2026年4月9日,深圳,第三届数据存算生态大会如期召开。此次大会目标十分明确——聚焦计算能力与存储能力,深入探讨数据计算、存储及应用层面所面临的各类关键难题。现场汇聚了众多专家、学者及一线企业代表,交流氛围浓厚,技术碰撞激烈。

作为中国计算机行业协会信息数据存算专委会的副会长单位,浪潮数据在大会上重磅发布了融合存储技术战略与全栈AI原生融合存储解决方案。首席架构师张海军带来了题为《融存智用运筹新数据》的精彩演讲,深入探讨了AI时代存储技术的演进路径与丰富的实际落地经验。
智算时代数据爆发式增长,全面重塑存储需求
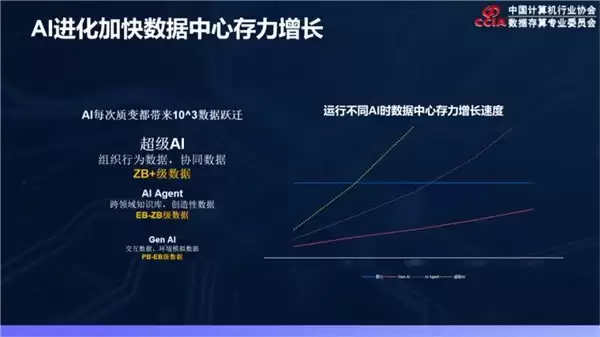
人工智能技术的迭代速度早已超越了“快速”的范畴——几乎呈现出指数级的跃迁态势。数据规模的急剧膨胀,对数据中心存储能力提出了前所未有的全新要求。张海军判断,随着大模型从千亿参数一路迈向万亿、十万亿参数,甚至演变为多模态模型,存储侧亟需打赢三场硬仗:
首先,是数据归集与预处理环节。面对海量的EB级原始数据,若缺乏高效的处理能力,后续工作根本无法推进。其次,是模型训练与微调阶段。当GPU集群规模达到十万卡级别时,对数据加载与恢复速度提出了极高要求,如何提升GPU利用率成为摆在眼前的现实难题。最后,是推理应用阶段。面对千亿Token级的日吞吐量以及超长上下文支持,存储系统必须主动作为——不仅要提升效率,还需有效抑制模型的“幻觉”问题。
融合技术战略,锻造AI原生存储强劲实力
面对这些挑战,浪潮数据的思路清晰而明确:通过介质融合、协议融合、管理融合、应用融合四大方向,全力打造一套具备卓越性能的产品能力体系。其最终目标是提供EB级存储空间、统一的数据视图、TB级集群带宽、亿级IOPS,以及数倍的推理加速效果。

介质融合:智能分层,巧妙平衡性能与成本
热数据、温数据、冷数据在时延、容量与成本方面存在显著差异。浪潮的解决方案是构建智能分层框架,通过高效的跨介质调度策略来应对。高性能层以全闪数据引擎为基础,结合NoF数据面与异步协程技术,将随机IO转化为顺序大IO,全闪时延可以压低至150微秒。分布式元数据KV引擎支持千亿级元数据的有序管理,单节点即可达到百万IOPS级别。值得关注的是,他们还创新地研发了动态归档技术,保留“元数据存根”,使得冷数据回调时用户完全无感。结合AI场景下10%热数据、10%温数据、80%冷数据的访问特征,该方案能够节省一半的热数据存储空间,TCO下降幅度高达60%。
协议融合:打破壁垒,实现语义无损访问
多协议、异构数据之间的壁垒一直是数据孤岛与效率损耗的主要源头。浪潮通过采用富元数据融合存储核心技术,构建起一套完整的语义标签体系,同时配合多协议的统一原子操作,实现了真正的语义无损访问。协议壁垒一旦被打破,存储空间可节省60%以上。借助富元数据结构统一元数据组织,多个存储服务可以实现实时互通,那些长期困扰用户的兼容性差、转换开销大等老问题,也因此获得了有效的破解之道。
管理融合:跨域统一,全力保障数据一致性
数据中心异地、异构建设带来的数据孤岛与一致性问题如何有效管理?浪潮采用统一抽象接口纳管异构设备,构建全局元数据统一视图。再配合原位元数据析取、增量日志、元数据对账等机制,多站点的数据一致性得到了可靠保障。业务数据亲和技术实现了智能缓存加速,回迁率可控制在30%以内。端到端的传输校验、跨域压缩与加密,确保广域传输既安全又高效,为跨数据中心计算提供了强有力的支撑。
应用融合:存算协同,深度激活数据价值
AI推理成本居高不下,长文本显存缺口较大,RAG系统实时性不足——针对这些痛点,浪潮通过API驱动应用集成来实现解决方案,推动数据近算的透明流动。他们创新的语义化分布式KVCache架构,使平均吞吐量提升超过两倍,多轮对话的首字延迟降低了60%,缓存复用率提升了40%。RAG计算融合技术让多源异构数据实现了零人工清洗融合,数据变更同步延迟被压缩到秒级,传统RAG系统更新周期长、实时性差的问题得到了显著改善。
万卡集群成功落地,有力验证技术领先性

这套全栈方案已在某国家级AI实验室的智算中心成功运行——支撑的是万卡级别的GPU集群,服务于万亿参数多模态MOE大模型的训练任务。面对EB级别的多模态数据、极端的带宽与IOPS需求,以及Checkpoint恢复缓慢等挑战,浪潮的方案交出了这样一份亮眼成绩单:数据准备时间节省30%,实现零数据重构扩容;每PB读写带宽分别达到140GB/s和53GB/s,超出预期指标210%;Checkpoint写入速度提升3倍,训练中断后可实现秒级恢复,模型迭代周期大幅缩短50%。这无疑是国内万亿参数大模型存储领域的标杆实践案例。
作为数据存算生态的核心参与者,浪潮数据始终聚焦于用户数字化转型的实际需求。在智算时代的发展浪潮中,他们将持续深化融合存储技术布局,携手产业各方,共同构建更健全的算力与存力生态,积极推动数据要素高效流通,为数字中国建设贡献实实在在的存储力量。




