百度智能云优化Cosmos3的AI基础设施单机吞吐提升99.3%
时间:2026-07-02 11:19
百度智能云完成Cosmos3系统性AIInfra工程优化,单机吞吐提升99 3%,训练启动速度提升89倍,MFU达0 42,超越官方GB200集群基准。12节点扩展效率98 3%。优化涵盖任务启动、I O吞吐、编译适配、显存利用及多机扩展,精度无损且收敛一致。
6 月 30 日,百度智能云宣布其旗下的 AI 计算平台百度百舸,已经针对 NVIDIA 最新开源的全模态世界模型 Cosmos 3,完成了一次系统性的 AI Infra 工程优化。这次优化的结果相当亮眼:在不依赖 NVLink 与 HPN 的情况下,基于国内主流 GPU,Cosmos3-Nano-Policy-DROID 训练启动速度提升了 89 倍,单机吞吐提升了 99.3%,MFU 达到了 0.42,直接超过了官方论文中 GB200 集群 0.23-0.3 的基准;而 12 节点的扩展效率也达到了 98.3%,集群算力得到了充分释放。
从“能跑”到“好用”:工程优化为什么是绕不开的一步
Cosmos 3 是目前具身智能后训练阶段的核心基座模型之一,它的 Nano-Policy-DROID 版本在机器人领域尤其受关注。不过,官方论文里给出的训练环境,是基于 1024 张 NVIDIA GB200 GPU 的超大规模集群,并且依赖 NVLink 与 HPN 来实现高效扩展。说实话,这对国内大多数企业和研究机构来说,门槛确实有点高。所以,怎么在通用的 AI 算力环境下,充分释放模型训练的性能,就成了能否落地应用的关键问题。
为了解决这个难题,百度智能云从数据加载、I/O 流水线、显存利用、编译优化到多机扩展,一个环节一个环节地排查,系统地解决了社区版本在生产环境中会碰到的性能瓶颈。更重要的是,他们还针对国内主流 GPU 的特性,进一步挖掘和释放了训练潜力。
五大核心优化成果
**任务启动优化**:社区代码在加载 Cosmos3-DROID 数据集时,因为读取了冗余字段,导致峰值内存一度飙到 1734 GB,直接把 8 卡训练任务给“撑死”了。百度智能云通过 Parquet 列裁剪和数据拷贝路径重构,把启动时间从 37.2 分钟压缩到了 25 秒,峰值内存也降到 46 GB,降幅高达 97%。

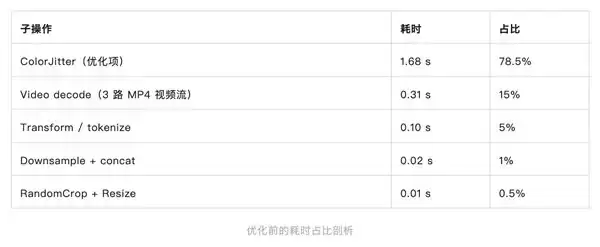
**I/O 吞吐瓶颈突破**:通过 profiling 定位发现,ColorJitter(图像数据增强)这个操作占了 CPU 端 78.5% 的耗时,这才是 GPU 长时间空闲等待的根源。于是,他们把 ColorJitter 算子从 CPU 迁移到 GPU 上执行,单样本数据处理时间从 2.12 秒直接降到 0.52 秒,训练吞吐提升了 50%。
**torch.compile 适配**:社区默认的算子融合策略,超出了国内主流 GPU 的 Shared Memory 资源限制,导致编译功能直接失效。百度智能云通过调整配置,禁用了 mix-order reduction 策略,成功解锁了编译加速,训练吞吐再次提升 28.6%。
**分层 Activation Checkpointing**:社区默认对所有 36 层 Transformer 开启 Full AC,这其实是在浪费显存。百度智能云开发了分层 AC(Layer-wise AC)策略,在显存占用和重算开销之间找到了一个更优的平衡点,吞吐提升了 3.1%。
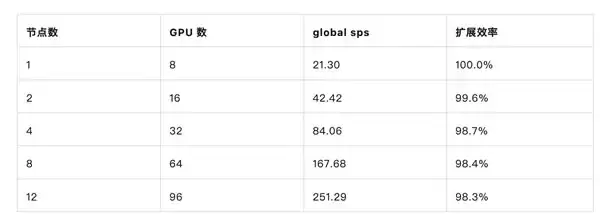
**多机集群扩展**:依托百度百舸的弹性 RDMA 互联(ERI)网络,配合 HSDP 并行策略和精细的计算通信 Overlap 调优,12 节点(96 卡)的扩展效率达到了 98.3%,支撑起了训练资源的多样化布局。
精度无损,MFU 超越旗舰基准
值得一提的是,所有这些优化都是精确等价变换或 Pipeline 优化。从 Loss 曲线对比来看,优化后的版本与官方 Baseline 的收敛趋势完全一致。最终,在百度智能云实例上的 MFU 达到了 0.42,超过了官方论文中基于 GB200 集群的 0.23-0.3 基准。
持续深耕具身智能训推加速
目前,除了 Cosmos 3,百度智能云在具身智能场景下,已经交付了 OpenPI、DreamZero、GR00T N1.6、Lingbot-VLA、Motus、AHA-WAM、FastWAM、Wan2.2 等多个模型的训推加速成果。百度智能云也明确表示,这次优化只是释放 Cosmos 3 性能的第一步,后续还会在集群层面,通过计算资源与模型结构的协同设计,进一步挖掘集群潜力、降低训练成本。




