3D数字人行业正陷入一个发展怪圈:几乎所有公司都在拼命比拼“颜值”——模型是否足够精细、渲染是否足够逼真,仿佛只要视觉上接近真人,一切问题便能迎刃而解。但一个尴尬的现实摆在那里——即便建模再精致、渲染到4K画质,也撑不起用户长期深度交互的需求。
真正制约行业发展的天花板,从来不是“不像人”,而是数字人在表达层面始终未能实现与人类相似的自然流畅。很多时候,我们看到数字人嘴在动、手在挥,但肢体动作与对话语义完全脱节,面部表情和台词情绪根本不搭。这种深入骨髓的机械感和违和感,直接扼杀了建立情感联结、达成深度交互的可能性。
深入探究可知,人类日常沟通中,超过70%的信息和情绪其实都隐藏在非语言信号里——耸肩代表无奈,挑眉传递质疑,这些微小的细节才是对话的灵魂所在。但行业内目前面临三大瓶颈:一是中文对话场景的高质量数据极度匮乏,尤其是覆盖全身动作的数据集几乎空白;二是面对融合情绪的复杂表达时,模型对语义的理解能力显著下降,动作飘忽不定;三是音画节奏严重错位,动作生硬机械,与语音的重音、停顿完全对不上。
这三道枷锁,将数字人牢牢钉死在“预设脚本播放机器”这一角色上,始终无法实现从“能说话”“能动”到“懂交流”的关键跨越。正是在这一背景下,SentiPulse(思维光谱)联合中国人民大学高瓴人工智能学院推出的SentiA vatar交互式3D数字人框架,目标直指这些核心瓶颈。这是一套面向全球开源的3D动作生成完整解决方案,能让数字人跳出预设动作的束缚,实现贴合语境与情绪的自然实时交互,彻底告别“提线木偶”式的交互模式。
国内首个交互式3D数字人框架,让动作拥有“灵魂”
针对行业深层痛点,SentiA vatar打造了一套全新的3D动作生成范式。

在数据底座层面,团队构建了SuSuInterActs数据集,围绕单一角色SUSU(22岁,温柔活泼,情感丰富)展开。该数据集包含2.1万段片段、长达37小时的多模态对话语料,覆盖同步语音、行为标注文本、全身动作与面部表情——直接填补了中文高质量数据的空白。
为了让数字人交互摆脱“脚本化”,团队在预训练阶段引入了自研的Motion Foundation Model动作基础模型,在200K+条异质动作序列(约676小时)上训练通用运动先验。这样一来,数字人的能力范围远超单纯的对话场景。
此外,SentiA vatar创新性地提出了plan-then-infill双通道并行架构:在动作生成时,将身体动作与面部表情分开处理——先规划“做什么动作”,再插入“如何逐帧执行”,让整体动作生成效果更加流畅自然。
展开来说:第一阶段,LLM语义规划器接收行为标签文本和稀疏音频Token,输出稀疏关键帧动作Token序列。为支持多轮流式连续生成,模型以前一句话的最后两个关键帧音频-动作Token对作为上下文前缀,从下一个关键帧位置续写,实现无缝的跨句过渡。第二阶段,Body Infill Transformer在相邻关键帧之间填入中间3帧,以逐帧HuBERT连续特征(768维,20FPS)作为条件信号。模型采用5帧滑动窗口,首尾帧已知,预测中间3帧(12个动作Token)。推理时使用迭代置信度解码策略(默认6步),逐步接受高置信度的预测,避免一次性预测带来的质量退化。
权威实验结果显示,SentiA vatar在SuSuInterActs和行业通用BEATv2两个数据集上,多项核心指标均达到当前国际最优水平(SOTA),性能全面领跑行业主流模型。
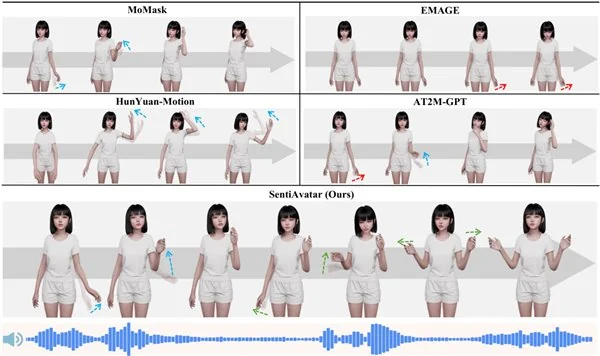
在自建的SuSuInterActs测试集上,SentiA vatar的文本-动作检索召回率R@1达到了43.64%,几乎是行业次优基线的2倍。在跨数据集、跨语言的BEATv2评测集上,SentiA vatar以FGD 4.941、BC 8.078的佳绩,同时刷新了这两项指标的SOTA纪录,超越了此前的行业最优方案,充分验证了模型在跨场景、跨语言上的泛化能力。
基于这套自研的高质量数据集、动作基础模型与核心架构,SentiA vatar实现了在0.3秒内生成6秒动作序列,支持无限轮次的流式交互。换句话说,数字人可以在实时对话中持续生成连贯的动作与表情,无需等待整句结束再批量处理——这直接解决了数字人“交互卡顿”这一长期存在的行业难题。
构建认知-表达闭环,夯实“交互底座”
SentiA vatar已正式上线GitHub开源平台,面向全球科研机构与开发者全面开放,相关技术报告也已同步发布于arXiv。开发者可以基于这套开源框架,低成本打造专属的3D数字人,也可将其拓展到游戏交互、影视制作、机器人等更多应用场景。
当数字人不再是冰冷机械的交互工具——它能读懂你面部表情中的隐喻,并反馈同样稀缺的情绪价值——它就变成了一个能感知语境、理解情绪、主动表达的交互主体。下一代的“数字生命”,正从这个起点上真正诞生。




