不满足于只在纸上照着自己的想法写写画画,但又没精力去啃专业的3D建模软件——这个问题困扰过多少人?你想过没有,只需用文字描述你脑海中的画面,就能生成一个分辨率高达4K的实体3D模型?
先直接说结论:现在,Nvidia发布的Edify 3D,就能帮你把这事儿搞定。只要创意足够,你甚至可以用它来复活经典游戏和电影中的角色,比如那个圆滚滚的小黄人。

官方视频演示非常直观:用户仅需输入一段文字描述,Edify 3D便可即时生成高清晰度的3D布景、头骨、乌龟等实体模型。
长期以来,创建3D内容所需的专业技能门槛过高,导致3D资产比图像和视频稀缺得多。这种稀缺性,恰恰是当前研究要攻关的核心——如何设计可扩展的模型,从有限的数据中高效生成高质量的3D资产。
Edify 3D给出的答案是:2分钟内,根据文本描述或前景图像,就能生成一个细节丰富、拓扑清晰、UV映射井井有条、纹理分辨率高达4K,并且附带基于物理材质渲染的高质量3D资产。与其他文本到3D的方法相比,Edify 3D在形状和纹理的生成质量上始终表现更优,在效率和可扩展性上更是跨了一大步。
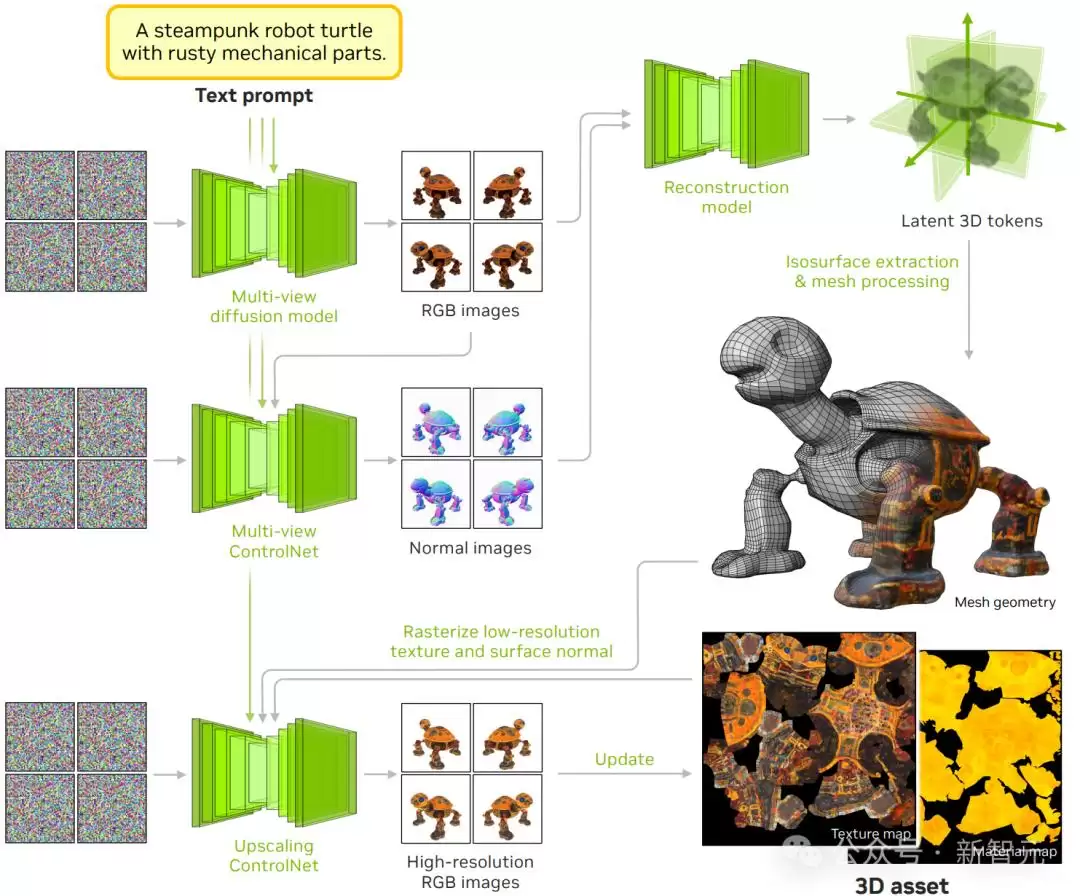
Edify 3D的流程
具体流程是这样的:当你输入一段关于3D实体的文字描述后,多视图扩散模型会负责合成该对象的RGB外观。接着,这个多视图RGB图像会被传入一个多视图ControlNet去合成表面法线。然后,重建模型把多视图RGB图和法线图作为输入,通过一组潜在标记去预测神经3D表示。接下来就是抽等值面,再对生成的网格进行后处理,得到最终的网格几何形状。最后,还需要一个放大版的ControlNet来提升纹理分辨率,它会对网格光栅化后的图像进行调节,生成高分辨率的多视图RGB图像,再反向投影到纹理贴图上。
多视图扩散模型
创建多视图图像的过程,从设计思路上看,有点像视频生成。研究者通过给文本到图像模型加上相机姿态条件,把它微调成一个能识别姿态的多视图扩散模型。这个模型接收文本提示和摄像机姿态作为输入,然后从不同视角合成物体的外观。
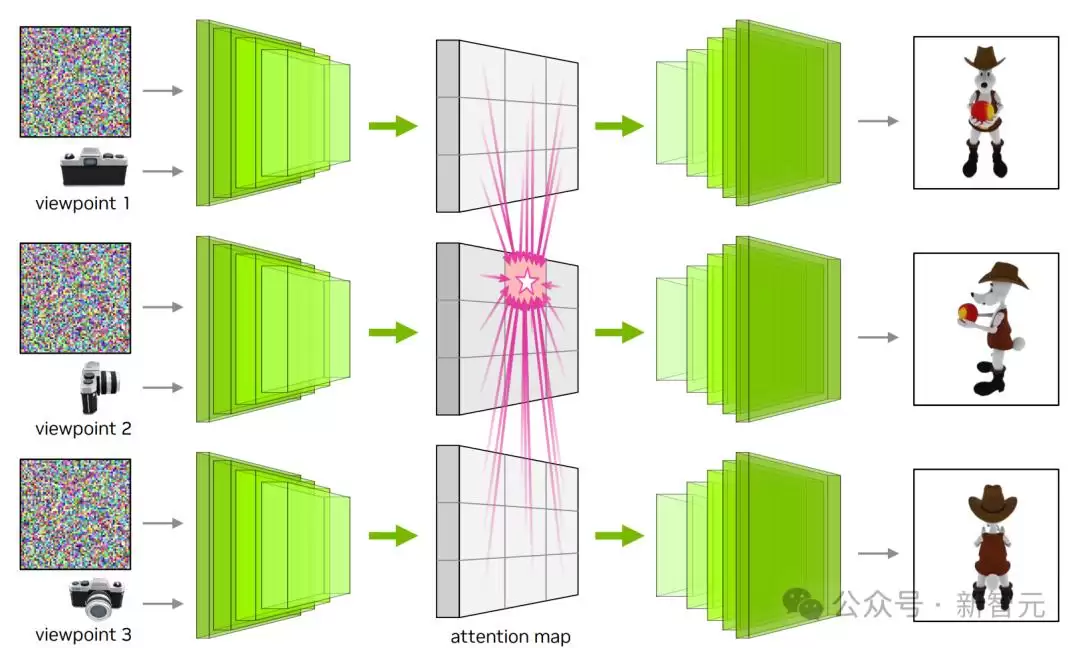
跨视图注意力
在训练阶段,研究者搭建了三个核心模型:
- 多视图扩散模型:根据文本提示和相机姿态,合成RGB外观。
- 多视图ControlNet模型:基于多视图RGB图和文本提示,合成物体的表面法线。
- 多视图上采样控制网络:在给定3D网格的光栅化纹理和表面法线后,把多视图RGB图像超分辨率放大。
研究团队选用了Edify Image模型作为基础扩散模型架构,这是一个拥有27亿参数的U-Net,直接在像素空间里进行扩散。ControlNet编码器则用U-Net的权重进行初始化。他们还用一种新机制,把原始文本到图像扩散模型中的自注意力层扩展了,使之能跨视图进行关注,从而把这个模型当成一个具有相同权重的视频扩散模型来用。相机姿态(旋转和平移)通过一个轻量级MLP编码,然后作为时间嵌入加到视频扩散模型架构中。
整个训练是在3D对象的渲染图上,对文本到图像模型进行微调。训练时,模型会同时处理自然2D图像,以及来自3D对象的随机数量(1、4或8个)视图的渲染图。损失函数和基础模型训练时用的一致。对于多视图ControlNets,研究者先用多视图表面法线图像训练基础模型,然后加入一个以RGB图像为输入的ControlNet编码器,并冻结基础模型进行训练。
关于视图数量扩展的消融研究
训练时,研究者对每个对象抽取1、4或8个视图,并为每个视图分配不同的采样比例。虽然推理时可以采样任意数量的视图,但最好还是让训练视图数与推理时预期的视图数量保持一致,这样能最大限度缩小训练与推理性能之间的差距。
他们专门对比了两个模型:一个主要在4视图图像上训练,另一个在8视图图像上训练。在相同视角下采样10张视图后,结果非常明显:用8视图训练的模型生成的图像更自然,各视图之间的多视图一致性也更好。

使用四个视图的图像训练的模型

使用八个视图的图像训练的模型
重建模型
从图像中提取3D结构,在业内通常被称为摄影测量,是许多3D重建任务的老方法。但这里,研究者使用的是一种基于Transformer的重建模型,把多视图图像转换成3D网格几何、纹理图和材质图。实验表明,这种基于Transformer的模型对未见过的物体图像泛化能力很强,哪怕是2D多视角扩散模型合成出来的数据也适用。
具体来说,研究者用一个仅解码器的Transformer模型,以三平面作为潜在3D表示。输入的RGB和法线图像作为重建模型的条件,在三平面标记和输入条件之间应用了交叉注意力层。这些三平面标记经过MLP处理后,会预测用于签名距离函数(SDF)和PBR属性的神经网络场,用于基于SDF的体积渲染。神经网络SDF通过等值面提取转化为3D网格。PBR属性(包括漫反射颜色、粗糙度和金属通道等)则通过UV映射烘焙到纹理和材质图中。
训练用的数据量很大,包括大规模图像和3D资产数据。重建模型通过基于SDF的体积渲染,在深度、法线、掩码、反射率和材质通道上接受监督,输出由艺术家生成的网格渲染。由于计算表面法线比较耗费资源,所以只在表面计算法线,并对真实情况进行监督。
有意思的是,研究者发现,让SDF的不确定性与其对应的渲染分辨率对齐,能有效提升最终视觉效果。另外,为了平滑样本间的噪声梯度,他们还在损失计算时屏蔽了物体边缘,以避免混叠带来的噪声样本,最后对最终重建模型的权重应用了指数移动平均(EMA)。
重建模型方面的消融研究
实验结果揭示了一个关键规律:重建模型在恢复输入视图方面,始终要比生成新视图更准确。而且,这个模型在视点数量上具有很好的可扩展性——输入的视图越多,性能就越好。
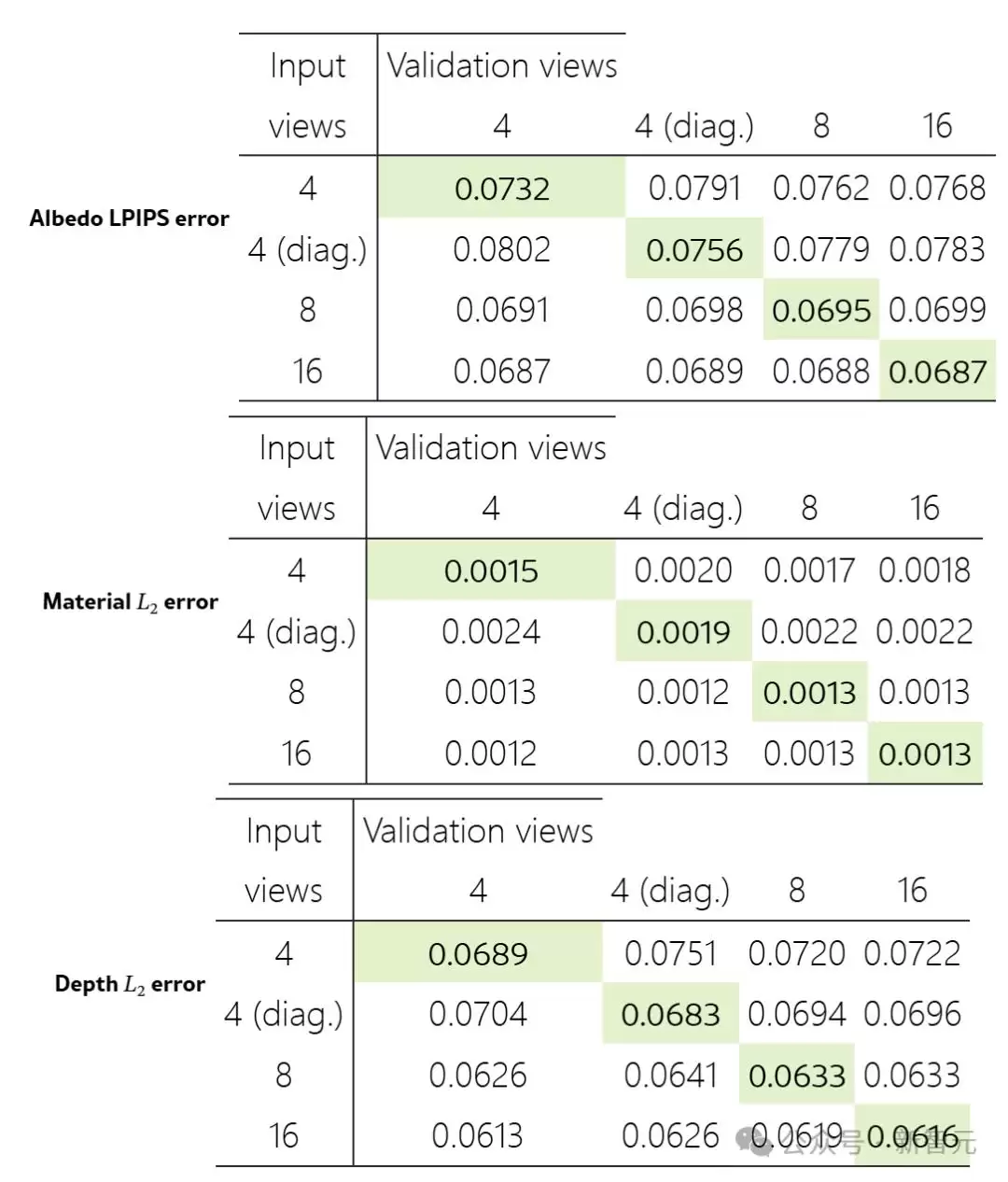
输入视图数量的比较
从图上能清晰地看到,对角线单元格代表的输入视图与验证视图匹配的情况,通常对应着每行最好的结果,说明模型能最准确地复制输入视图。更关键的是,当输入视图数量从4个增加到16个时,结果是持续改善的。这表明,重建模型确实能从更多输入信息中受益,也佐证了Edify 3D重建模型的可扩展性。
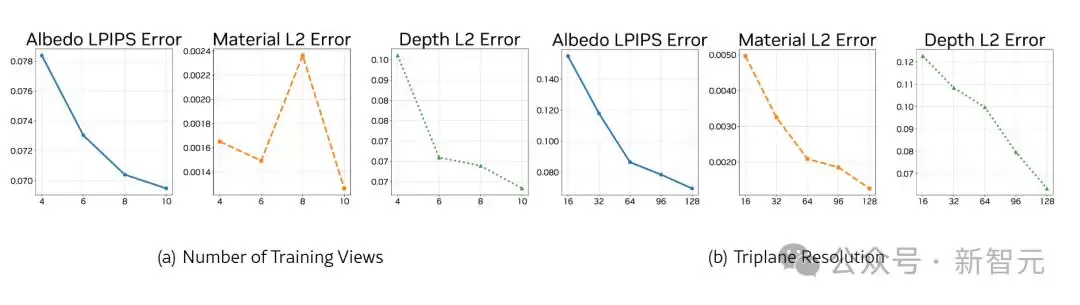
既然模型能随视点数量扩展而提升,研究者进一步追问:训练时的视点数量是否也会影响重建质量?他们用固定的8视图设置进行评估,分别训练了使用4、6、8和10个视图的模型。
结果如图(a)所示。虽然随机采样相机姿态在训练过程中提供了多样化的视图,但随着同一训练步骤中视图数量的增加,重建质量仍然在持续提高。图(b)则对比了标记数量,表明在参数数量固定时,模型需要更多的计算资源来处理更多标记。
数据处理
Edify 3D的训练数据,是一套非公开的大规模组合,包括图像、预渲染的多视图图像和3D形状数据集。原始3D数据在进入模型前,要经过几个关键的预处理步骤,才能达到理想的品质和格式。
第一步,把所有3D图形转换成统一格式:对网格进行三角化处理,打包所有纹理文件,丢弃纹理或材质已损坏的图形,并将材质转换为金属粗糙度格式。经过这一步,用户就能得到一组可以按照意图进行渲染的3D图形。
数据质量筛查是必不可少的一环。研究者从大型3D数据集中,过滤掉非以物体为中心的数据。他们从多个视角渲染形状,再用分类器剔除那些不合适的——比如部分3D扫描、大型场景、形状拼贴,以及包含背景、地平面等辅助结构的形状。为了确保质量,这个过程是通过多轮主动学习来完成的,由人类专家不断制作具有挑战性的示例来完善分类器。此外,还用了基于规则的过滤方法,来去除明显有问题的形状,比如过于单薄或缺乏纹理的。
为了把3D数据渲染成图像,以供给扩散和重建模型训练,研究团队使用自研的光线追踪器进行逼真渲染。在相机参数上,他们采用了多种采样技术:一半的图像以固定的仰角和一致的内参进行渲染,另一半则使用随机的相机姿态和内参。这种方法,既适用于文本到3D的用例,也适用于图像到3D的用例。
而对于3D实体的动作模拟,还需要把模型和真实的实体进行标准姿势对齐。这种对齐也是通过主动学习实现的:团队手动策划少量示例来训练姿势预测器,然后在完整数据集中不断利用困难示例,循环训练直到模型足够稳定。
最后,给3D形状加字幕时,团队为每个形状渲染一张图像,并用视觉语言模型(VLM)生成图像的长句和短句字幕。为了更全面,他们还会把形状的元数据(比如标题、描述、分类树)一并提供给VLM。
结果
在实测中,只需输入文本提示,Edify 3D生成的模型就展现出细节丰富的几何形状和清晰的纹理,反射颜色也分解得很好。这意味着它很适用于各种下游的编辑和渲染应用。

文本到3D生成结果
对于图像到3D的生成,Edify 3D不仅能够准确恢复参考物体的底层3D结构,还能在输入图像中没有直接观察到的表面区域,生成足够详细的纹理。

图像到3D生成结果
最终生成的资产以四边形网格的形式呈现,拓扑结构组织得井井有条。这种结构化的网格方便操作和精确调整,能无缝融入到各种需要视觉真实性和灵活性的3D工作流程中去。

四边形网格拓扑
总的来说,Edify 3D是专为高质量3D资产生成而开发的解决方案。它的研究团队正致力于推进3D资产自动化生成的新工具,让3D内容创作这件事,离更多人越来越近。




