今天我们来聊聊一个在生物学计算领域的重要进展——OpenAI最新推出的GeneBench-Pro基准测试。这个新工具专门用于评估AI模型在真实科研场景下的表现,不再让模型依靠死记硬背或机械执行步骤,而是让它在数据混乱、不完整的环境中像真正的研究者那样分析和决策。简单来说,就是把模型直接投入一个充满噪声、缺失信息甚至带有误导性的数据集,看它能否像真正的科研人员一样做出判断、找到正确的分析方向。
传统的基准测试往往只是测试模型的知识记忆能力或按固定流程执行任务的能力,但真实的科研工作远比这复杂。实际数据集可能存在噪声、缺失值甚至误导信息,这时真正考验的是分析判断力和方法选择能力。GeneBench-Pro的核心价值,正是检验AI在模糊、不完整甚至带有干扰的数据环境中拆解问题、得出科学结论的综合能力。这才是科研场景下真正的“硬实力”。
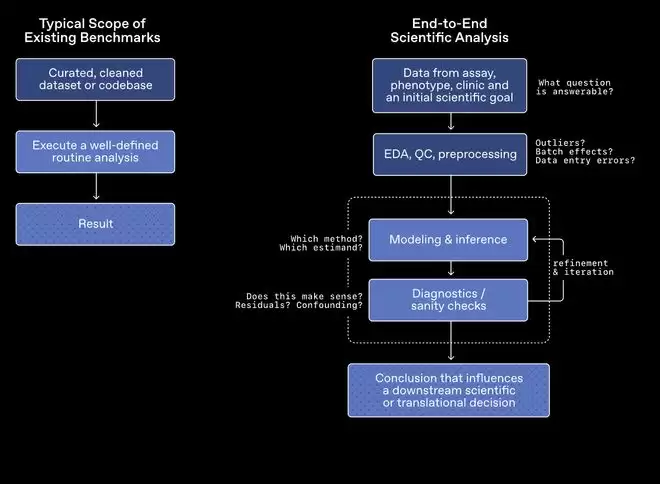
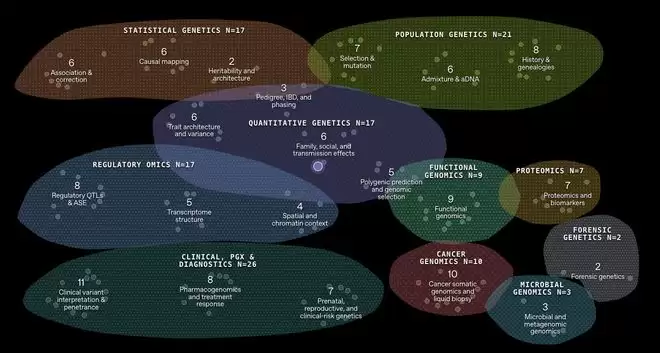
具体来看,这个评测覆盖的范围相当全面,共包含129道题目,分布在10个主要领域和21个子领域。统计遗传学、群体遗传学、功能基因组学、蛋白质组学……几乎涵盖了当前生物计算的核心研究方向。每道题提供给模型的,是一份贴近真实科研流程的数据集,加上简短的实验背景说明,以及一个直接关联后续决策的目标问题。模型必须从零开始,自主完成数据探索、选择分析方法、在过程中不断调整策略,最终给出答案。这绝对不是单纯调用知识库就能完成的任务。
一个值得深入探讨的设计亮点在于评分机制。为了避免传统长流程基准测试中常见的偏差问题,OpenAI这次采用合成数据作为核心构建材料。如果直接使用历史真实数据出题,存在一个隐患:很多问题本身就有多条合理的分析路径,模型即便用了错误的方法,也可能碰巧撞出正确答案。而合成数据则不同——OpenAI可以完全控制底层的因果结构和数据生成过程,从而更精确地判断模型到底是真正理解了问题本质,还是在走捷径。
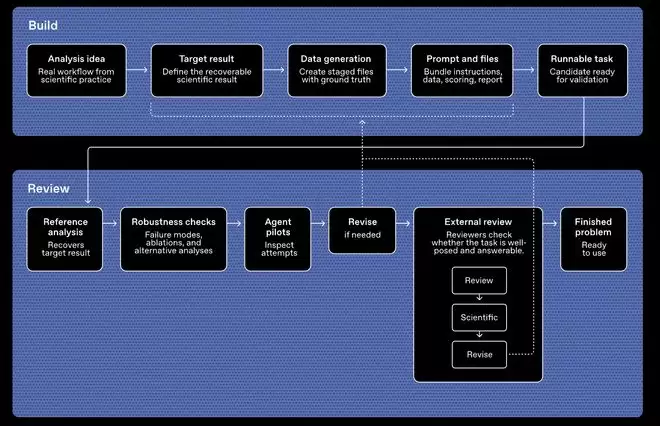
目前,OpenAI已经在Hugging Face上开源了10道具有代表性的示例题,同时提供了可交互界面,供外部研究人员亲自体验和验证。后续还有50道题将交由Artificial Analysis进行第三方独立评测,用于客观对比不同模型在这个测试中的真实表现。此外,值得留意的是,他们还准备了一份评估提示词参考清单(Prompt Guide),帮助用户更清楚地理解测试逻辑与评估标准。




