DeepSeek近期动作密集,产品迭代与技术开源两条线同步加速推进。V4正式版已确认将于7月中旬上线,届时API将启用峰谷定价机制,高峰时段价格直接翻倍。与此同时,与北京大学联合推出的推理加速框架DSpark已全量部署至线上服务,单用户生成速度最高提升85%。这两项举措联合释放的信号十分明确:DeepSeek正在同步推进商业化压力管理与技术能力兑现。
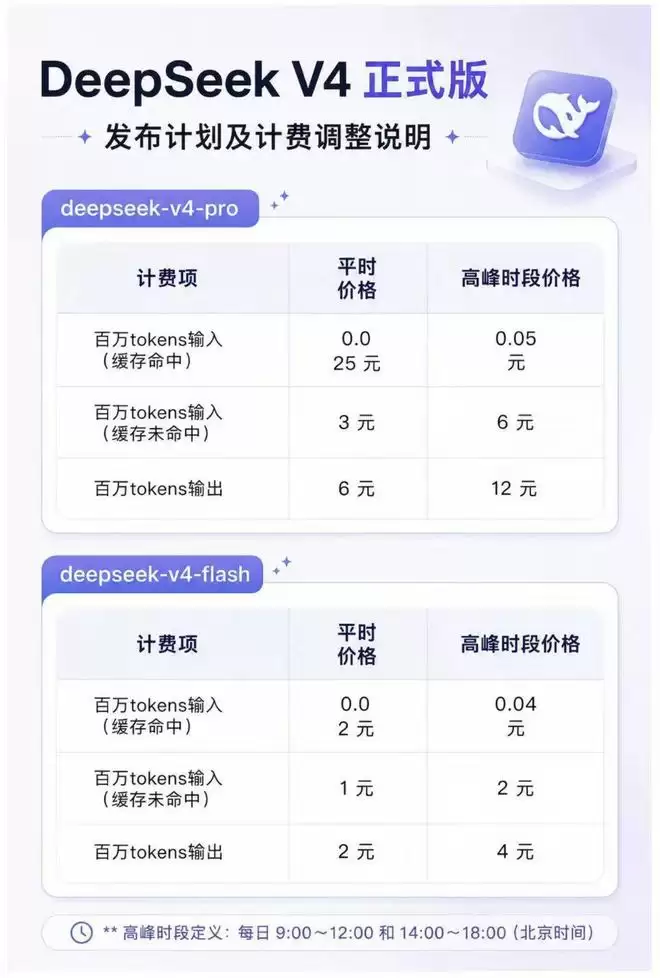
6月29日,DeepSeek团队正式宣布V4正式版将于7月中旬发布,同步上线的还有峰谷定价策略。根据公布的价格表,高峰时段API价格为平时的两倍,平时价格则与现行V4 API价格保持一致。高峰时段具体定义为:每天上午9点至12点、下午2点至6点。公司方面解释,此举有助于更合理配置资源,提升服务稳定性。
技术层面同样有重量级动作。6月27日,DeepSeek联合北京大学发布了推理加速框架DSpark,并将全栈推测性解码工具链DeepSpec同步开源。论文由创始人梁文锋本人署名,已上传至公开代码库。实测数据表现亮眼:部署DSpark后,V4-Flash单用户生成速度提升了60%至85%,V4-Pro提升了57%至78%,效果已在线上服务全量验证。这也是DeepSeek完成500亿元融资后,首次对外发布的开源技术成果。
对于API用户而言,峰谷定价意味着工作时段使用成本将明显上升;而对开发者来说,推理速度的显著提升或许能在高并发场景下部分对冲成本压力,同时也进一步降低了推理优化的落地门槛。
V4正式版发布与峰谷定价机制解读
DeepSeek V4模型的预览版于4月24日上线并同步开源,拥有百万字超长上下文,在Agent能力、世界知识和推理性能上均处于国内及开源领域领先位置。正式版计划7月中旬推出,预计将进一步优化功能并提升性能。
V4系列本次分为两个规格:旗舰版V4-Pro总参数达1.6万亿,激活参数49B,预训练数据量33T,支持1M上下文,网页端以专家模式运行;轻量版V4-Flash总参数284B,激活参数13B,预训练数据32T,同样支持1M上下文,网页端以快速模式运行。两款模型均已开源并提供API服务。

峰谷定价是本次正式版更新的另一核心变量。它将每日API使用成本切分为两个层级,平时价格维持现行水平不变,高峰时段收费翻倍。对于在工作时段密集调用API的企业用户来说,成本影响相当直接;而那些有条件将批量任务迁移至低峰时段运行的用户,则可在定价调整后维持原有成本水平。
DSpark:推测性解码技术的工程化落地
DSpark并非全新架构的模型,而是在现有V4模型基础上引入推测性解码模块,核心聚焦于工程层面的优化落地。推测性解码的基本逻辑直观清晰:先由轻量级小模型快速生成候选token(类似于草稿),再由大模型并行验证,接受符合目标分布的连续前缀,从而在不损失生成质量的前提下实现显著提速。

DSpark针对该技术在实际落地中面临的两大核心瓶颈,分别给出了针对性解决方案。
第一个瓶颈是半自回归生成架构,主要解决并行草稿的“后缀衰减”问题——当并行独立生成各位置token时,位置间缺乏依赖约束,越往后错误累积越严重,验证接受率会断崖式下跌。DSpark采用“并行主干+轻量串行头”的两阶段设计:并行主干保留速度优势,串行模块则补充相邻token间的依赖关系,修正语义冲突,直接提升每轮验证的有效接受长度。测试结果显示,2层深度的DSpark有效接受长度甚至超过了5层深度的纯并行方案DFlash。
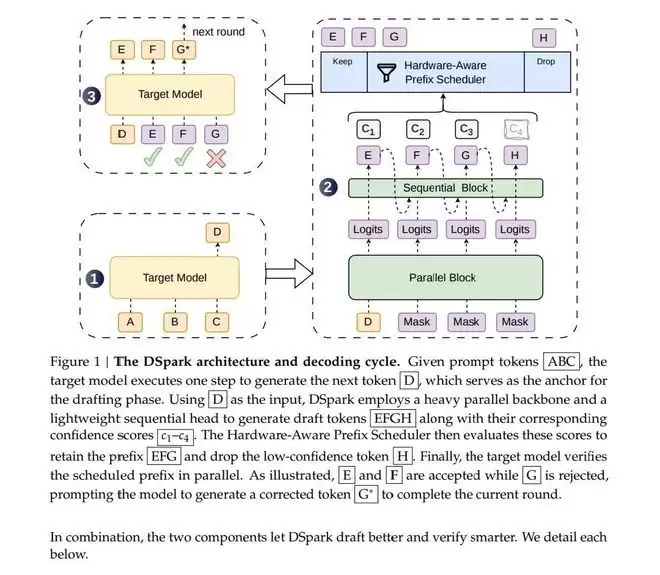
第二个瓶颈是置信度调度验证机制,主要针对全量验证导致的算力浪费问题。DSpark在草稿模型上增加了置信度评分模块,实时预测每个候选token的条件接受概率,并通过“顺序温度缩放”校准方法将评分误差从3%-8%压缩至约1%。在此基础上,调度器根据实时负载动态调整验证长度:低并发时拉满算力,高并发时主动裁剪低价值token,避免资源争抢和速度骤降。




