今日行业热点:智谱AI正式推出新一代开源大模型GLM-5.1,官方宣称其为当前全球性能最强的开源模型。据官方介绍,它是唯一能实现8小时连续自主工作的开源模型。在更贴近实际软件开发的SWE-bench Pro基准测试中,GLM-5.1帮助国产模型首次超越Opus 4.6的得分。
同时,根据OpenRouter数据,随着本次发布,智谱GLM系列再次上调价格10%。调价后,GLM-5.1在编程场景下缓存命中Token的定价已接近Anthropic旗下Claude Sonnet 4.6。值得关注的是——这是国产大模型首次在核心应用场景实现与海外头部企业的价格对齐。背后传递的信号清晰:技术能力与定价策略正在同步追赶。
从几分钟的Vibe Coding到半小时的Agentic Engineering,再到此次推出的8小时Long-Horizon Task,GLM-5.1在研究方向上确实又迈出了重要一步。
官方介绍中有一句话尤其值得留意:GLM-5.1是迄今为止最智能的旗舰模型,也是当前全球最强开源模型。代码能力的进步尤为突出——不仅限于编写代码片段,而是能在单一任务中自主工作超过8小时,独立规划、执行、自我优化,最终交付完整的工程级成果。这与过去仅能进行分钟级交互的模型相比,完全是不同维度的提升。
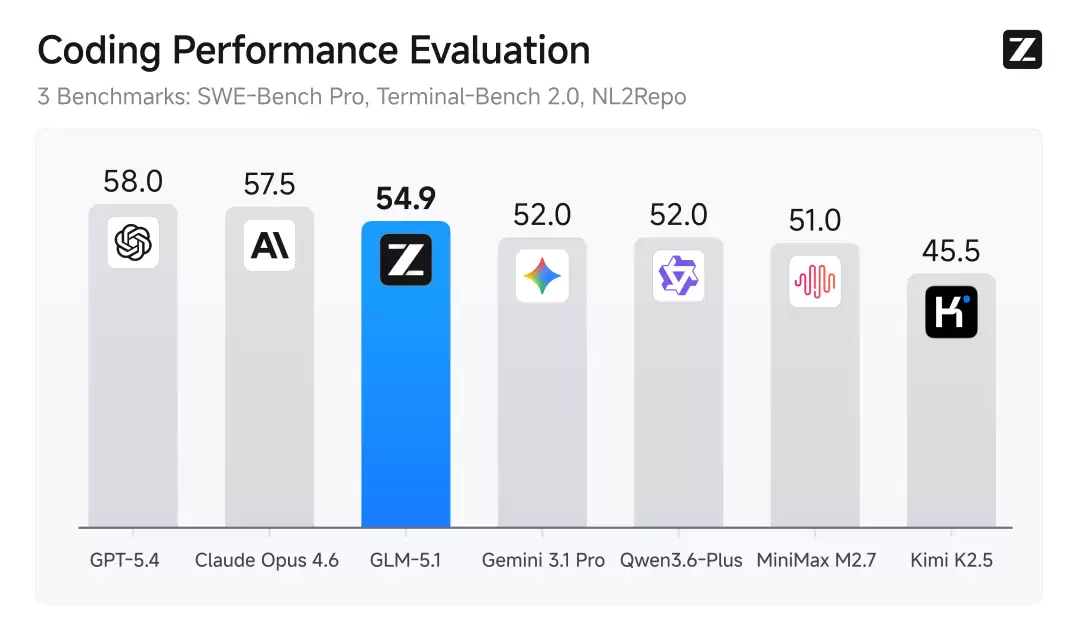
谈到代码能力,这正是衡量模型智能水平提升的关键指标。下图展示了业界最具代表性的三项代码评测基准的平均结果,包括评估专业软件开发的SWE-Bench Pro、通过命令行解决问题的Terminal-Bench 2.0、以及从零开始构建完整代码仓库的NL2Repo。在这三项基准上,GLM-5.1取得了全球第三、国产第一、开源第一的成绩。

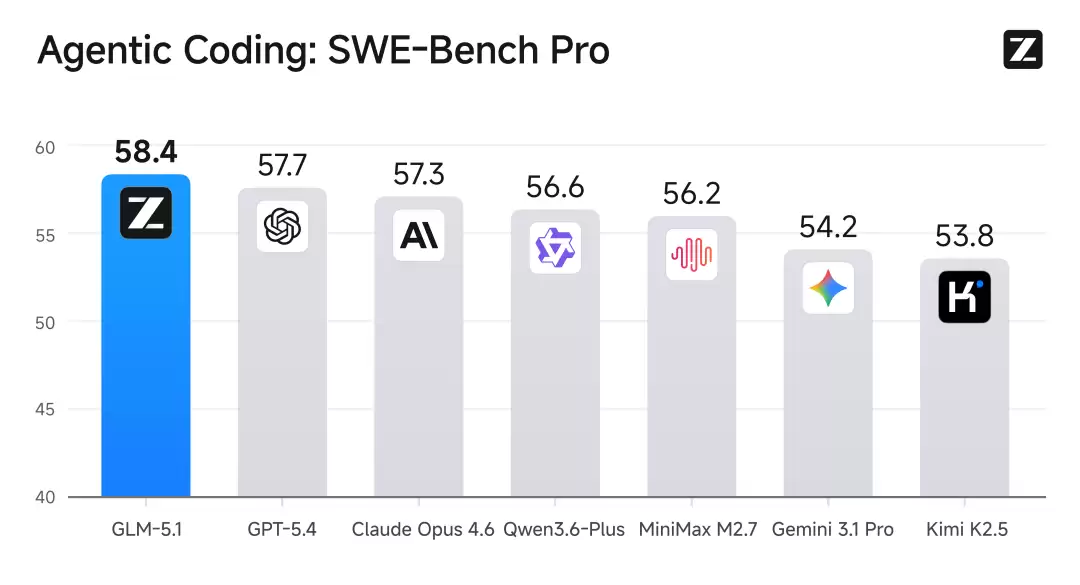
特别值得深入分析的是SWE-Bench Pro基准。该测试要求模型在真实GitHub仓库中定位并修复高难度工程Bug,被公认为衡量模型是否胜任专业软件开发的最严格标准。GLM-5.1在此项测试中刷新了全球最佳纪录,超越了GPT-5.4和Claude Opus 4.6。从这一角度而言,开源模型与闭源模型之间的能力差距正在逐步缩小。




