来看一个有意思的发现。在网络安全攻防这场看不见硝烟的战场里,人工智能的定位正经历一次根本性的跃迁。6月23日,OpenAI 正式宣布对其“Daybreak”网络安全倡议进行全面升级,同时发布了一款专为安全研究人员和防御团队定制的新模型——GPT-5.5-Cyber。这可不是小打小闹的版本更新,而是意味着 AI 终于从“识别风险”这个初级阶段,迈入了“精准定位+自动修复”的实战新纪元。
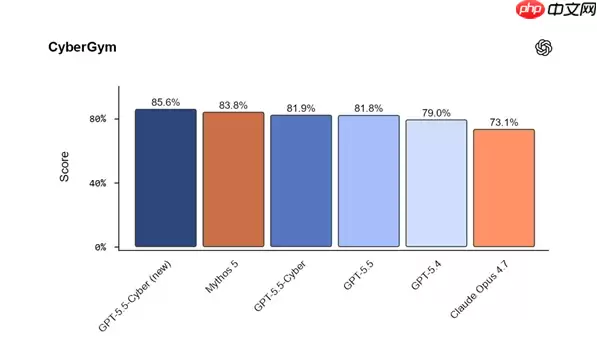
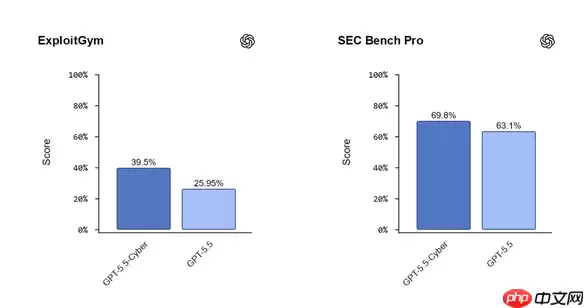
最新的权威基准测试结果,也证实了其技术上的领先身位。在专门评估漏洞发现能力的 CyberGym 测试中,GPT-5.5-Cyber 以 85.6% 的准确率拔得头筹,把 Claude Mythos5(83.8%)和通用版 GPT-5.5(81.8%)都甩在了身后,直接让 OpenAI 重返该细分赛道的冠军宝座。在考验漏洞利用转化能力的 ExploitGym 测试,以及聚焦复杂多步攻击链挖掘的 SEC-Bench Pro 测试中,它的表现也全面超越了基线模型。
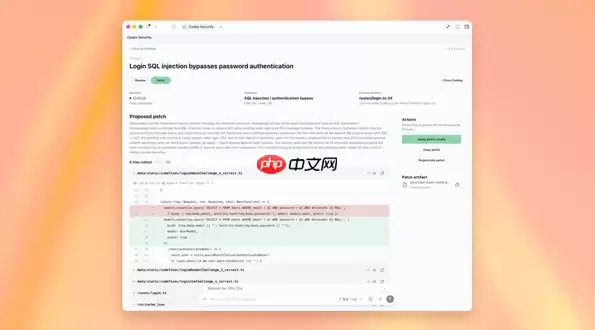
那么,OpenAI 为什么要费这么大劲搞这个?核心动因在于破解当前安全AI工具普遍存在的“诊断强、处置弱”困局。这话怎么说?多数系统虽然能高效识别潜在威胁,但到了深入研判影响范围这一步就开始卡壳,更别说生成可落地执行的修复方案了。GPT-5.5-Cyber 的任务,就是专门针对这个问题来的——它能穿透代码表层,逐行解析逻辑缺陷,不仅能复现完整的攻击路径,还能自动生成符合工程规范的安全补丁,供安全人员审核与部署。当这些输出无缝对接主流漏洞管理平台后,企业的响应周期有望从数天压缩到数小时。
值得注意的是,这款模型并非凭空构建,而是扎根于真实攻防一线的数据沃土。自今年3月 Codex Security 工具上线以来,它已经覆盖了超过3万个开源及私有代码仓库,完成了超过3亿次代码提交的安全扫描。数据也能说明一切:系统在此期间累计发现并协同修复漏洞达7万个,自动化生成并分发安全分析报告超过50万份。
业内专家的普遍共识是,GPT-5.5-Cyber 的推出,既是 OpenAI 在垂直安全领域持续投入的一个里程碑,更是对当前日益自动化的攻击浪潮所做出的关键反制。在攻击手段日趋智能化、规模化的大趋势下,这款兼具“侦察兵”与“手术刀”双重能力的 AI 模型,或将彻底重塑企业数字防线的构建逻辑,成为守护核心资产不可或缺的智能守门人。