人工智能(AI)早已不再是科幻小说里的概念。从我们日常使用的手机导航、语音助手,到智能工厂的自动化流水线与物流分拣系统,背后都离不开AI的支持。随着AI技术的日益普及,越来越多基于MCU的产品也开始融入AI世界。过去,AI设计的核心主要依赖CPU、GPU和FPGA这类高性能芯片,MCU似乎与AI毫无关联。那么,MCU与强大的人工智能之间究竟存在怎样的关系?
答案正在发生转变:AI正从云端向边缘侧下沉,过去被忽略的MCU其实大有作为。借助AI计算引擎,MCU突破了传统嵌入式应用的性能瓶颈,不仅能够提升运行效率,还能在物联网设备中更迅速地响应网络攻击、增强系统安全性。这正是关键所在。
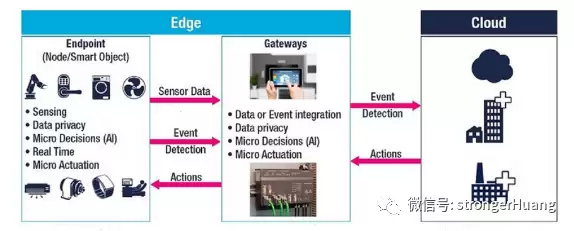
云计算的发展正在推动对具备AI能力的MCU的需求——这类芯片既能减少数据传输所需的带宽,也能节省云服务器的处理资源,见下图:
如今,搭载AI算法的MCU已广泛应用于物体识别、语音服务、自然语言处理等场景。它们还能提升物联网、可穿戴设备与医疗设备中电池供电产品的准确性,同时更有效地保护用户数据隐私。
那么,在边缘和节点设计中具体如何实现AI功能?下面介绍三种基本方法,它们能让MCU在物联网网络边缘高效执行AI加速任务。
三种MCU+AI的实现路径
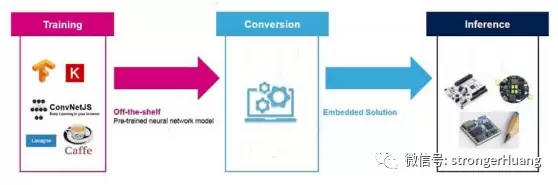
第一种方法(也是当前最普遍的方式)涉及多种神经网络框架的模型转换,例如Caffe 2、TensorFlow Lite和Arm NN。其核心思路很简单:先在云端完成神经网络的训练,再通过专用工具将其转化为针对MCU优化的C代码,最后部署到芯片上运行。工程师可以将这些工具集下载到MCU配置中,直接运行优化后的推理过程。这类AI工具集还提供了基于神经网络的代码示例,覆盖语音识别、视觉处理和异常检测等常见应用。
下图展示了这种模型转换的工作流程——在低成本、低功耗的MCU上运行优化后的神经网络推理:
第二种方法绕开了对云端预训练模型的依赖。设计人员可以直接将AI库集成到微控制器中,把本地AI训练与分析功能嵌入代码。这样一来,基于传感器、麦克风等嵌入式设备采集的实时信号,就能在本地创建数据模型,运行预测性维护、模式识别等应用——全程无需连接云端。
第三种方法借助专用AI协处理器——MCU供应商通过它来加速机器学习功能的部署。例如,Arm Cortex-M33这类协处理器搭配CMSIS-DSP等成熟API,可简化代码移植,让MCU与协处理器紧密协作,大幅提升相关运算与矩阵计算的AI处理速度。同时,新推出的Cortex-M55进一步强化了AI运算能力。
以上软件与硬件方案都表明:通过为嵌入式设计优化的推理引擎,完全可以在低成本MCU上实现AI功能。这一点至关重要——因为支持AI的MCU很可能在物联网、工业、智能建筑和医疗应用中彻底改变嵌入式设备的设计方向。