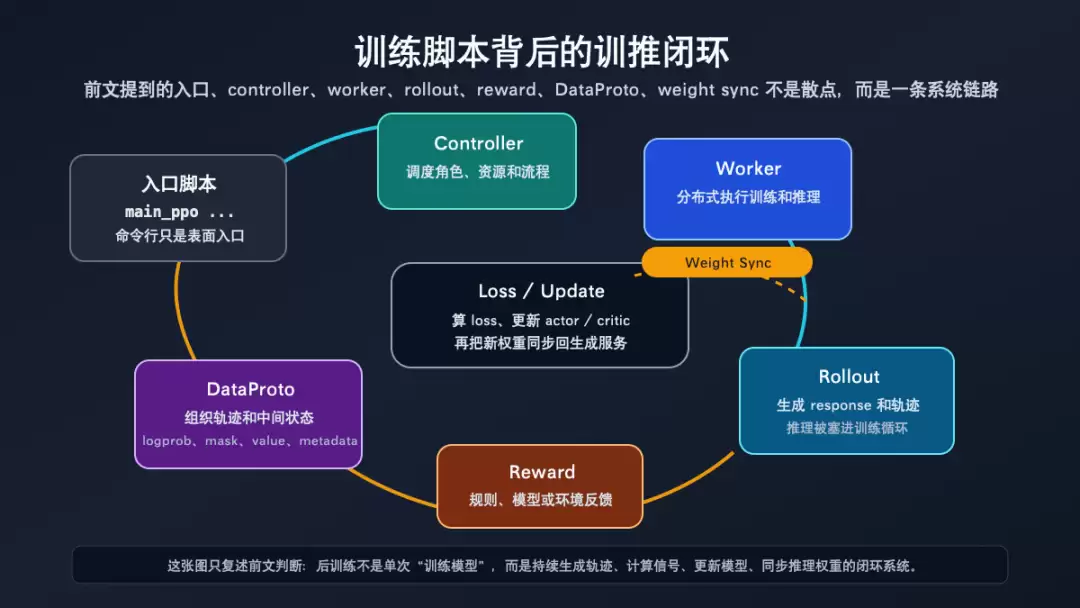
训练脚本背后的训推闭环
源码里,这个闭环集中间出现在 verl/trainer/ppo/ray_trainer.py:1274-1583 的 RayPPOTrainer.fit()。它先把 dataloader 产出的 batch_dict 变成 DataProto,再取 generation batch,调用 self.async_rollout_manager.generate_sequences(...) 生成结果,随后把 reward、old logprob、reference logprob、values、advantage 逐步并回 batch,最后更新 critic、actor,并通过 self.checkpoint_manager.update_weights(...) 同步 rollout 权重。
这揭示了一个系统事实:后训练的吞吐和稳定性不只由 backward 决定。rollout 慢、reward 慢、权重同步慢、token 轨迹和训练侧对不齐——随便哪一个出问题,整条链路都得卡住。
main_ppo.py 只是装配器
理解 verl 时,不要把入口文件误读成算法主体。verl/trainer/main_ppo.py:48-98 的 run_ppo() 负责初始化 Ray,并启动远程 TaskRunner;真正的角色、资源、数据集和 trainer 装配发生在 TaskRunner.run()。
下面这张图要看 TaskRunner.run() 中间的装配清单:role mapping、resource pool、tokenizer/processor、dataset、RayPPOTrainer。这些对象准备好之后,代码才进入 trainer.init_workers() 和 trainer.fit()。
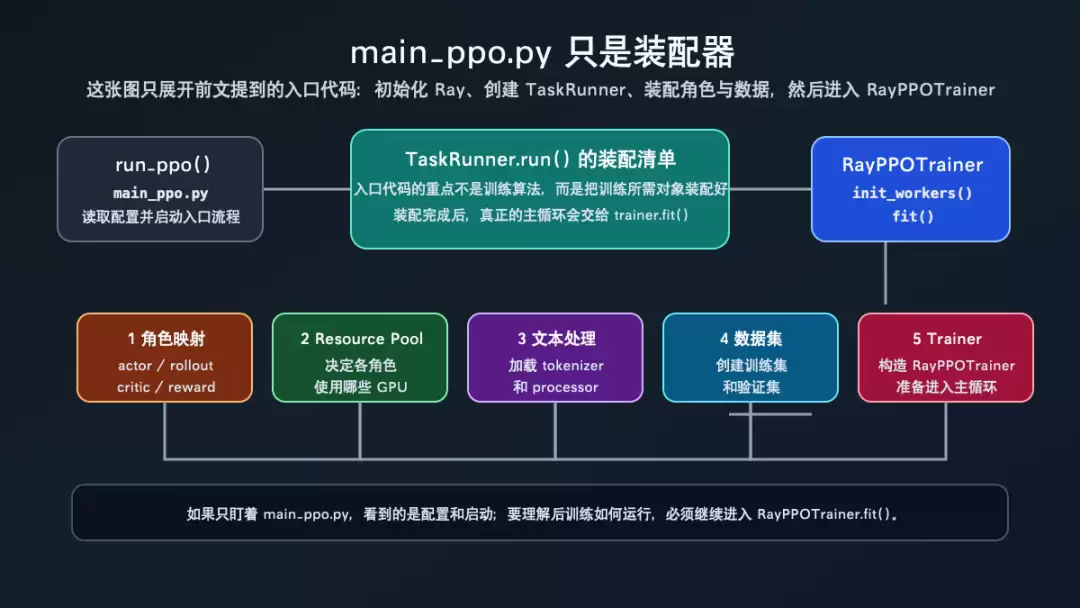
main_ppo.py 入口装配流程
图里的每个节点都能在源码里找到对应位置:
TaskRunner.add_actor_rollout_worker() 和 add_critic_worker() 建立 role 到 worker class 的映射,见 verl/trainer/main_ppo.py:122-153。 TaskRunner.init_resource_pool_mgr() 建立 role 到 resource pool 的映射,见 verl/trainer/main_ppo.py:154-187。 TaskRunner.run() 创建 tokenizer、processor、train/val dataset、sampler 和 RayPPOTrainer,见 verl/trainer/main_ppo.py:219-311。
说白了,入口脚本的核心作用就是“把系统对象摆到位”。如果想理解后训练如何运行,下一步必须看 RayPPOTrainer.init_workers() 和 RayPPOTrainer.fit()。
fit() 写出一轮 PPO step 的 dataflow
RayPPOTrainer.fit() 的 docstring 说得很直接:PPO 训练循环运行在 driver process 上,driver 通过 RPC 调用 worker group 上的 compute functions 来构造 PPO dataflow,轻量的 advantage 计算在 driver 上完成。这个说明位于 verl/trainer/ppo/ray_trainer.py:1274-1279。
下面这张图要按编号读,不要只看颜色。它把一轮 step 压成 13 个节点:从 batch_dict 到 DataProto,再到 rollout、reward、logprob/value、advantage、actor/critic update,最后同步 rollout weights。
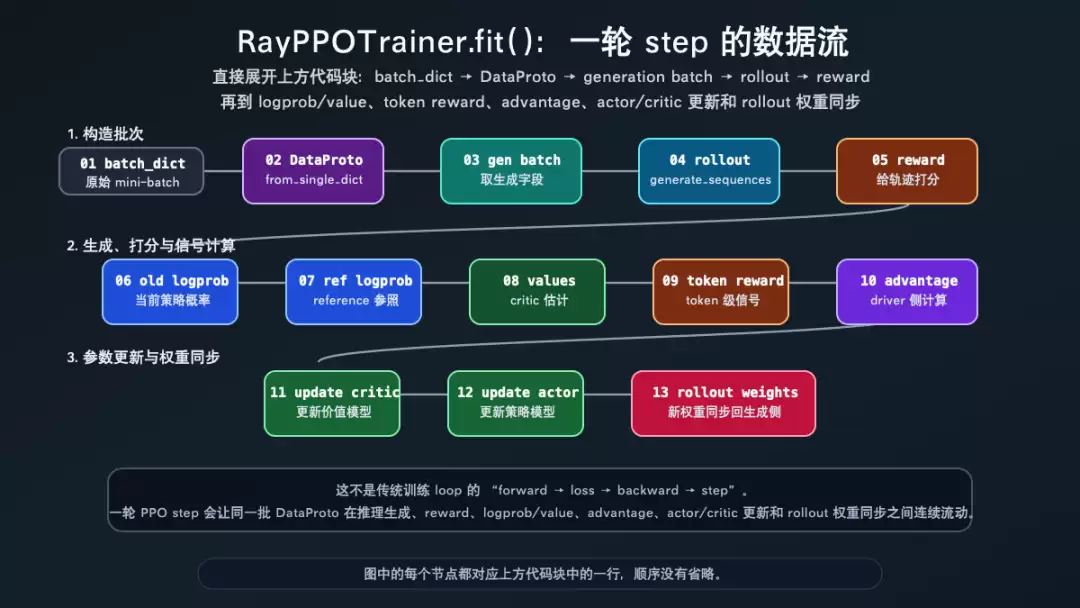
RayPPOTrainer.fit 一轮 step 的数据流
图后的关键源码顺序是:
DataProto.from_single_dict(batch_dict) 创建 batch 容器,见 verl/trainer/ppo/ray_trainer.py:1343-1345。 generate_sequences() 生成 rollout,并在生成后让 replicas sleep,见 verl/trainer/ppo/ray_trainer.py:1374-1381。 batch.union(gen_batch_output) 把生成结果并回 batch,见 verl/trainer/ppo/ray_trainer.py:1404-1407。 reward、old logprob、reference logprob、values、advantage 依次进入 batch,见 verl/trainer/ppo/ray_trainer.py:1426-1541。 critic/actor 更新和 rollout 权重同步发生在 step 后段,见 verl/trainer/ppo/ray_trainer.py:1543-1583。
这已经不是传统的 forward -> loss -> backward -> step。更准确的说法是:fit() 在 controller 上写了一条高层 dataflow,真正的神经网络计算分散到 worker、rollout server 和 reward loop 里执行。
DataProto 和 WorkerGroup 把边界收起来
既然后训练是一条跨组件 dataflow,就会出现两个问题:数据怎么沿着流程流动?计算怎么落到多 GPU worker 上?
verl 用两类抽象回答这两个问题。DataProto 解决数据协议,WorkerGroup 解决分布式调用。下面这张图把它们放在同一张图里看:左边是“函数调用如何变成 worker 调用”,中间是“actor、rollout、reference 如何在同一个 worker 壳里桥接”,右边是“瓶颈为什么常常出现在连接处”。
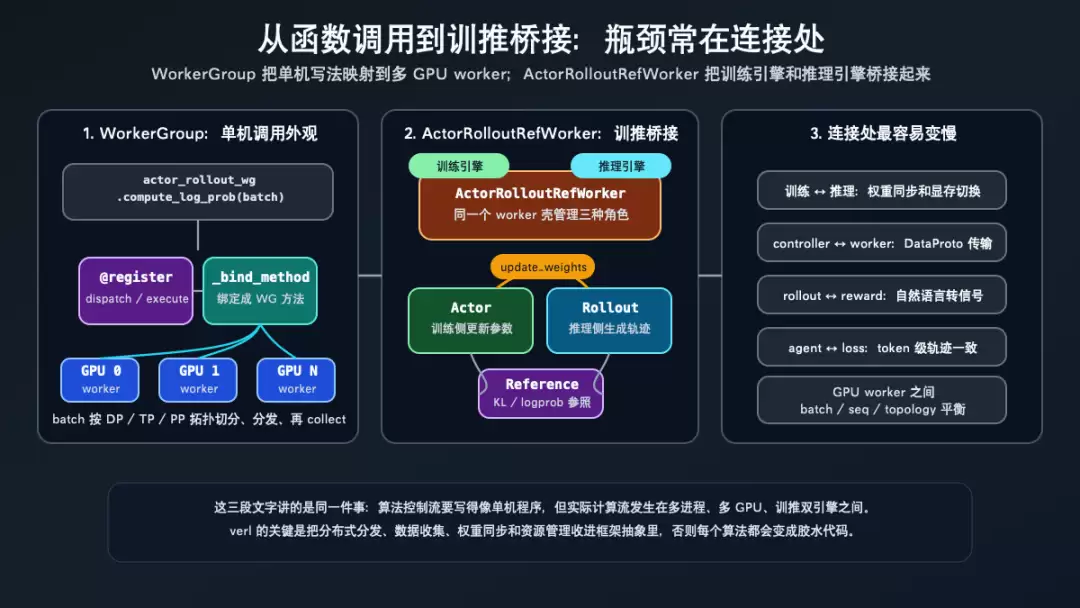
WorkerGroup 分布式调用、训推桥接和连接处瓶颈
DataProto 定义在 verl/protocol.py:318-328,它把 tensor 数据放在 batch,非 tensor 字段放在 non_tensor_batch,控制信息放在 meta_info。from_single_dict() 会把 torch tensor 和 numpy array 分开,见 verl/protocol.py:480-493;union() 会把不同阶段产出的字段合并回同一个容器,见 verl/protocol.py:781-798;chunk() / concat() 则支撑分发和收集,见 verl/protocol.py:864-930。
WorkerGroup 定义在 verl/single_controller/base/worker_group.py:123-245。它会扫描 worker class 上被 @register 标注的方法,并把这些方法绑定成 driver 可以调用的 WorkerGroup 方法。@register 本身在 verl/single_controller/base/decorator.py:398-444,它保存 dispatch mode、execute mode、blocking 等分布式执行元信息。
在 worker 侧,verl/workers/engine_workers.py:631-650 可以看到 compute_ref_log_prob()、compute_log_prob()、update_actor() 都通过 @register 暴露成分布式接口。这就是为什么 controller 上看起来像普通函数调用,实际背后会发生数据切分、remote execute 和结果收集。
这个设计买到的是算法可读性:controller 能写出清晰的 PPO dataflow。它付出的代价也很明确:DataProto 要在边界之间往返,训练引擎和推理引擎要同步权重,连接处就可能成为吞吐、显存和稳定性的瓶颈。
小结:先把 verl 看成一个分层系统
第一篇最后只需要留下一个系统地图:main_ppo.py 不是后训练的主体,fit() 也不是单机训练循环;verl 的主体是一组围绕轨迹生成、信号计算、参数更新和权重同步组织起来的分层系统。
下面这张图是本文的收束图。它把前文的入口、控制流、数据协议、分布式调用、训推桥接和计算引擎放到同一张分层图里。读后续文章时,可以把它当作目录:每篇文章都会沿着其中一层往下拆。

verl 后训练闭环系统分层
第一篇到这里先收住:后训练不是单次优化静态数据集,而是持续生产轨迹、评估轨迹、组织训练信号、更新模型、同步推理权重的闭环系统。
下一篇会继续拆第一层关键机制:为什么 HybridFlow 要把 RLHF 看成高层 dataflow,以及为什么 verl 选择把算法控制流留在 single controller。
本文源码索引
verl/trainer/main_ppo.py:48-98:run_ppo() 初始化 Ray 并启动 TaskRunner。
verl/trainer/main_ppo.py:122-187:TaskRunner 建立 role、worker class 和 resource pool 的映射。
verl/trainer/main_ppo.py:219-311:TaskRunner.run() 创建 dataset、sampler、RayPPOTrainer,并调用 init_workers()/fit()。
verl/trainer/ppo/ray_trainer.py:688-884:init_workers() 创建 resource pool、WorkerGroup、rollout manager 和 checkpoint manager。
verl/trainer/ppo/ray_trainer.py:1274-1583:fit() 写出 PPO 主循环和 rollout、reward、logprob、advantage、actor/critic update、weight sync 顺序。
verl/protocol.py:318-328、480-493、781-798、864-930:DataProto 的数据结构、创建、合并、切分与拼接。
verl/single_controller/base/worker_group.py:123-245:WorkerGroup 绑定被 @register 标注的 worker 方法。
verl/single_controller/base/decorator.py:398-444:@register 保存分布式执行元信息。
verl/workers/engine_workers.py:631-650:actor/ref 侧 logprob 和 actor update 暴露为分布式 worker 方法。




