给定一张截图,AI 即可自动生成对应代码——这项技术如今已不再是遥不可及的科幻概念。但在实际应用中,真正的难题从来不是“能否生成”,而是生成的代码是否能真正“运行起来”、“交互可用”、“验证通过”。
传统的“文本生成代码”方法高度依赖自然语言描述,在具体操作场景中往往力不从心——要清晰说明一个界面的空间布局、层级结构和交互逻辑,常常需要数百甚至上千字才能勉强表达清楚。而在前端开发、数据可视化、工业设计等领域,视觉输入反而成为最直观、信息密度最高的方式。随着多模态大语言模型能力的快速迭代,能够同时理解图像、界面、图表乃至动态行为的“多模态代码智能”,正从概念走向实际应用。
围绕这一技术趋势,美团、香港大学、香港中文大学等团队联合发布了一篇最新综述论文,系统梳理了核心任务类型、当前瓶颈与关键挑战,并提出了 4 个值得关注的未来研究方向。

一个令人深思的数据是:以 IWR-Bench 基准为例,模型在视觉层面的复现精度已达 64.25%,但涉及真实用户交互的功能正确率仅为 24.39%。这表明,多模态代码智能的评估不能仅停留在“看起来像”,必须深入语义一致性、结构合规性、运行可执行性与交互鲁棒性等多个维度。
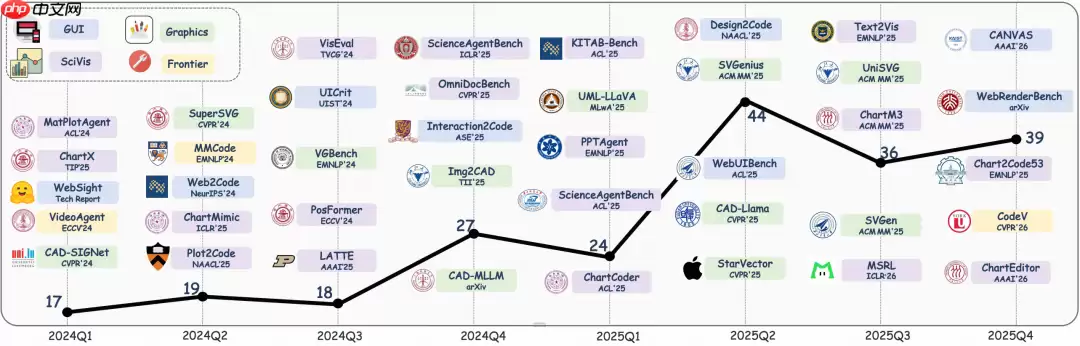
当前进展
在任务建模层面,研究团队将多模态代码智能的工作分为两条主线:
一是多模态驱动的代码合成——在图像、界面截图或图表等视觉信号引导下,完成代码生成、增量编辑与质量精炼;
二是以代码为中枢的推理与行动闭环——将代码本身视为中间表示,支撑推理决策、工具调用和 Agent 自主执行,而不仅是作为最终成果。
基于此,他们将现有研究归纳为四大典型方向:
图|多模态代码智能领域全景概览。
GUI 生成方向:网页端代码生成的验证路径相对清晰(DOM + 行为 + 状态),但当前主流评测仍过度聚焦于静态视觉相似度。IWR-Bench 测试显示,模型视觉保真度已达 64.25%,真实交互功能通过率却仅有 24.39%;移动端则因缺乏统一仿真环境和标准手势协议,评测体系至今难以统一。
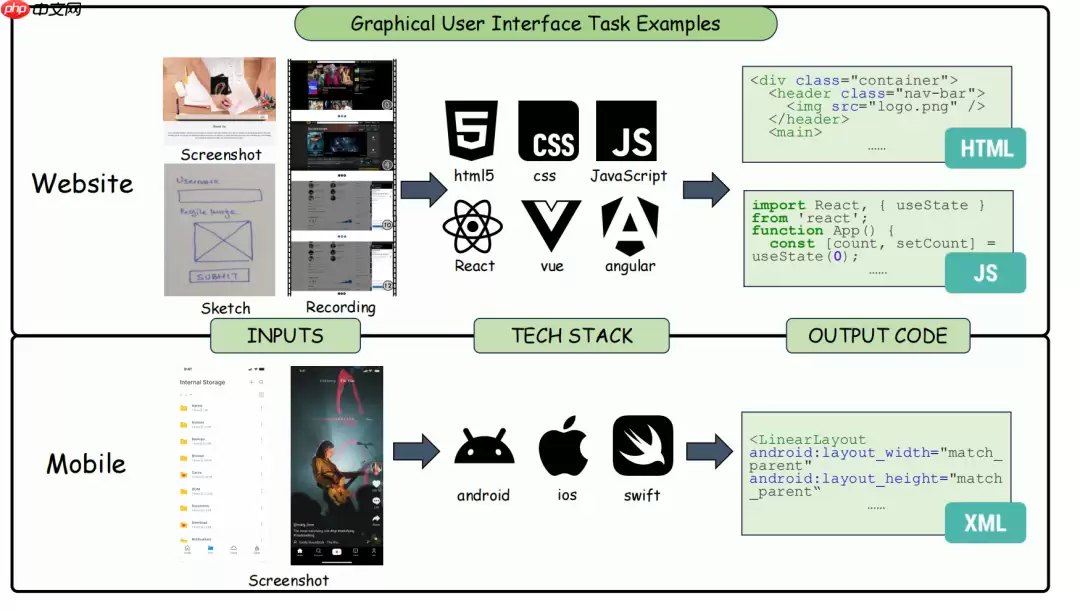
图|网站与移动应用中的 GUI 代码生成任务示例。
科学可视化方向:关键不仅在于图形渲染是否正确,更要求代码准确映射数据语义、文档逻辑、实验流程或学科机制。例如,图表是否反映真实的统计关系,演示文稿是否遵循教学认知顺序,科学动画是否符合物理演化规律。
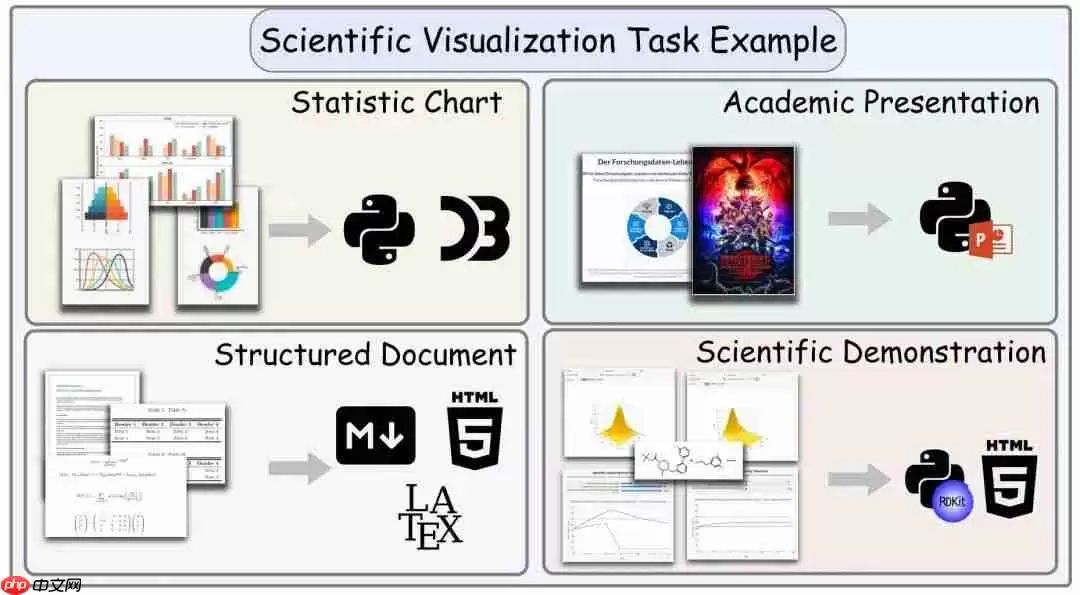
图|科学可视化代码生成任务示例,涵盖图表绘制、学术文档生成、教学演示构建与机制模拟脚本。
结构化图形方向:目标从像素级还原转向结构级保真。SVG 必须保持节点可编辑与样式可继承;流程图须保留控制流拓扑与语义连接类型;CAD 模型则需要重建参数化建模历史、几何约束链与特征依赖关系。
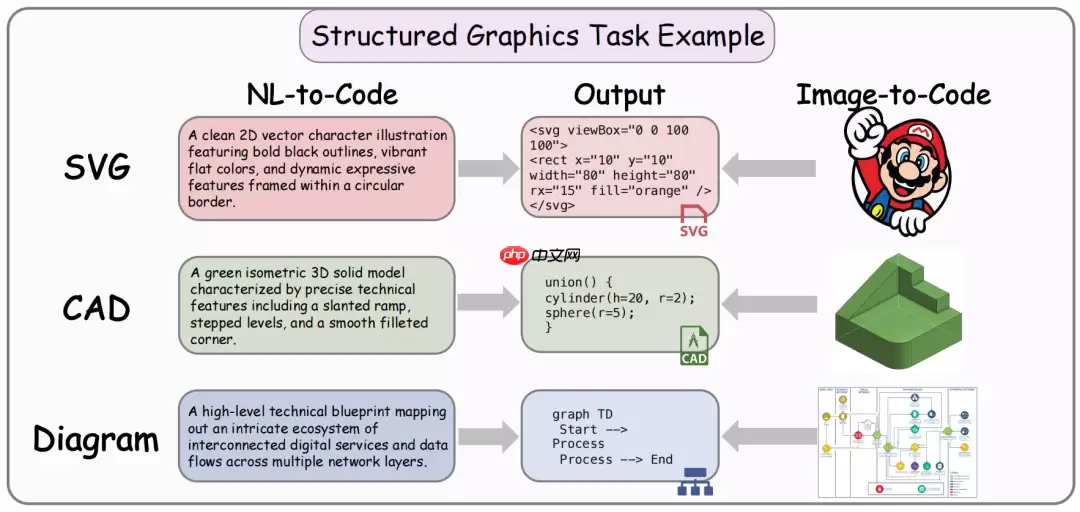
图|结构化图形生成任务示例。
前沿拓展方向:推动代码的角色从“输出结果”升级为“推理载体”与“行动接口”。覆盖程序化图像编辑、视频脚本生成、具身机器人控制、视觉驱动编程交互,以及支持跨模态统一表征的通用代码生成框架。
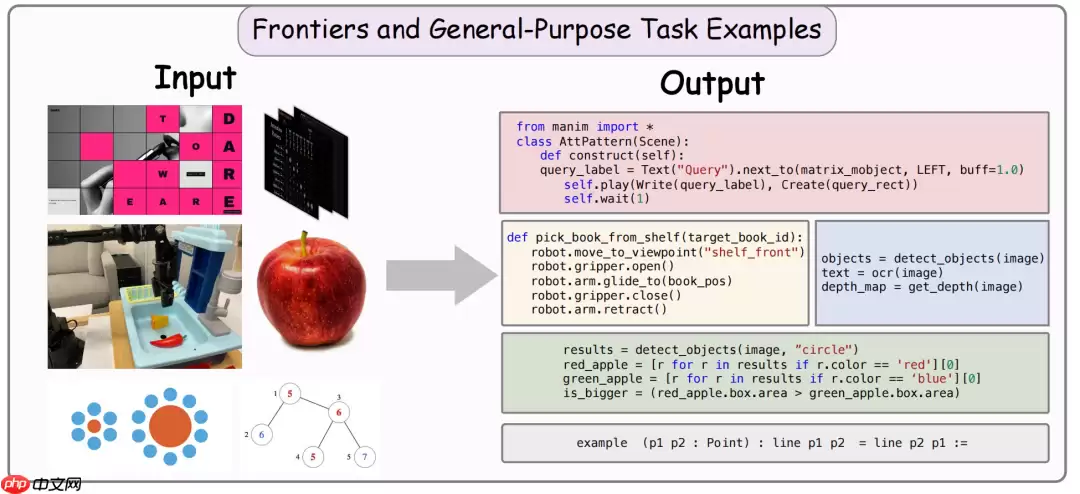
图|前沿任务与统一框架示意图,含程序化视觉操作、视频生成、具身控制、视觉编程交互及多模态统一建模。
未来方向
随着任务边界不断向实时交互、状态演进与物理执行扩展,现有评估范式已难以跟上实际需求。
研究团队提炼了四个关键演进路径:
1. 多信号联合验证
单一指标容易产生误导:高视觉相似度 ≠ 正确的 DOM 结构;低编辑距离 ≠ 可编译运行;偏好打分往往仅捕捉局部风格特征。因此,下一代评估不应只输出一个综合得分,而应生成一份多维诊断报告,分别量化:视觉保真度、运行成功率、文本语法与语义合规性、数据/逻辑保真度、结构有效性、可编辑性、交互响应正确性等。同时,评估设计需明确标注各维度所优化的目标属性、所用验证器类型,并严格区分训练阶段的奖励信号与部署前的可靠性审计。
2. 多状态过程验证
对于涉及状态变迁的任务——如 GUI、科学演示、视频、具身控制——不能再以“静态快照”作为唯一评判依据,必须嵌入完整的执行生命周期检验。例如:一个网页可能初始渲染正确,但在点击按钮、切换路由、响应缩放或更新表单时暴露出状态管理缺陷;一段科学演示代码能运行,却错误呈现了因果机制;视频脚本可能关键帧准确,但事件时序错乱;具身程序或许能抵达终点,却在接触力学、遮挡感知或关节限位条件下失效。
因此,未来基准需覆盖全链路状态轨迹:包括初始观测、生成动作/代码、中间环境反馈、预期状态跃迁、验证器判定结果及异常恢复案例。具体而言:网页任务需断言 DOM 树与 React/Vue 状态;移动任务需结合手势轨迹回放与模拟器传感器反馈;视频任务需进行帧级时序对齐验证;具身任务则依赖物理引擎输出与控制器日志联合诊断。
3. 跨任务迁移能力测试
评估统一多模态模型时,不仅要看它“会多少种任务”,更要检验底层能力是否具备跨任务泛化性。真正的进步不在于“会更多”,而在于是否习得可迁移的通用能力,如空间布局推断、符号关系建模、交互意图识别等。这需要构建标准化的迁移评测协议:对比基线模型、经源任务增强的模型、以及针对目标任务微调的专用模型,同步报告正向迁移增益与负向迁移干扰。例如,验证图表理解训练是否提升了布局解析能力;文档结构学习能否迁移到流程图生成;交互监督信号是否增强了代码修复的鲁棒性。
4. 可审计的 Agent 执行轨迹
面向 Agent 的视觉-代码系统,不能仅以最终成败论英雄。若缺乏过程证据,便无法判断成功源于视觉理解、代码生成、环境执行还是偶然巧合,更难以定位失败根源。研究团队呼吁建立“Agent 证据日志”机制,每条轨迹至少包含:所依据的原始观测(截图/视频帧)、引用的视觉区域坐标或工具返回值、执行的代码修改或动作指令、预期改善的验证器指标、实际回放结果,以及证据不足时触发的回退策略。这样的日志不仅能支撑轨迹回放、模块消融、反事实扰动、权限分级、沙盒隔离与人工复核,还能将故障精准归因到视觉编码、代码生成、环境适配、验证器偏差或动作策略等环节,让多模态 Agent 系统真正摆脱“黑箱依赖”,迈向可追溯、可归因、可干预的新阶段。
一些关键挑战
研究团队指出,当前多模态代码智能的最大制约并非生成能力本身,而是缺乏坚实可靠的验证基础设施。现有评测普遍依赖单一视觉信号,难以覆盖以下情况:
- 网页任务中,单张截图无法验证点击跳转、状态持久化与响应式行为;
- 图表任务中,渲染外观一致并不代表数据映射准确、统计逻辑无误;
- SVG / 流程图 / CAD 任务中,像素接近可能掩盖拓扑断裂、语义错连或参数失配;
- 视频 / 机器人任务中,“任务完成”不等于时序合规、物理可行或安全可控。
此外,数据集构建标准不一、评测指标碎片化、任务定义模糊等问题,导致不同方法间难以进行横向对比;数据泄露、基准过拟合与评测敏感性更是进一步削弱了结论的可信度。
最后需警惕:多模态代码智能虽有望大幅降低视觉编程的门槛,但若验证机制缺位,可能引发一系列现实风险——例如网页交互崩溃、图表数据失真、工程图纸结构错误、科学机制误表达、机器人动作越界等。与此同时,原始截图和设计稿往往包含隐私信息,生成的代码也可能在专有平台上被不当复用或逆向提取。