DeepSeek-R1的横空出世,直接打响了大模型性价比竞赛的第一枪。
有意思的是,国外头部厂商迅速跟进。比DeepSeek-R1晚两周发布的OpenAI o3-mini,定价直接比前代o1-mini砍掉了六成多,相比完整版o1模型更是便宜了超过九成。
国内这边也没闲着。2月13日,百度宣布文心一言将在4月1日全面免费开放——要知道,它之前可是基础版免费、专业版收费的模式,专业版定价59.9元/月,连续包月也得49.9元/月。
这场价格战的背后,远不止是数字游戏。它既是技术实力的硬碰硬,也是对用户市场的重新洗牌。而在这场没有硝烟的商战中,中国算力市场正在经历一场深刻的变革。
最近发布的《2025年中国人工智能计算力发展评估报告》,就把中国算力发展的四大变化,从“幕后”搬到了“台前”。
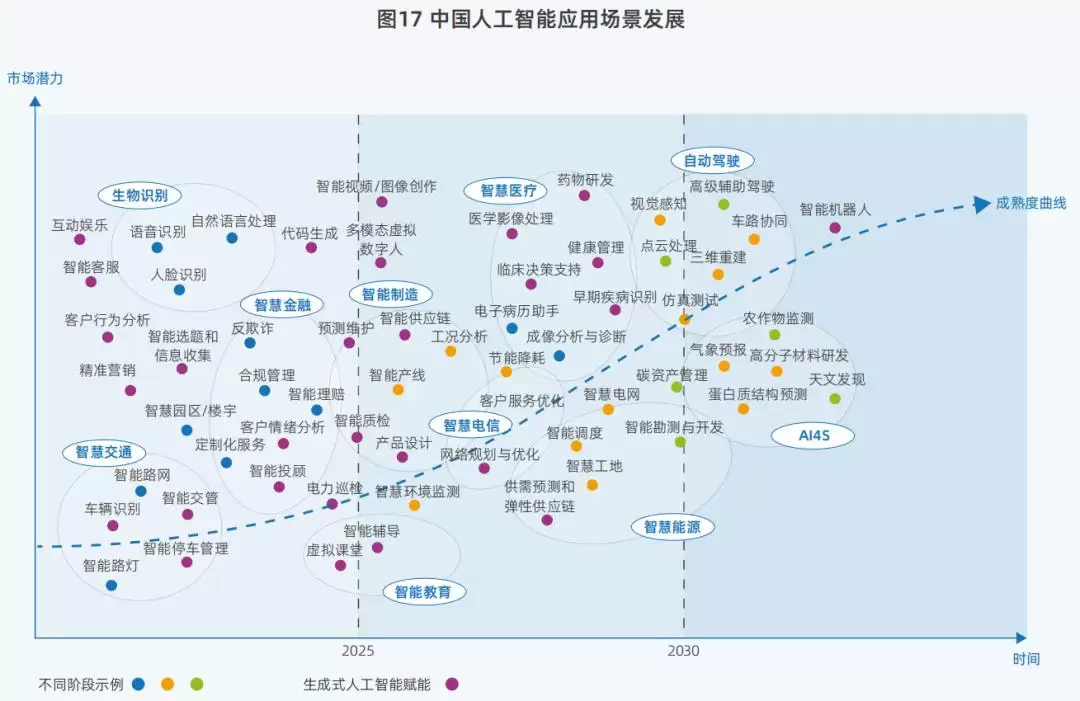
▲中国AI应用场景发展(图源:IDC 2025)
01 算力效率之变:大模型从“大力出奇迹”,转向“四两拨千斤”
第一大变化,体现在算力效率上。DeepSeek通过算法优化,大幅降低了大模型训练和推理对高端GPU的依赖,打破了“算力军备竞赛”的传统路径。
模算效率的显著提升,正是DeepSeek能打出高性价比这张牌的核心因素之一。
DeepSeek的论文显示,R1的训练成本仅557万美元,不足OpenAI同类产品的5%,却在数学竞赛、代码生成等任务中超越了GPT-4。这意味着,用更低的算力成本,也能实现高性能产出。
这里说的“模算效率”,指的是AI模型在训练和推理过程中,衡量模型精度与计算资源利用效率的综合指标。简单来说,就是模型在特定硬件上,用最少的算力消耗实现最高精度的能力。
DeepSeek这种“四两拨千斤”的研发模式,更注重算法创新、架构优化和资源高效利用,很可能会带动整个业界对模算效率的追求。IDC中国副总裁周震刚在接受采访时提到,未来大模型厂商的关注点,将从追求参数量规模,转向追求模型训练、推理、部署等环节的性价比。
此外,DeepSeek使用的MoE(混合专家模型)架构,也实现了更高的成本效益——相比之下,Dense架构在相同参数量下,扩展时的计算成本要高得多。浪潮信息高级副总裁刘军回顾说:“去年开始,大家发现基于Dense架构的模型,再往前演化到五千亿、万亿参数量时,所需的算力、时间、数据量,都是当前技术条件下实现不了的。有企业算过,要训练一个万亿参数的Dense模型,需要20万张卡跑一年。”
因此,MoE在计算成本和模型性能上展现出的优势,大概率会引发一波模仿借鉴的热潮。
目前,企业接入DeepSeek模型主要有两种策略:一是国内大模型厂商、芯片厂商、AI硬件厂商、运营商、AI应用开发商等,纷纷接入DeepSeek的671B满血版;二是有的企业根据自身业务需求,选择参数量较小的模型,或者通过蒸馏技术将DeepSeek模型与自家模型结合,以提升性能、降低成本。
这种多形态、多参数的模型协同发展,才是大模型生态应有的状态。在刘军看来,把DeepSeek-R1的能力蒸馏到小模型上,反而会加速AI技术的扩散。
02 算力结构之变:智能算力市场井喷,推理算力成“香饽饽”
把目光放到整个算力市场,第二大变化同样醒目:国内智能算力规模正在极速扩张,需求结构也在被重塑。
《报告》显示,2024年中国智能算力规模达到725.3EFLOPS,同比增长74.1%,创下近5年来的总量最高峰。这也是近年来扩张速度最快的一次。
对比来看,同期国内通用算力规模仅为71.5EFLOPS,同比增长20.6%。智能算力的增幅,已经是通用算力的3倍以上。
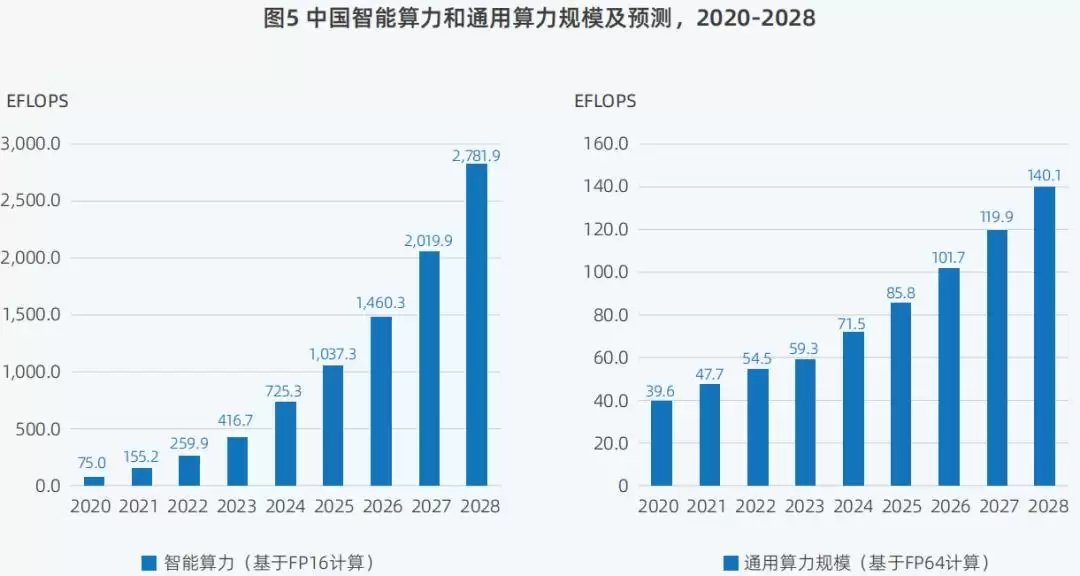
▲2020年至2028年,中国智能算力和通用算力规模及预测(图源:IDC 2025)
这意味着,过去一年里,AI芯片、AI服务器、AI训练、AI推理和AI应用的市场规模都在快速膨胀。比如,2024年中国AI加速计算服务器市场规模达到190亿美元,同比大幅增长86.9%。
尽管业界对大模型的Scaling law是否失效有过争议,但在当下的AI发展进程中,它仍然占据主导地位,这也是推动AI算力需求持续增长的主要原因之一。
《报告》中提到一个有趣的现象:基于杰文斯悖论,DeepSeek实现的算法效率提升,并没有抑制算力需求,反而带动了更多用户和场景,进一步推动了大模型的普及与应用落地。这有助于AI行业重构产业创新范式,并加强数据中心、边缘及端侧算力建设。
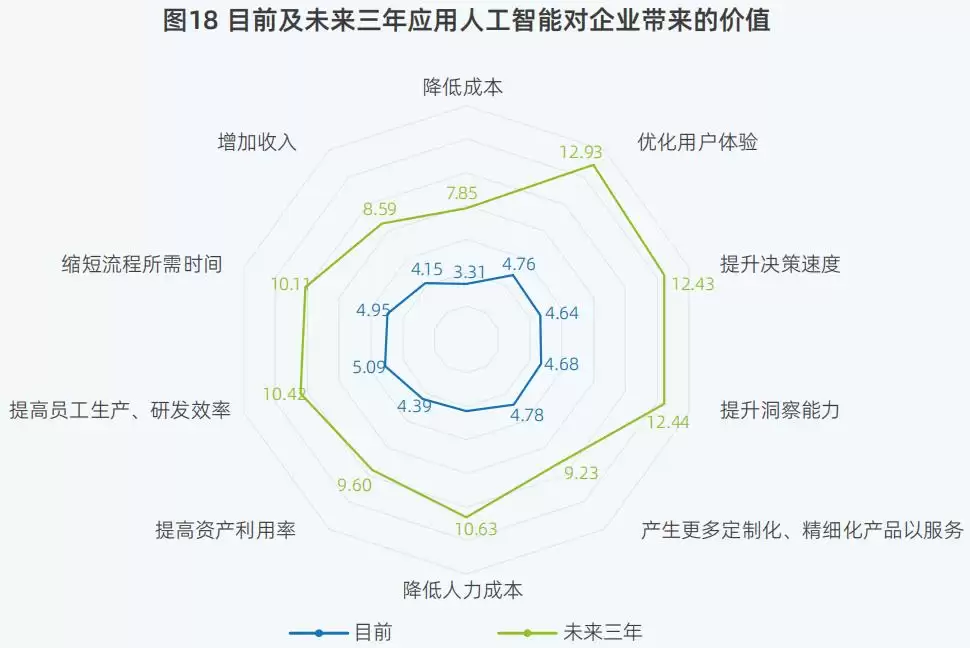
▲目前及未来三年应用AI对企业带来的价值(图源:IDC 2025)
不过,光靠堆叠训练算力并不能一劳永逸。越来越多的大模型厂商开始加速开发多模态能力,并寻找落地场景。多模态模型的应用、AI Agent热潮随之而来,知识管理、对话式应用、内容生成、营销、视频生成等,都成了生成式AI的热门落地场景。
在应用落地侧,这将大幅激发AI推理需求。
像聊天机器人、音视频图像生成、办公场景的AI助手等,在实际应用中都非常依赖推理能力。《报告》预测,后续用于推理的算力规模,将会超过用于训练的算力规模。
全球AI服务器市场中,生成式AI服务器的占比,预计将从2025年的29.6%,提升至2028年的37.7%。
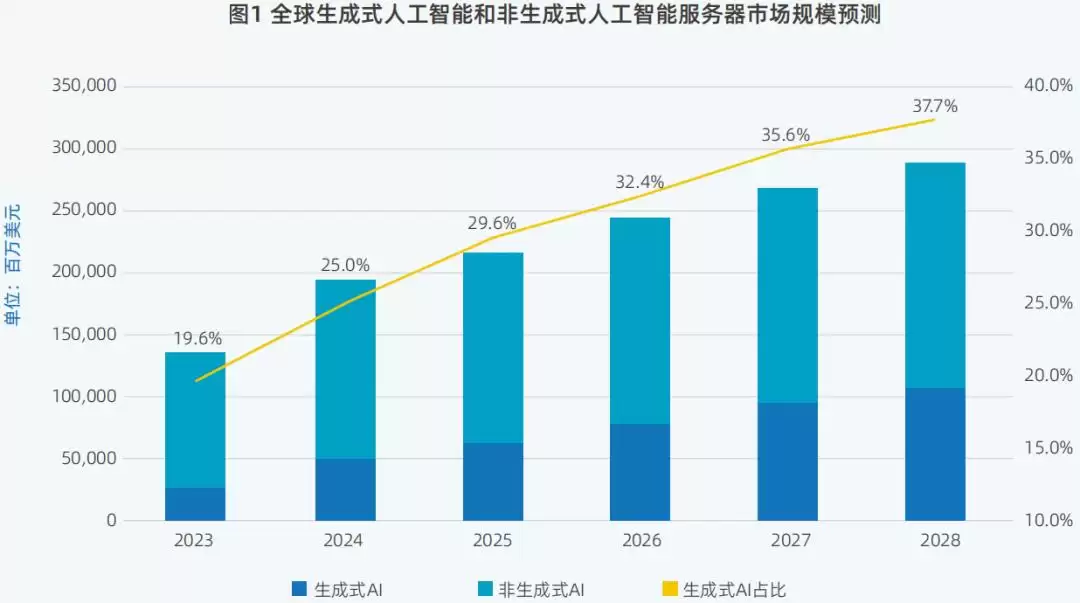
▲2023年至2028年,全球生成式AI和非生成式AI服务器市场规模预测(图源:IDC 2025)
在真实的业务场景中实现“降本增效”,是AI技术发展的关键一环。随着大模型技术逐渐成熟、生成式AI应用不断拓展,推理场景的需求日益增加,推理服务器的占比将大幅提高。IDC数据显示,预计到2028年,推理工作负载占比将达到73%。
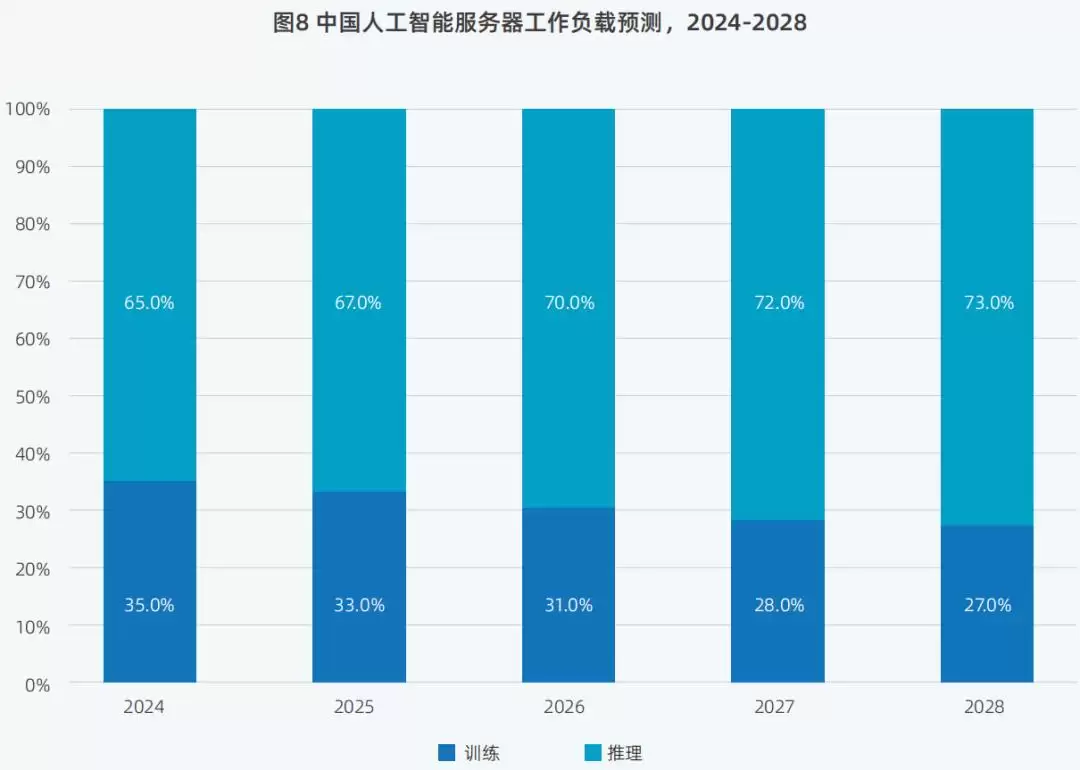
▲2024年至2028年,中国AI服务器工作负载预测(图源:IDC 2025)
这一趋势在浪潮信息的业务中也得到了印证。浪潮信息高级副总裁刘军透露,近期公司接到的订单大部分都是推理算力的,现阶段推理算力的投资回报率高,用户体验也更好,所以规模会大幅提升。
03 算力供应方式之变:算力供应方式多元化,企业AI选择更多了
第三大变化,来自算力供应方式。蛋糕做大了,分蛋糕的人自然也就多了。
去年有一个很明显的市场趋势:一方面,AI算力基础设施的供给结构趋于多元化;另一方面,用户对智能算力基础设施和服务能力的需求,也在发生深刻变化。
在供给端,数据中心服务商、云服务商、硬件厂商和相关AI创企,形成了多点提供AI算力资源的格局。
在需求端,变化集中在两点:
首先,生成式AI将进一步推动企业使用AI就绪的数据中心托管设施、生成式AI服务器集群等智算服务,这能帮企业缩短部署时间,降低资本成本。
IDC数据显示,2024年中国智算服务市场整体规模达到50亿美元;预计2025年将达到79.5亿美元,2028年达到266.9亿美元,2023年至2028年的年复合增长率高达57.3%。
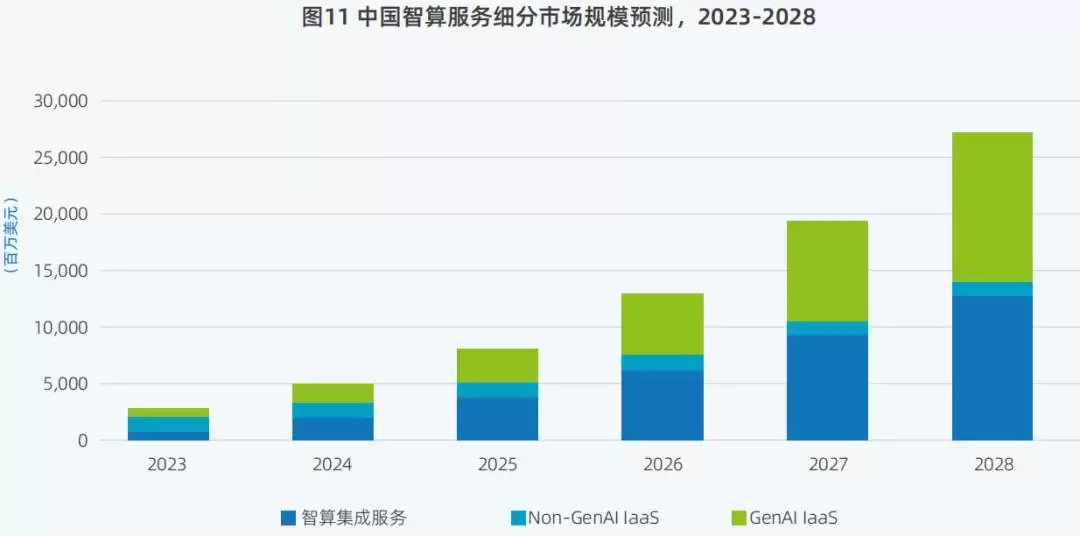
▲2023年至2028年,中国智算服务细分市场规模预测(图源:IDC 2025)
其次,用于推理的一体机也开始受到市场追捧。
IDC中国副总裁周震刚解释,早前企业基于云服务部署AI的案例比较多,用一体机的比较少。但DeepSeek模型爆火后,企业对一体机的需求大幅上升,开始注重私有化部署。
因此,后续一段时间,“开源+一体机”很可能会成为企业AI服务的爆款模式。
据不完全统计,目前市面上至少有60家DeepSeek一体机企业,包括京东云、移动云、联通云等云服务提供商,以及联想、华&为等大厂。通过一体机,企业可以“开箱即用”,快速接入更强大的AI能力。
浪潮信息上周推出的元脑R1推理服务器,就是其中一员。浪潮信息称,该产品通过系统创新和软硬协同优化,单机即可部署运行DeepSeek-R1满血版671B模型。
浪潮信息高级副总裁刘军透露:“最近两个礼拜,来找我们咨询购买能带动满血版DeepSeek-R1模型的AI服务器的客户数,正在直线上升。”
04 城市AI排名之变:京杭沪拿下AI算力全国前三
第四大变化,是城市AI算力排名的洗牌。
《报告》数据显示,国内各城市正通过加大AI投资、吸纳人才、提供政策支持等举措,持续为AI发展提升竞争优势。
在中国各城市的AI算力排行榜上,北京和杭州依然稳居前两位,上海则从2023年的第四位上升至第三位。
这三座城市的AI策略各有侧重:北京聚集了一大批大模型企业,凭借大量人才、成熟企业和有力的政策扶持,持续位居首位;杭州早在2021年就提出要成为具有全球影响力的AI头雁城市,并颁布了多项政策支持;上海的优势在于,正加速推动AI世界级产业集群建设,表现十分出色。
此外,广州、成都、天津、厦门等城市的AI算力排名均有提升。
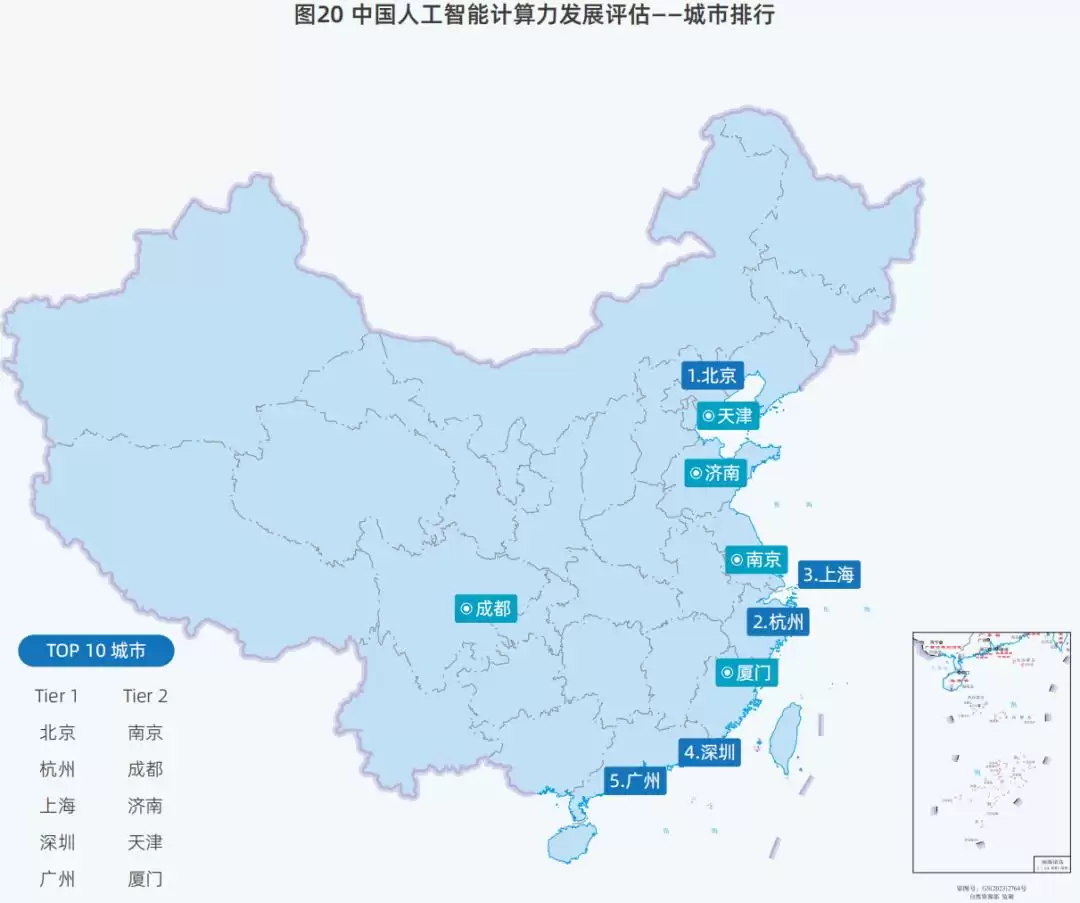
▲中国各城市AI计算力发展评估TOP 10(图源:IDC 2025)
AI的影响下,不同行业的AI应用渗透度排名也发生了变化。
排名第一的是互联网行业,AI原生应用已覆盖问答、写作、客服、路线规划、生活指导、学习助手、角色扮演、视频生产、图片生成、智能客服、智能销售分析等多个场景。
金融行业从2023年的第四名上升至2024年的第二名。制造行业则前进了一位。原因在于,金融行业积累了海量数据,可用于AI训练,为风险评估等提供决策依据;制造业方面,AI驱动的机器人和自动化设备,可以完成重复性高、劳动强度大的工作任务。
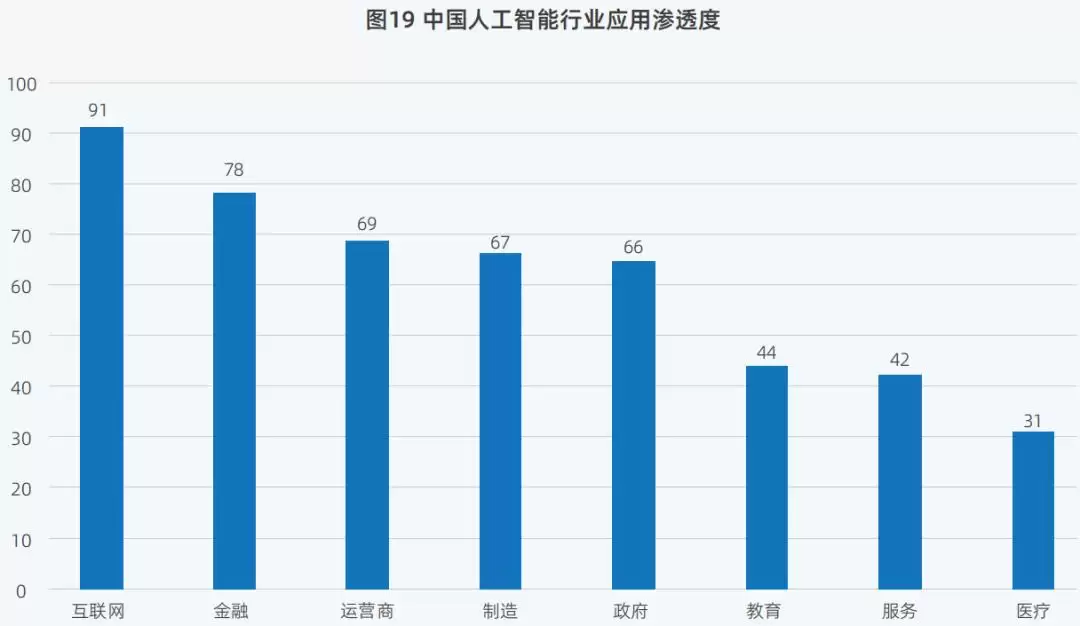
▲中国AI行业应用渗透度(图源:IDC 2025)
05 结语:未来算力发展既要“扩容”,也要“提效”
从这四大变化可以看出,国内算力产业的发展正呈现蓬勃向上的态势。与此同时,更迫切的算力发展挑战也摆在了算力提供商面前:未来,如何持续优化计算架构?如何进一步提升智算中心的算力资源利用率?如何完善数据中心的监控系统和故障恢复机制?这些问题都需要新的解决方案。
针对这些,《报告》提出了解决办法:算力提供商可以根据自身情况,采用“扩容”和“提效”并行的策略来部署AI算力。
扩容,包括增加智算中心的数量和种类,注重区域分布和技术先进性,以加强算力供给能力。
提效,则包括以用定建、以应用为导向规划AI基础设施;提高模型架构效率;优化算力基础设施架构——包括计算架构、内存层次架构、智能调度算法等;同时使用高质量数据集,搭建统一的数据存储和访问接口,以提高算力利用率。
未来,大模型产业的底层技术创新加速、场景应用逐渐铺开,都将为国内算力市场注入新的活力。




