第一章 概述
1.1 转炉炼钢简介[1,2,3]
钢铁,作为现代工业的脊梁,其战略地位不言而喻。一个国家钢材的产量、质量与品种,几乎就是其工业化水平的“成绩单”。我国连续多年钢产量突破1亿吨,稳居世界钢铁大国之列。但一个现实是,作为发展中国家,废钢资源相对匮乏,因此钢产量的持续攀升,很大程度上依赖于转炉炼钢技术的不断突破与革新。从1983年全国转炉炼钢会议将氧气顶吹转炉的静态与动态控制列为国家重点科研项目开始,这一关键技术就进入了快速发展通道。
 氧气顶吹转炉炼钢设备图
氧气顶吹转炉炼钢设备图
转炉炼钢技术的发展并非一蹴而就。1856年,英国人亨利·贝塞麦发明了酸性底吹转炉,首次实现了液态钢的规模化生产。随后,平炉炼钢法问世,有效解决了废钢炼钢的难题。真正让转炉炼钢迎来爆发式增长的是二战后,工业制氧成本大幅下降,使氧气炼钢成为现实。1952年和1953年,奥地利的林茨厂和多纳维茨厂率先成功应用氧气顶吹转炉工艺,这便是后来闻名世界的LD炼钢法。与此同时,电弧炉也在德国诞生。如今,钢铁工业的完整链条涵盖从炼铁到轧钢的全流程,而氧气顶吹转炉已成为全球主流的炼钢方法。
1.2 转炉炼钢自动化技术
转炉炼钢是一项复杂的工艺,其高温、快速反应、短周期的特点,加之众多影响因素,使其成为一个多相、多变量、反应耦合的“大系统”。其核心任务非常明确:一是将铁水中的大部分碳转化为CO气体吹出炉外,二是通过放热反应将钢水加热到目标出钢温度。
现实情况是,国内许多炼钢厂仍依赖“凭经验”操作。然而,操作人员技术水平参差不齐,冶炼工况千变万化,检测手段也相对滞后,难以实现规范化、标准化生产。当前冶炼的钢种日趋多样化,对钢水质量的要求越来越高,原材料波动又较大,仅凭人工经验已显得力不从心。

添加图片注释,不超过 140 字(可选)
此时,计算机的优势得以充分展现。它能在极短的时间内对各种参数进行快速、高效的计算与处理,精准控制冶炼过程及钢水终点。实践表明,采用计算机控制不仅能显著改善钢水质量、实现特种钢冶炼,还能提升效率、降低能耗、改善劳动条件。计算机技术在钢铁生产中的应用水平,已成为衡量企业现代化程度的重要标尺。自20世纪60年代美国Jones&Laughlin钢铁公司率先开发转炉静态控制模型以来,转炉炼钢自动控制的序幕正式拉开。到了90年代,日本学者成功实现了转炉的全自动吹炼。
目前,计算机控制主要分为静态控制和动态控制两种模式。从长远来看,动态控制是发展方向。但问题是,现有的测试手段尚无法对熔池温度和碳含量进行可靠的连续测量,难以及时、准确地将信息反馈至计算机系统。因此,对绝大多数工厂而言,现实的选择是先迈出第一步——实现静态控制。
1.2.1静态控制
静态控制,通俗地说是一种“计划型”控制方式。它根据已知的原料条件、目标钢种的成分和温度要求,运用物料平衡与热平衡原理,结合统计分析和操作经验,提前计算出铁水、废钢、冷却剂、辅料及吹氧量。然后按此“配方”进行装料和吹炼,过程中基本不做调整修正。
回顾静态控制的发展历程,主流的模型可归纳为几类:理论模型、经验模型、统计模型和人工神经网络模型。
先说理论模型。它通过对冶炼过程多类参数的分析及一系列假设,进行热平衡计算,从而得到装料模型。不过,由于炼钢过程极为复杂,许多反应机理尚未完全明确,纯理论模型难以直接应用。现实中所谓的理论模型,大多是半机理半经验模型。例如芬兰的罗德洛基公司,其模型基于物理化学定律进行实时计算,装料部分则依托物质与能量平衡。
其次是经验模型,也称增量模型。武汉第一炼钢厂采用的就是这种模型,由矿石量增量和供氧量增量两个方程构成,在实际应用中运行稳定。南京科技大学为宝钢研制的系统以及梅山炼钢厂也采用了增量模型,并加入了自学习功能,取得了良好效果。
统计模型同样应用广泛。东北工学院曾采用机理分析与复合回归分析相结合的方法,建立了终点温度和含碳量的预报模型。首钢技术中心也通过对大量数据的分析,建立了供氧量、钢铁料消耗、终点温度等统计方程。在影响因素众多且变量相互制约时,统计模型能够抓住关键因素,对实际生产具有较强的指导意义。
最后是人工神经网络模型,其发展速度迅猛。国内外学者都在积极运用它来解决静态控制问题。例如钢铁研究总院开发的基于双输出人工神经网络的碳温控制模型。由于回归模型的实时性和精度有限,而人工神经网络在处理非线性动态系统方面具有天然优势,且容错能力强,因而能够取得更好的预报效果。
1.2.2动态控制
动态控制与静态控制有所不同,它在吹炼前完成装料计算后,在吹炼过程中实现“边吹边看”。借助副枪等工具,实时监测钢液的温度、成分及废气信息等,对终点进行预测和判断,动态调整吹炼参数,最终精准达到目标。相比静态控制,动态控制适应性更强、精度更高,能够实现“最佳控制”。其关键就在于能否快速、准确、连续地获取熔池的温度和碳含量这两个核心参数。
1.3 转炉吹炼过程控制系统的发展过程
自1959年美国Jones&Laughlin公司首次将计算机用于控制转炉以来,世界各国的研究就从未停歇。转炉吹炼控制系统的发展大致经历了三个阶段。
1.3.1离线(在线)开环静态控制
这是最基础的控制形式。计算机根据静态模型计算出石灰、铁矿石、吹氧量等参数。吹炼时,计算机按照固定模式控制枪位、加料和供氧。由于模型固定,不利用过程信息进行修正,属于开环控制,因此也称为“开环静态控制”。
1.3.2在线闭环动态控制
在静态控制基础上,引入直接测试(副枪法)或间接测试(质谱法)等手段。在吹炼过程中,无需倒炉、不中断吹炼,即可自动监测钢水成分和温度,并将信息反馈给计算机构成闭环。系统对静态控制的曲线进行动态校正,从而大幅提高终点碳和温度的控制命中率。
美国Jones&Laughlin公司在静态控制成功后,率先开展动态控制研究,采用的是轨道修正法。1970年,伯利恒钢厂在270吨转炉上配合副枪实现了终点控制。日本的鹿岛厂从1982年起应用基于副枪的终点控制系统,并于1992年开发了由动态模型和反馈计算模型组成的新系统。在国内,鞍钢第三炼钢厂引进了奥钢联的系统,实现了75%的终点碳温命中率。东北工学院也深入研究了转炉后期动态模型,提出了用二维线性状态方程描述脱碳率和升温速度的方法。
1.3.3智能、集成、复合控制
这是当前及未来的发展方向。日本住友公司鹿岛厂开发了具有参数自整定功能的终点控制系统,通过分析炉气成分来动态调整模型。近年来,随着数据采集精度的提升和人工智能技术的成熟,尤其是欧美和日本的炼钢过程控制,已经达到了前所未有的高水平。
在国内,宝钢是先行者。从1985年引进日本动态模型效果不佳,到第二炼钢厂基于神经网络和数据库开发新模型取得成功,再到后来引入专家系统,开发出“宝钢转炉吹炼控制模拟在线专家系统”,始终走在行业前列。上海大学、钢铁研究总院等单位也都在研究终点锰磷的动态控制及终点预报。如今,武钢、首钢等钢厂也已推广了基于人工智能的静态控制自动化炼钢工艺。
1.4 研究方案
1.4.1本选题研究的主要内容
氧气顶吹转炉炼钢终点控制的核心,在于协调控制冷却剂和吹氧量,同时命中两个关键目标:期望的碳含量(约0.045%)和期望的钢水温度(约1670°C)。
目前,国内除宝钢、首钢、武钢等少数企业已应用动态控制外,大多数冶炼厂的控制水平仍然偏低。受限于资金和技术条件,我国绝大多数转炉厂采用100吨以下的中型、小型转炉,难以安装副枪来实现动态控制。因此,静态控制成为一个现实且重要的选择。
静态控制具有多重意义。首先,它投资省,特别适合中小型转炉。其次,静态模型是动态控制的基础,深入研究静态模型能够为未来升级动态控制积累经验、铺平道路。与人工经验相比,静态控制能够有效利用初始条件进行定量计算,显著提高终点命中率。
基于以上考虑,本研究的主要内容聚焦于转炉炼钢终点静态控制,并计划在TT集团炼钢厂进行推广应用,为将来安装副枪、实现动态控制打下基础、积累实践经验。
1.4.2本论文的组织安排
概述部分回顾了氧气顶吹转炉炼钢控制技术的全貌,并结合TT集团炼钢厂的实际条件,明确了其终点控制模型的研究方向。第二章将详细介绍TT集团炼钢厂的技术工艺,这为后续的建模工作奠定了坚实的工艺理论基础。
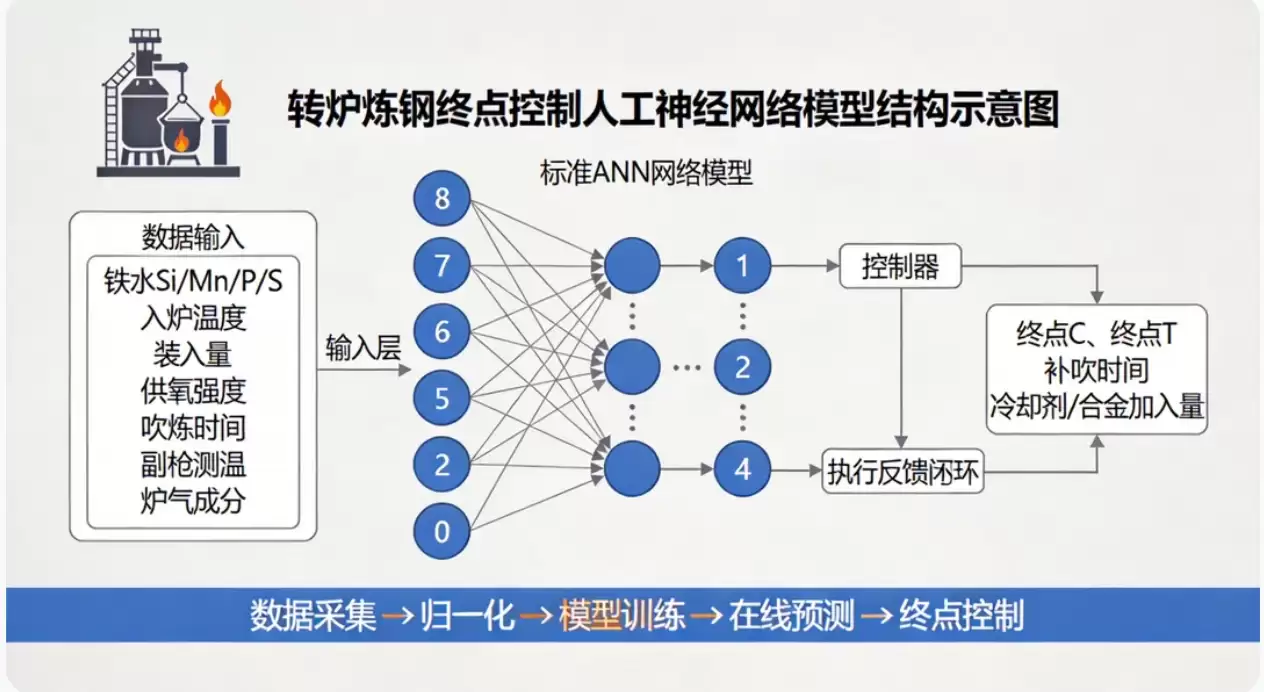
添加图片注释,不超过 140 字(可选)
接下来,我们将以冶金基础理论为起点,结合TT集团炼钢厂的大量生产数据和现场经验,通过理论推导和统计分析,深入探明各变量之间的关系。我们将重点建立两个模型:一是静态控制理论模型,包含控制终点碳含量的总吹氧量方程,以及控制终点温度的矿石量方程;二是统计数学模型,反映终点碳含量和温度之间的回归关系。最后,通过实验研究和多元逐步回归分析,对模型进行优化和现场检验修正,使其能够真正应用于生产实践。
在研究的最终阶段,我们将利用BP人工神经网络,并结合部分专家规则,构建一个终点控制的人工神经网络模型。我们将使用TT集团炼钢厂的实际生产数据对网络进行系统学习、模拟预测。最终,我们将深入分析可控参数、中间参数与终点碳温参数之间的定量和定性关系,构建出一个较为完整、可用于实际指导的终点控制人工神经网络模型。




