“AI 编程的核心挑战,正从代码生成逐步转向工程交付。”
作者丨宇景
编辑丨马晓宁 李娜
过去一年里,AI 编程工具早已突破简单“代码补全”的范畴。从 Cursor 到 Claude Code,模型被直接集成进 IDE 和命令行,国内厂商也迅速跟进。竞争的逻辑随之转变——模型能写几段代码已不足以体现优势,能否陪伴开发者完整跑完一个项目,才是新的入场资格。
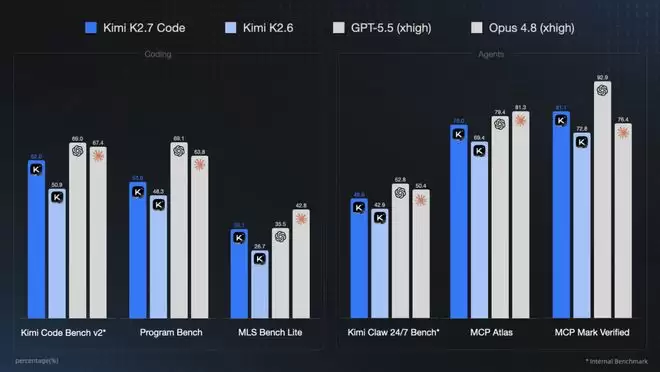
Kimi K2.7 Code 正是在这一节点发布的。月之暗面将其定位为面向长上下文、复杂编码任务和 Agent 工作流的 Coding 模型。根据最新公布的基准结果,K2.7 Code 相比 K2.6 在所有任务上均有提升,长程任务的平均 token 消耗大约降低了 30%。
然而更值得关注的是它与头部模型之间的位置对比:在三个 Coding 类基准上,K2.7 Code 仍落后于 GPT-5.5 和 Opus 4.8;但在三个 Agent 类基准上,它与 Opus 4.8 已十分接近,甚至在 MCP Mark Verified 上实现了反超(81.1 对比 76.4)。这一分布态势,清晰揭示了 Kimi 团队资源投放的重点——优先将 Agent 工作流这条线拉平至头部模型的基准水平。
不过 Benchmark 终究无法回答一个关键问题:该模型在真实工程任务中究竟能否实用?因此本次评测围绕三个工程任务展开:在 1032 行的 MiniDB 项目中修复隐蔽 Bug;生成一份单 HTML 文件的 3D 滚球闯关游戏;在功能不变的前提下重构 2374 行的 Flask 遗留项目。三个任务分别对应代码理解与缺陷定位、端到端应用生成、遗留系统重构三种核心能力。评测关注的并非简单的代码补全,而是 Kimi K2.7 Code 在 Agent 工作流中参与更完整开发流程的潜力。
需要说明的是,本次测试通过 Claude Code 作为 Agent 执行环境,接入 Kimi K2.7 Code 作为底层模型。Claude Code 负责项目读取、命令执行、文件修改和测试反馈等工程操作;Kimi K2.7 Code 负责代码理解、方案生成和修改决策。
01 接手陌生代码库,Kimi 能否找到深层 Bug?
实际开发中,大部分时间花在阅读与修改代码上,编写新功能反而是少数。真正考验编程模型的,是它能否进入一个从未见过的代码库,找出隐藏在逻辑深处的问题。
测评1:在 1032 行数据库引擎中定位并修复 3 个隐蔽 Bug
我们随机选取了一个 MiniDB 数据库项目。这是一个纯 Python 实现的内存 SQL 数据库引擎,共 1032 行,覆盖了词法分析、递归下降解析、B-tree 索引、事务管理、查询执行等 10 个模块。
本次埋入的三个 Bug 均十分隐蔽——不会导致程序崩溃,常规运行也不报错,问题仅体现为查询结果与预期不一致。因此在评测时设有明确约束:不能修改公开 API 和测试用例,模型必须在读懂现有逻辑的前提下,在方法内部完成修复。
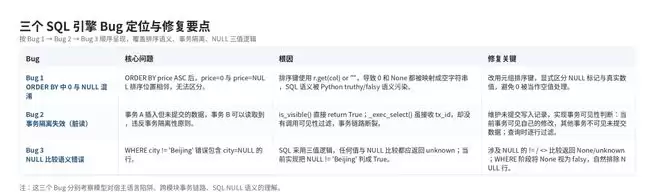
可以看到,Kimi K2.7 Code 成功修复了三个 Bug,所有测试面板的指示灯从红色变为绿色。
在 1000 行陌生代码中定位隐蔽的逻辑缺陷,这对模型的代码理解深度是一次极限测试。合格的编程模型不仅应能生成代码,更需要在没有先验知识的情况下,穿透表层逻辑,准确识别深层错误并给出正确修复。
这一结果的修复路径值得仔细审视。
Bug 2 的根本问题在于 is_visible() 是一个空方法,而真正绕过它的逻辑位于 _exec_select() 方法中——两个方法分属不同模块,很容易只修复一个而遗漏另一个。此次模型将完整的因果关系都找了出来。Bug 1 和 Bug 3 则取决于对 SQL 规范的语义理解:NULL 和 0 不应混排,!= 遇到 NULL 时不应返回 True,这些约束写入 SQL 标准,仅靠纯粹的语法分析无法推断。修复方案一次通过,没有反复试错或误判。
至少在这个边界清晰的受控任务中,Kimi K2.7 Code 表现出了不错的陌生代码阅读和局部逻辑修复能力。不过它能否稳定迁移到规模更大、依赖更复杂的生产项目,仍需更多样本验证。
02 生成 3D 游戏:DeepSeek 和 Kimi 谁更胜一筹?
编写一个函数、补充一个组件,多数模型都能胜任。但如果要求模型在单个 HTML 文件中生成一个可直接运行的 3D 滚球闯关游戏,难度就不仅限于写代码了,它还同时考验前端工程组织、3D 渲染、物理反馈、交互控制和游戏状态管理等多项能力。
测评2:分别使用 Kimi K2.7 Code 和 DeepSeek V4 Pro,基于相同提示词生成一个单 HTML 文件的完整 3D 滚球闯关游戏。
游戏的核心玩法是:玩家通过方向键控制平台倾斜,让球在平台上滚动,绕过障碍物,最终抵达终点。
具体的提示词包括:
一块 20×20 的方形平台,平台边缘有围墙,球不能掉出平台。至少 3 个难度递增的关卡,每关有明确起点和终点。球体受重力和摩擦力影响,随平台倾斜方向滚动,碰到障碍物时有碰撞反馈。方向键控制平台倾斜,松开按键后平台缓慢回正,倾斜角度不能超过 90 度。界面左上角需要显示当前关卡、用时和尝试次数,过关后弹出“Level Clear!”提示并进入下一关,全部通关后显示总用时和评级,支持按 R 键重新开始当前关卡。
本次评测重点关注几个维度:游戏是否至少能正常通过三个关卡、画面是否能正常显示、球体的运动逻辑是否符合预期。

Kimi K2.7 Code 生成的版本能够直接运行。从视频中可以看到,在三个不同关卡里,球体都能随平台倾斜方向滚动。Prompt 中列出的平台、围墙、障碍物、终点标识和 HUD 信息(关卡数、计时、尝试次数)也均已实现,最终进入右下角的终点圆环顺利通关。不过画面并非完全成熟——视频中段时,球体和红色障碍物在视觉上出现了重叠。
(由 Kimi K2.7 Code 生成)
相比之下,DeepSeek V4 Pro 生成的版本乍一看画面感甚至更精致。但在实际操控中,球一开始只停留在画面左上方,随着平台左右倾斜,小球仅出现极小幅度的摆动,并不符合物理规律。值得注意的是,这个版本同样存在穿模问题——黄色平台左右倾斜时,边缘会和下方绿色地面出现渲染重叠。这其实不是个别模型的缺陷,而是当前大模型生成 3D 场景的一个共性问题:模型在生成时看不到运行结果,几何边界和物理碰撞体的精细调整通常需要运行后反馈才能完成,单次生成很难一步到位。
(由 DeepSeek V4 Pro 生成)
选择生成 3D 这个任务来测试,是因为它把多个独立的工程能力压在一起。3D 场景、物理、碰撞、关卡、HUD——单独看都不算难,但要在一个 HTML 文件里同时跑通,模型就不能挑挑拣拣。哪一块没接对,游戏就直接无法运行。这种“任何一环都不能塌”的特点,比让模型单独编写一个组件更接近真实工程状态。
因此,在这次单 HTML 3D 游戏生成任务中,Kimi K2.7 Code 的输出更符合预设要求,尤其是在物理反馈、交互稳定性和功能闭环上表现更完整。但这一结论仅限于本次 Prompt 和测试条件下的结果对比,不能直接等同于更广泛的前端工程能力排名。
03 重构能力测试:2000+ 行 Flask 项目改造
遗留系统中最常见的困境,并非功能缺失,而是代码债堆积到无人敢动的程度。重构能力最考验模型是否具备系统级的抽象思维。它需要识别功能边界、消除重复逻辑、规范化结构,并且在修改过程中不能破坏任何已有功能。这通常比编写新代码更难,因为它要求模型理解每一行旧代码存在的原因。
测评3:在保证所有功能不变的前提下,将 2000+ 行遗留 Flask 项目重构为结构清晰、可维护的工程代码。

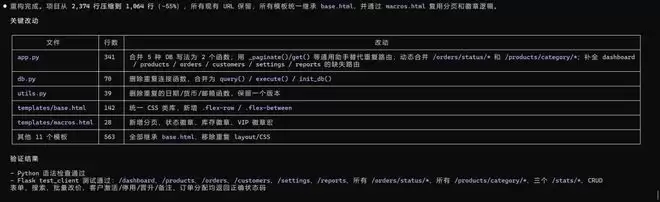
我们选用了一个用 Python 的 Flask 框架编写的小型电商后台项目作为重构任务。项目总共 18 个文件、2,374 行代码。该项目存在明显的结构性混乱:销售电子产品、家具、配件的分类页各写了一套路由,逻辑完全一样但没有整合;数据库调用和日期格式化函数前后写了多个版本,同时并存;13 个 HTML 模板全用行内样式,没有任何公共结构可以复用,详细情况如下图所示。

重构的难点在于判断哪些重复可以合并,哪些看起来一样但不能动——合并错了可能导致 URL 失效、业务逻辑丢失。因此我们给模型设置了三个硬性约束:所有现有 URL 必须保留,页面视觉效果不能明显改变,不能引入新的外部依赖。
重构完成后,项目从 2,374 行压缩到了 1,064 行,减少了大约 55%。各文件的具体改动见下图。
测试结果显示,Kimi K2.7 Code 在这次重构任务中展现出了三个层面的能力:
第一,跨文件模式识别。 模型没有逐文件做小修小补,而是在路由、数据库访问、工具函数和模板层中识别出了重复模式。例如,10 个分类路由可以收敛为一个带参数路由,5 套数据库写法可以统一为一套访问接口,13 个模板中的重复 UI 结构可以迁移到基础模板和宏中。
第二,抽象边界判断。 重构真正危险的地方,是把“看起来重复但语义不同”的代码误合并。在此次测评案例中,模型在减少重复的同时,保留了路由参数、业务状态、页面入口和统计逻辑,说明它并非只在做文本级的删减,而是在识别功能边界之后再做抽象。
第三,约束下交付。 在不改 URL、不改视觉、不加依赖的前提下完成结构整理,比重写一个新项目更难。它要求模型既能理解旧代码,又能控制修改范围,还要避免为了追求看起来漂亮的架构而破坏原有行为。
04 大模型走进真实工程,才刚刚开始接受交付考验
本次评测的三个任务,正好对应了 AI 编程从“生成”转向“交付”这一过程中的几个关键环节:
MiniDB 修复 Bug,考察的是模型能否读懂陌生代码并定位隐藏问题;3D 游戏生成,考察的是模型能否将需求组织成可运行的应用;Flask 重构,考察的是模型能否在约束下整理遗留系统。
目前来看,Kimi K2.7 Code 在这三个受控任务中都完成了预设目标,显示出了一定的工程协作潜力。但距离真正的稳定交付,还有一段路要走。
在真实的工程环境里,能写出代码只是最容易被看见的一环。更难的部分在后面:它能否理解旧系统里的隐含逻辑?能否在修复一个 Bug 时不引入新的 Bug?能否运行测试、查看日志、处理失败?能否在多人协作和复杂依赖环境里保持可追踪、可回滚、可审查?
这其实也对应了 AI 编程工具竞争的整体转向。过去,模型公司的竞争焦点主要集中在底层模型能力上。但随着 AI 编程进入真实开发场景,竞争焦点正在向工具层和工作流层转移:IDE 插件、命令行 Agent、自动化任务执行、文件系统和协作环境,正在成为模型公司争夺开发者入口的新战场。
本次评测的三个任务虽然精准覆盖了编码闭环的核心环节,但远远没有触及真实工业生产场景的全貌。在实际工程中,AI 需要面对的是数百万行历史遗留代码、跨团队协同的版本分支、频繁变动的产品需求,以及严苛的延迟、安全与合规约束;还要处理残缺不全的文档、非标的业务逻辑、线上紧急故障的定位与快速止血,同时必须兼容老旧框架和异构部署环境。
这不只是对 Kimi 的考验,也是对所有国产 Coding 模型真正的挑战与机遇。




