探索在群晖NAS上私有化部署DeepSeek-R1,打造本地化智能推理能力。本文将从几个关键方面展开:DeepSeek-R1模型及其与OpenAI-o1的性能对比、模型蒸馏技术的原理及其在DeepSeek-R1中的应用,以及在群晖NAS上部署DeepSeek-R1的具体步骤与优势。
简介
此前介绍的 deepseek-free-api 主要提供接口服务,让用户通过网络访问 DeepSeek 模型的能力。尽管用户能在本地容器中运行该API,但实际的模型推理和处理仍依赖远程服务器或云服务。使用这类方案,网络连接的稳定性和访问权限成为必须重视的关键因素。
什么是 DeepSeek-R1?
DeepSeek-R1 是 DeepSeek 推出的第一代推理模型,在数学、代码和推理任务中,其性能与 OpenAI-o1 不相上下。更重要的是,它还包含了基于 Llama 和 Qwen 的六个从 DeepSeek-R1 蒸馏出的密集模型,为不同应用场景提供了更灵活的选择。
什么是蒸馏?
蒸馏技术是一种模型压缩与优化的方法,其核心思路是将一个大型、复杂模型(教师模型)的知识,转移到一个较小的模型(学生模型)中。这个过程通常被称为“知识蒸馏”,能有效降低模型体积和计算开销。
其中 671b 是教师模型,另外的 6 个蒸馏模型作为学生模型:
1.5b:全称DeepSeek-R1-Distill-Qwen-1.5B,基于Qwen-2.5系列。7b:全称DeepSeek-R1-Distill-Qwen-7B,基于Qwen-2.5系列。8b:全称DeepSeek-R1-Distill-Llama-8B,基于Llama3.1-8B-Base。14b:全称DeepSeek-R1-Distill-Qwen-14B,基于Qwen-2.5系列。32b:全称DeepSeek-R1-Distill-Qwen-32B,基于Qwen-2.5系列。70b:全称DeepSeek-R1-Distill-Llama-70B,基于Llama3.3-70B-Instruct。
安装部署
Ollama 框架安装
首先,需要安装本地大模型运行框架 ollama。然后,根据机器的硬件性能,下载对应参数规模的 DeepSeek-R1 模型。
| 模型版本 | 适用场景 | 内存占用 | 推理速度 |
|---|---|---|---|
| 1.5b | 轻量级推理任务 | 3GB | 15 token/s |
| 7b | 日常对话交互 | 10GB | 8 token/s |
| 70b | 复杂逻辑推理 | 48GB | 2 token/s |
需要说明的是,ollama 除了支持 docker 方式部署外,也支持主流的操作系统(Windows、macOS 或 Linux)的二进制安装包。
在群晖 NAS 上,采用 docker 方式部署是一个常见且稳妥的选择。具体的操作指令如下:
# 新建文件夹 ollama 和子目录
mkdir -p /volume1/docker/ollama/data
# 进入 ollama 目录
cd /volume1/docker/ollama
# 运行容器(仅 CPU 模式)
docker run -d \
--restart unless-stopped \
--name ollama \
-p 11434:11434 \
-v $(pwd)/data:/root/.ollama \
ollama/ollama
# 进入容器
docker exec --user root -it ollama /bin/bash
# 下载模型
ollama pull deepseek-r1:1.5b
# 运行模型
ollama run deepseek-r1:1.5b
# 联网功能所需的文本嵌入模型
ollama pull nomic-embed-text
WebUI 前端选择
命令行模式终究不够直观。虽然支持 ollama 的 WebUI 很多,但最佳的交互体验组合无疑是 Open WebUI。不过,这里要推荐另一款更轻量级的工具——浏览器插件 Page Assist。
它以插件形式直接集成到浏览器的侧边栏,无需复杂配置即可一键调用本地部署的 AI 模型,让您从任意网页直接与模型进行交互。
相比传统 WebUI,Page Assist 具备以下技术优势:
| 特性 | 传统 WebUI | Page Assist |
|---|---|---|
| 部署复杂度 | 需独立服务部署 | 浏览器插件即装即用 |
| 资源占用 | 200MB+ 内存 | <50MB 内存 |
| 上下文感知能力 | 手动复制粘贴 | 自动捕获网页选区 |
| 多模型切换 | 需重新加载页面 | 实时无缝切换 |
目前支持的浏览器如下:
| 浏览器 | 侧边栏 | 与网页聊天 | 网页界面 |
|---|---|---|---|
| Chrome | ✅ | ✅ | ✅ |
| Bra ve | ✅ | ✅ | ✅ |
| Firefox | ✅ | ✅ | ✅ |
| Vivaldi | ✅ | ✅ | ✅ |
| Edge | ✅ | ❌ | ✅ |
| LibreWolf | ✅ | ✅ | ✅ |
| Zen Browser | ✅ | ✅ | ✅ |
| Opera | ❌ | ❌ | ✅ |
| Arc | ❌ | ❌ | ✅ |
运行与配置
连接设置
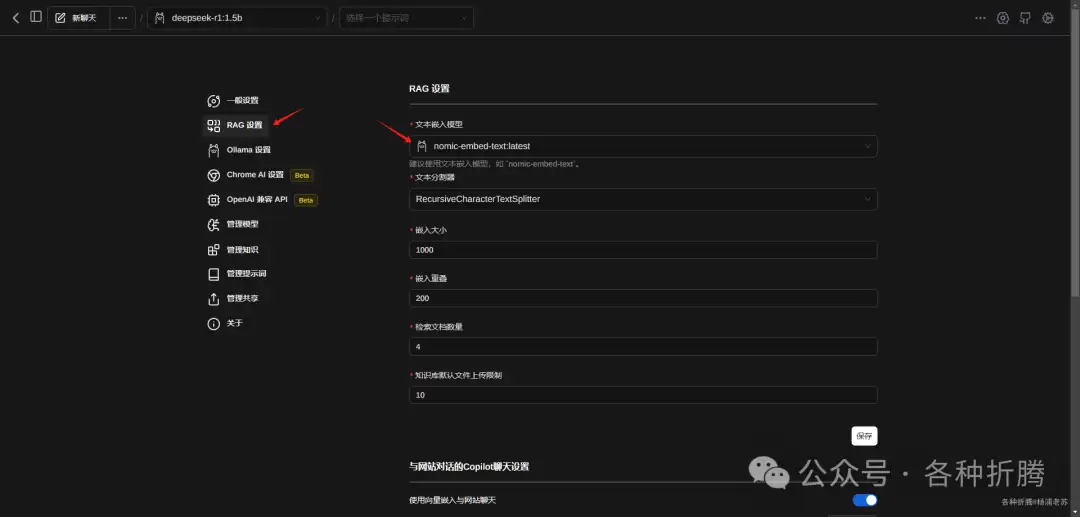
在浏览器中打开插件,可能会看到错误信息 Unable to connect to Ollama。这是因为安装环境并非本地,而是部署在 NAS 上,所以不能通过 127.0.0.1 或 localhost 访问。
- 单击右上角的
Settings图标。
- 单击选项卡
Ollama Settings。
- 修改
Ollama URL并点击sa ve保存。
- 展开
Advance Ollama URL Configuration选项,并启用Enable or Disable Custom Origin URL。
- 回到主界面,如果
Ollama URL地址配置正确,页面会显示Ollama is running的提示。
中文界面设置
这一步不是必须的,但为了方便使用,在设置界面 → General Settings,将语言设置为 简体中文 即可。
开始聊天
配置完成后,就可以开始自由聊天了。此例中使用了 1.5b 的模型。如果需要联网功能,则需配置文本嵌入模型。
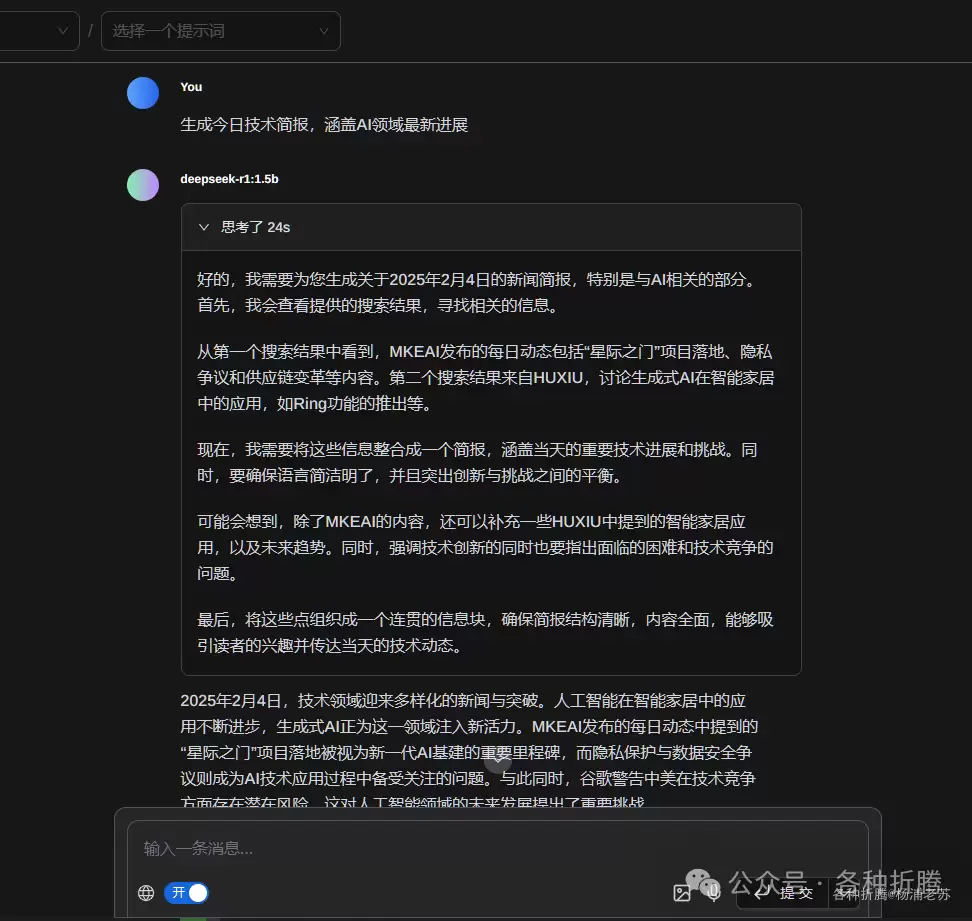
通常推荐使用 nomic-embed-text 作为嵌入模型。
侧边栏聊天
在任意网页上,选中 Page Assist 插件,右键菜单选择启动 侧边栏。
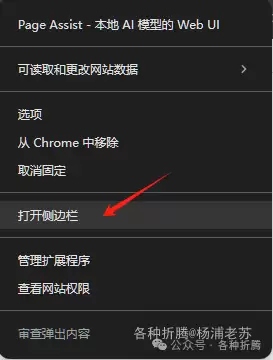
勾选 与当前页面聊天 后,就可以让模型对当前页面的内容进行总结或问答了。