大模型推理性能的提升,真的只能依靠堆叠数据和增加算力吗?李飞飞团队的研究给出了否定的答案——他们仅使用1000个样本就实现了突破。通过微调模型并结合“预算强制”技术,研究团队成功让推理能力随着测试阶段计算量的增加而提升。最终产出的s1-32B模型,在多个推理基准测试中甚至超越了闭源模型OpenAI o1-preview,成为当前样本效率最高的推理模型。
为何OpenAI o系列模型的推理能力如此强悍?官方描述为“大规模强化学习”,暗示其背后依赖海量数据。DeepSeek-R1也采用了类似路径,使用数百万样本与多阶段强化学习训练,达到了o1级别的性能。然而,目前还没有人能够公开复现出清晰的测试时扩展行为。
那么,实现测试时扩展与强推理能力,是否存在更简洁的方法?
答案是肯定的。来自斯坦福大学、华盛顿大学和Ai2等机构的研究人员,在一篇题为“s1: Simple test-time scaling”的论文中回答了这个问题。

研究团队通过实验证明:仅使用1000个样本进行下一个token预测训练,并在测试阶段借助“预算强制”技术来控制推理深度,就能得到一个具备可扩展性的推理模型。其核心思路非常直接:强制提前结束模型的思考过程,或通过反复添加“Wait”来延长思考时长,从而影响推理深度和最终输出质量。这种方法能够引导模型进行自我检查与错误修正,显著提升推理性能。
在具体实施上,他们构建了一个名为“s1K”的数据集,包含1000个经过精心筛选的问题,每个问题都配有从Gemini Thinking Experimental模型中蒸馏得来的推理轨迹与答案。随后,研究团队在一个预训练模型上进行了监督微调,仅使用16张H100 GPU,耗时26分钟完成训练。训练完成后,再通过“预算强制”技术来控制测试阶段的计算资源分配:
- 如果模型生成的推理token超出预设上限,就强制终止推理过程,随后附加“思考结束”token,引导模型进入答案生成阶段。
- 如果希望模型投入更多计算,就抑制“思考结束”token的生成,并在推理轨迹中追加“Wait”,鼓励它进行更深入的反思。
基于这一简洁方案——1000个样本的监督微调与测试时的预算强制——s1-32B模型展现出了清晰的测试时扩展能力。
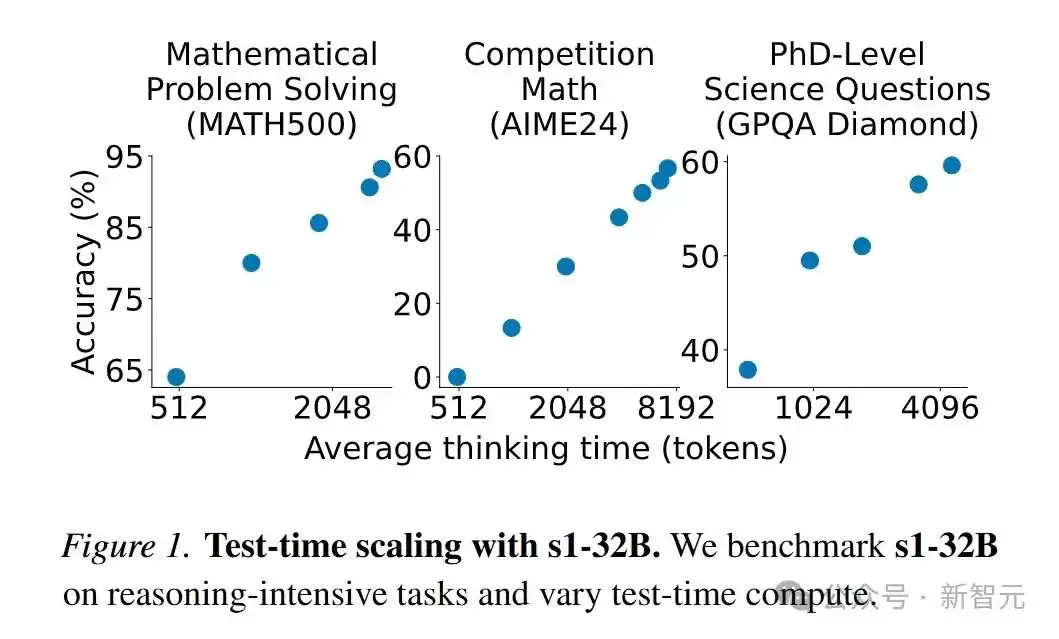
不仅如此,s1-32B在推理能力上超越了OpenAI的o1-preview等闭源模型,成为了当前最具样本效率的推理模型。
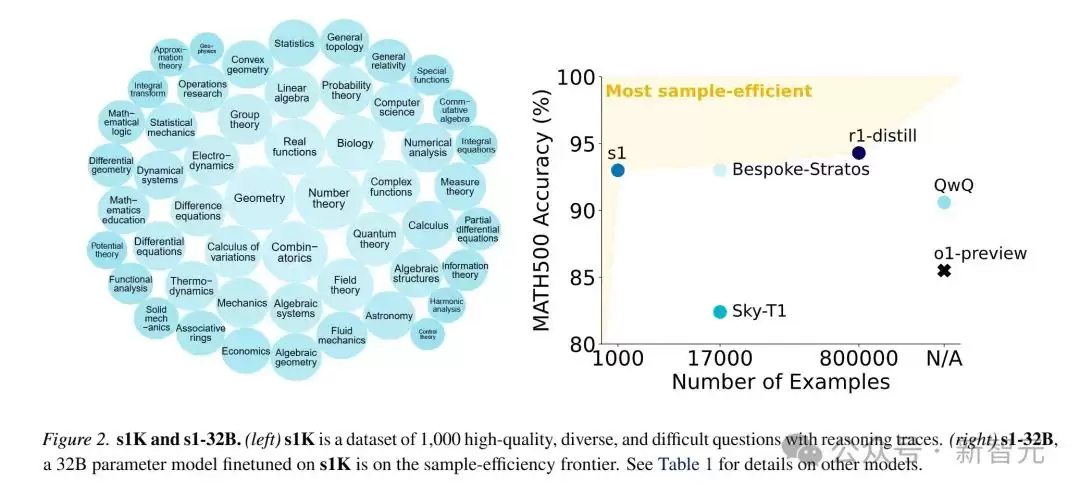
如何创建s1K数据集
s1K数据集包含1000个高质量推理问题,其创建过程分为两个阶段。
第一阶段:收集与初筛。 研究人员从16个不同来源收集了59029个问题,遵循质量、难度和多样性三个核心原则。数据来源包括现有数学数据集以及自建的概率问题集与脑筋急转弯问题集。为确保质量,所有样本都经过逐一检查,并剔除了格式不佳的数据;为增加难度,优先选择需要大量推理努力的问题;为保证多样性,涵盖了多个领域和推理任务类型。
第二阶段:最终筛选。 通过三层过滤机制,从59029个样本中筛选出1000个关键样本,继续依赖质量、难度和多样性原则。最终得到的s1K数据集包含覆盖50个不同领域的1000个高质量、高难度且多样化的问题,并附带完整的推理过程。这个数据集是训练s1-32B模型的核心基础。
测试时扩展方法
核心思想是在测试阶段通过增加计算量来提升语言模型性能。论文将测试时扩展方法分为两类:顺序扩展与并行扩展。顺序扩展是指后面的计算依赖前面的计算,例如需要长期推理的任务;并行扩展则是独立运行的计算,例如多数投票法。论文主要聚焦于顺序扩展,因为它能更好地利用中间结果进行深层次推理和迭代改进。
预算强制 通过限制模型在测试阶段使用的最大和/或最小思考token数量来控制计算量。实验证明,这一简洁方法能有效引导模型修正答案。
例如,在下面的例子中:模型最初回答“raspberry中r的数量”时给出了错误答案“2”。但通过抑制“结束思考”token并追加“Wait”,模型最终意识到是因为快速阅读导致的错误,并给出了正确答案“3”。

测试时扩展方法
实验结果显示,s1-32B模型在使用预算强制技术后,性能随着测试阶段计算量的增加而稳步提升。
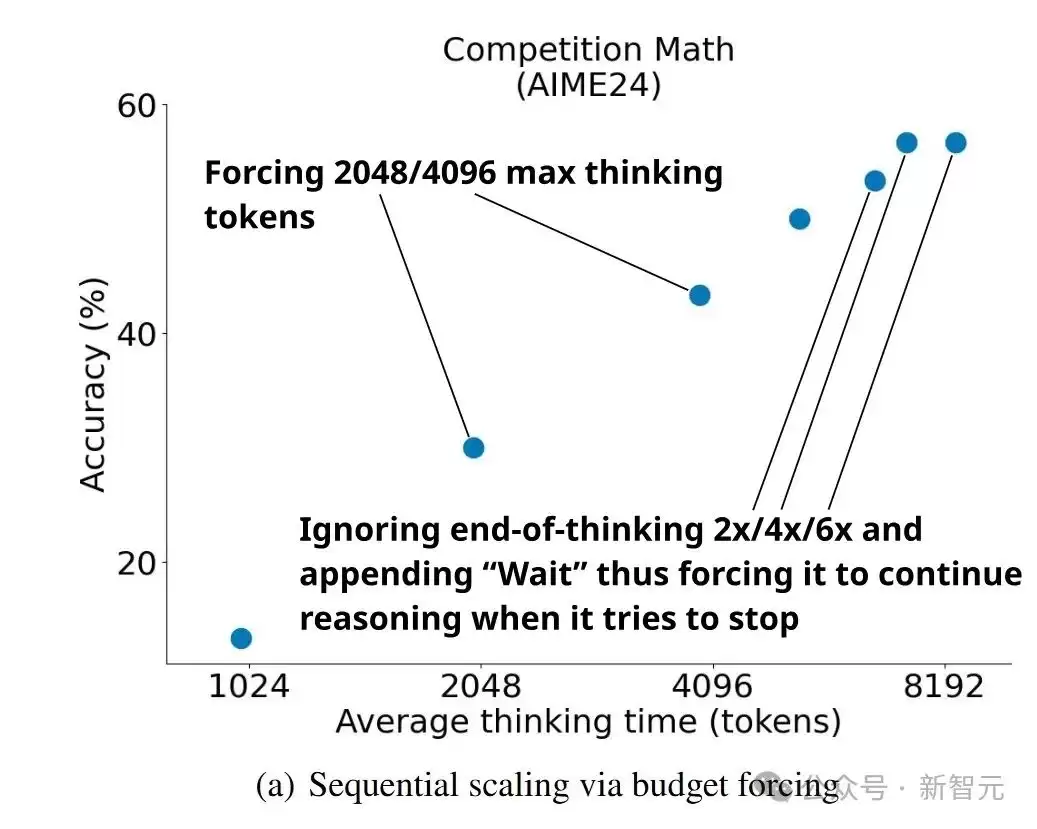
具体来说,通过增加模型思考的token数量(例如追加“Wait”),模型在AIME24基准上的表现持续提升。不过这种提升最终会趋于平缓,过度抑制“结束思考”token会导致生成陷入重复循环。
s1-32B是当前样本效率最高的开源推理模型。尽管只使用了1000个样本进行微调,其性能仍显著优于基础模型Qwen2.5-32B-Instruct。与DeepSeek r1-32B模型相比,虽然后者性能更强,但使用了800倍于s1-32B的训练样本。此外,s1-32B在AIME24上的表现几乎与Gemini 2.0 Thinking API持平,证明其蒸馏过程是有效的。
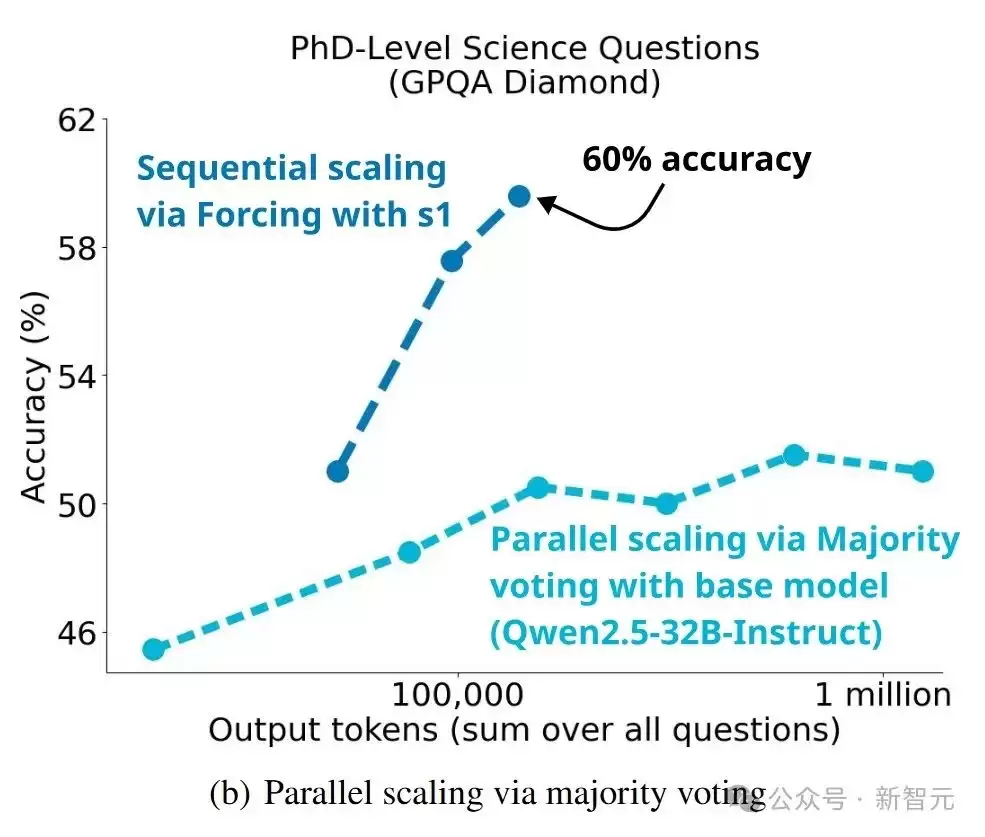
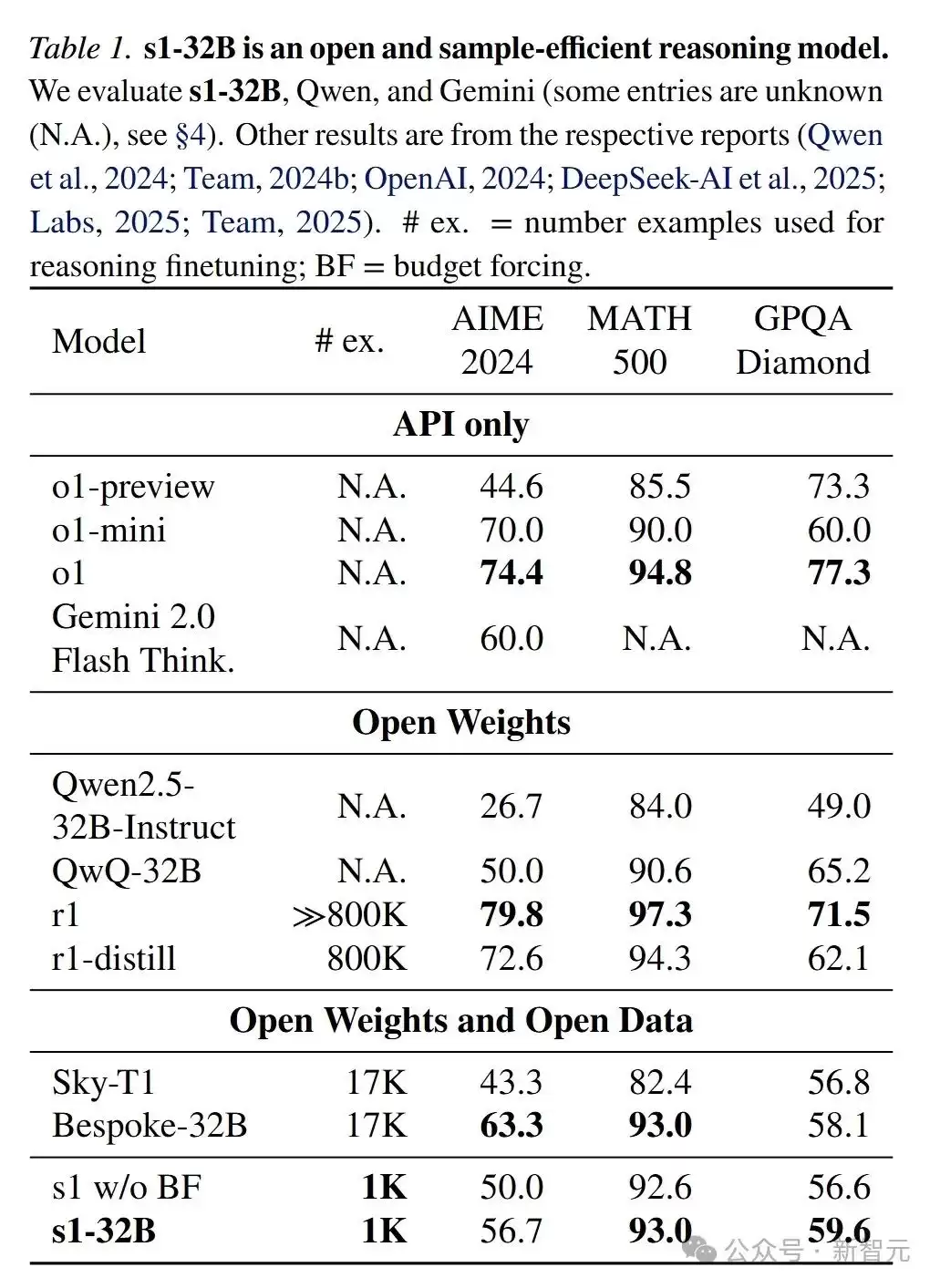
总之,s1-32B在测试时扩展、样本效率和推理能力方面优势明显,验证了预算强制技术的有效性。
消融实验
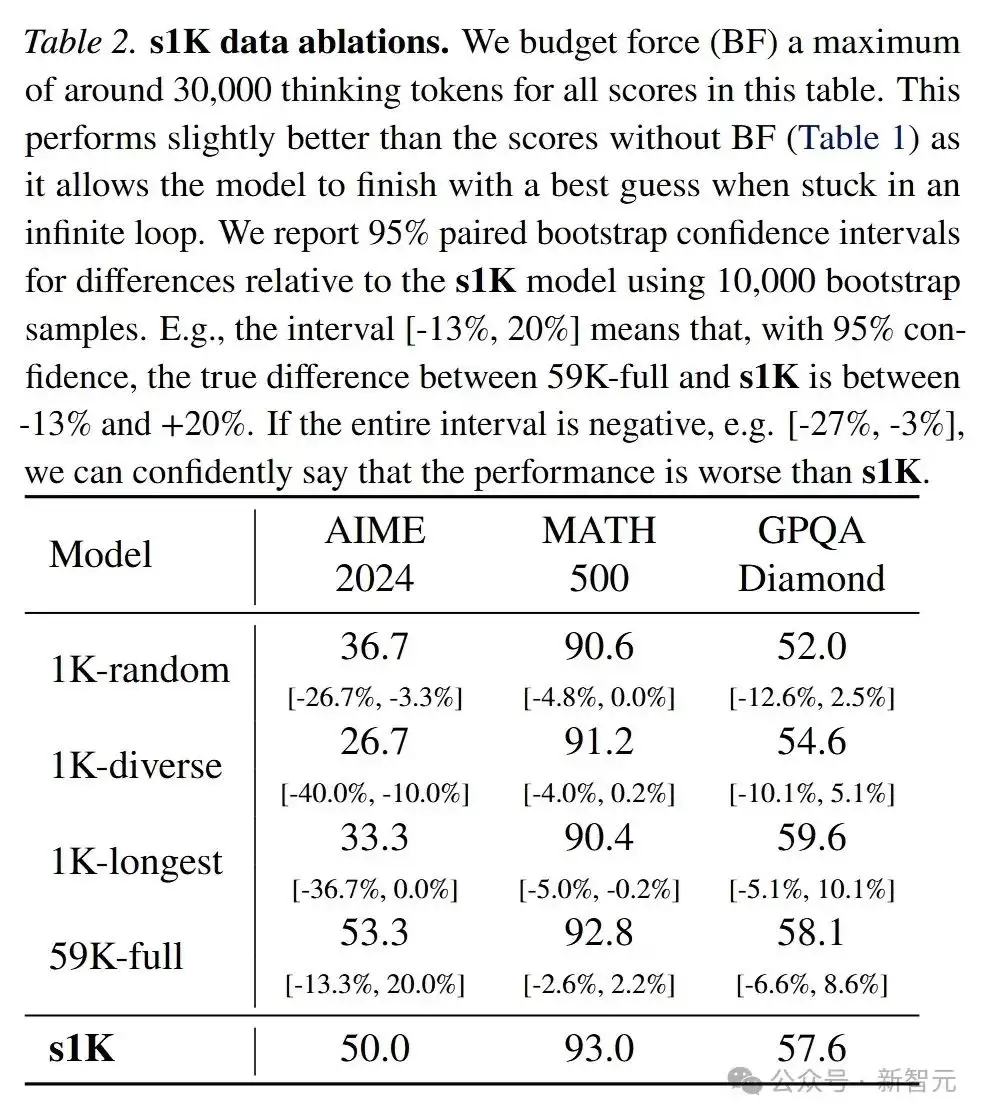
数据消融实验 验证了质量、多样性和难度三个标准的关键作用:
- 仅质量 (1K-random):随机选取1000个高质量样本,性能明显不如s1K,说明难度和多样性过滤至关重要。
- 仅多样性 (1K-diverse):均匀选取各领域样本,性能远不及s1K,表明仅有多样性是不够的。
- 仅难度 (1K-longest):选取推理轨迹最长的1000个样本,在GPQA上虽有所提升,但整体不如s1K,说明难度仅是因素之一。
- 最大化数据量 (59K-full):使用全部59029个样本训练,性能略有提升,但训练成本巨大,表明精心挑选的少量数据比海量数据更高效。
结果表明,质量、难度和多样性三者结合,是实现样本高效推理训练的关键。
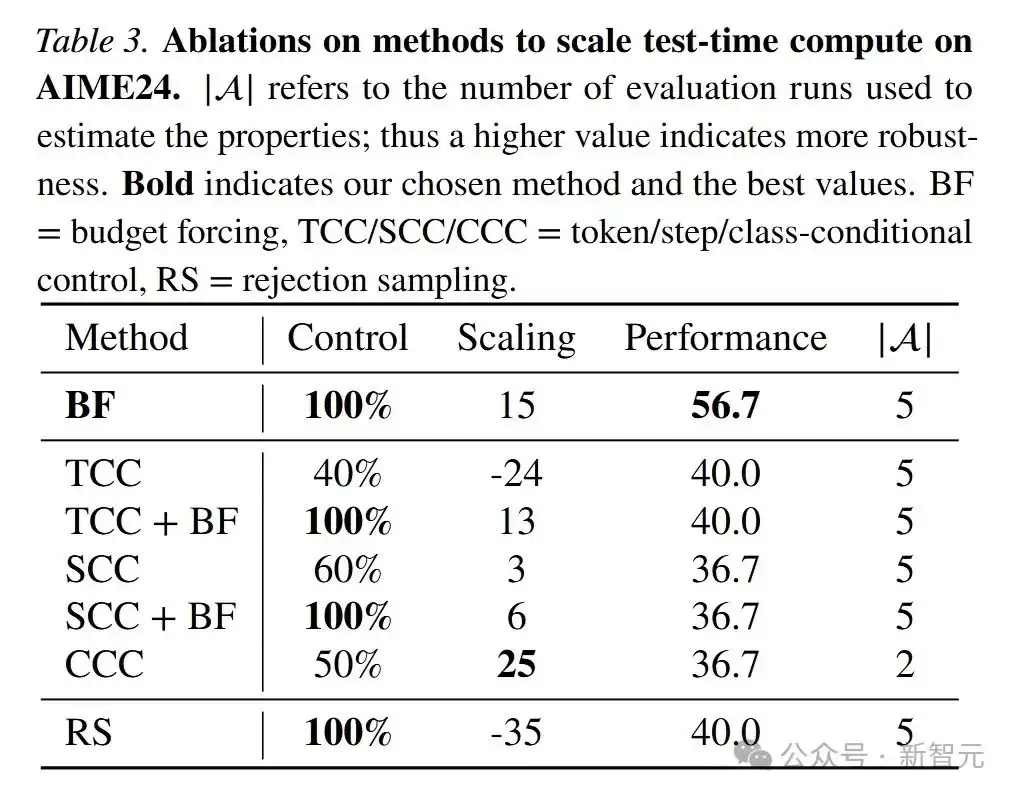
测试时扩展方法消融实验 验证了预算强制技术的优越性:
- Token/步骤/类别条件控制 (TCC/SCC/CCC):这些方法均无法有效控制计算量或获得良好的扩展效果,说明仅在提示中告知计算量或步骤数量是不够的。
- 拒绝采样 (RS):会导致性能随计算量增加而下降,因为更短的生成通常是模型初始推理就正确的结果。
- 预算强制 (BF):在可控性、扩展性和性能方面都优于其他方法。追加“Wait”能鼓励模型进行额外思考,从而提升性能。
下图展示了在AIME24上使用s1-32B模型进行拒绝采样的结果:随着平均思考时间增加,准确率反而下降,呈现出反向扩展趋势。
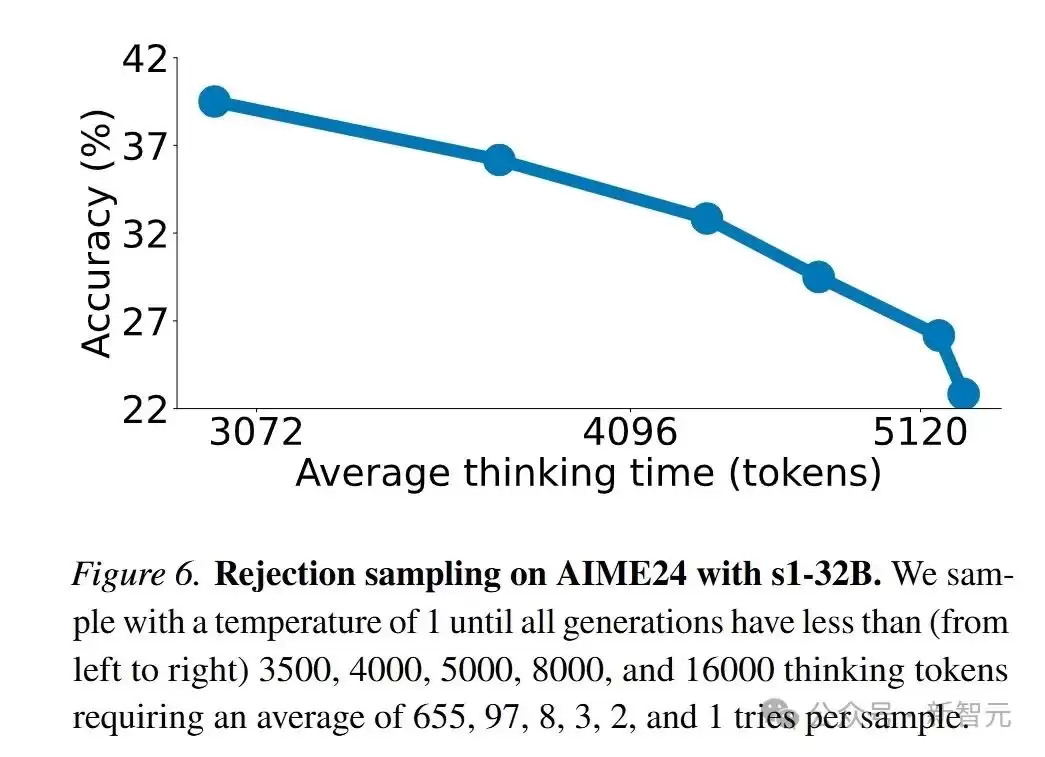
这说明更长的推理过程并不总能带来更好的性能,同时也反衬出预算强制方法的优越性——因为它能够更有效地控制测试阶段的计算量,促使模型进行更有目的性的思考。实验结果表明,预算强制是测试时扩展的最佳方法。
总结
尽管DeepSeek-r1和k1.5等模型通过强化学习或数万个蒸馏样本来构建强大的推理模型,但本研究证明:仅需1000个样本进行监督微调,就足以构建一个能与OpenAI o1-preview相媲美的推理模型。
研究团队认为,预训练阶段模型已经接触了大量的推理数据,因此微调阶段只需少量样本就能“激活”其推理能力——这与LIMA论文提出的“对齐假说”类似。
预算强制是一种简单且有效的顺序扩展方法,通过控制模型思考token数量来提升性能,并且首次复现了OpenAI的测试时扩展曲线。尽管存在局限性,但它证明了测试时扩展的巨大潜力,并为未来研究提供了明确的评估指标:可控性、扩展性和性能。
为克服顺序扩展的局限性,论文还探讨了并行扩展方法,如多数投票和基于REBASE的树搜索。将顺序扩展与并行扩展相结合,有望进一步扩展测试阶段的计算量。
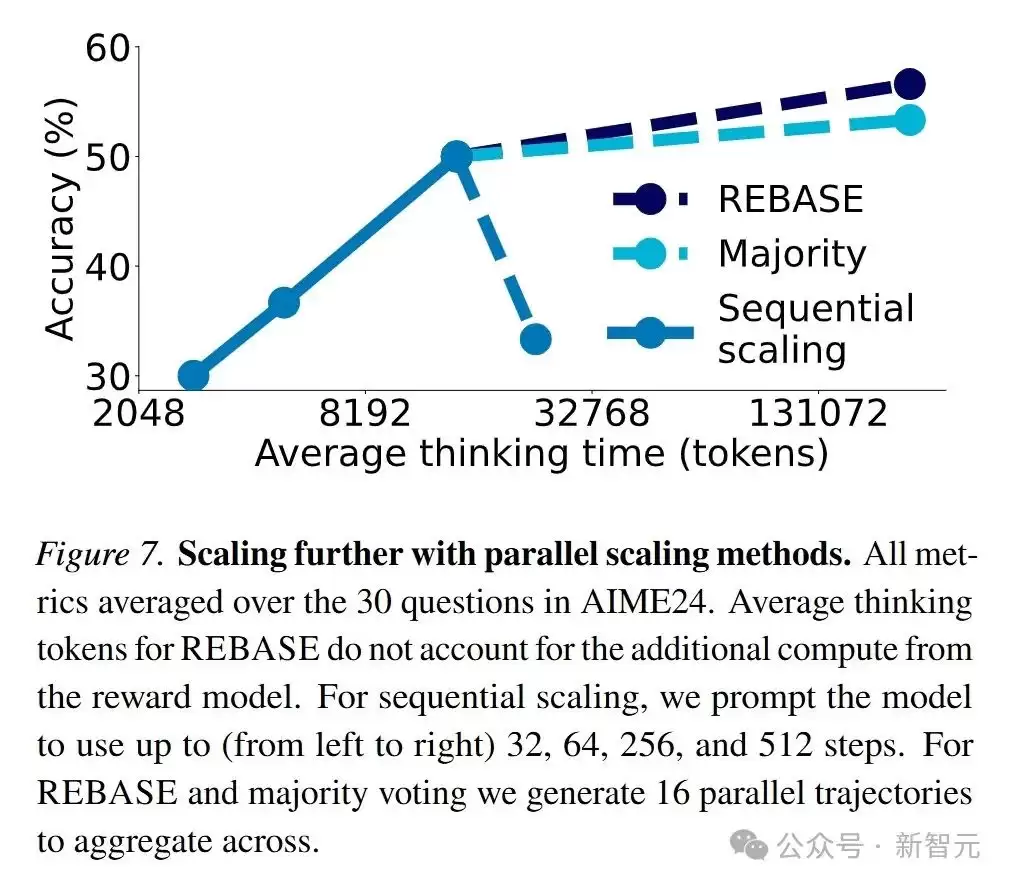
未来方向
论文指出,未来可以探索如何进一步改进预算强制,例如轮换使用不同的提示字符串或结合频率惩罚。一个很有前景的方向是将预算强制应用于通过强化学习训练的推理模型,并研究新的测试时扩展方法。此外,还可以探索如何进一步扩展测试阶段的计算量,以克服现有语言模型上下文窗口的限制。




