DeepSeek R1与OpenAI o系列模型的爆发,再次掀起了人工智能领域的新一轮浪潮,甚至让业界看到了通往通用人工智能(AGI)的曙光。
这些性能强大的大模型背后,都离不开一项关键技术——强化学习(Reinforcement Learning)。
谷歌的DeepMind团队在这方面一直保持着领先优势,当年轰动全球的「人机大战」(李世石对战AlphaGo)就出自他们的杰作。
近日,DeepMind研究团队又取得了一项重大突破:他们利用改进的强化学习技术,在类似《我的世界》(Minecraft)的开放游戏环境中,成功让AI智能体的游戏水平超越了人类专家。

先简单介绍一下强化学习。本质上,这是一种让AI通过不断尝试和犯错来学习的方式,类似于人类掌握新技能的过程。AI在环境中采取行动,根据结果的优劣来持续调整自身策略。
那些在真实环境中一边探索、一边学习,收集观察数据和奖励信号,进而更新策略的算法,被称为在线强化学习。在线强化学习通常不预先构建“环境模型”,AI看到什么就学习什么,这种方法也叫无模型强化学习(MFRL)。但它有一个明显的短板——需要海量的环境交互数据。
因此,有人提出了基于模型的强化学习(MBRL),旨在减少训练所需的数据量。MBRL会先学习一个“世界模型”(World Model, WM),就像在脑海中模拟出一个虚拟世界,然后AI在这个模拟世界里进行“想象”与“规划”。这好比AI先在心里预演一遍,再付诸实际行动。
为了评估不同强化学习算法的效率,研究人员通常使用Atari-100k基准测试,观察算法在Atari游戏中使用不超过10万帧训练数据时的表现。但问题在于,Atari游戏的确定性较高,AI容易记住固定的操作模式,而非真正学会泛化。此外,Atari游戏通常只侧重一两个特定技能,难以全面评估AI的综合能力。
为了训练出能力更全面的AI智能体,DeepMind团队选择了Crafter这个环境——一个2D版本的《我的世界》。具体来说,他们使用的是Craftax-classic环境,这是Crafter的高效复刻版。
Craftax-classic具备几个突出特点:每次游戏的环境都是随机生成的,AI需要应对不同的挑战;AI只能看到局部视野,就像只能观察屏幕的一角,而非完整地图;它以成就层级来设定奖励信号,需要智能体进行深入且广泛的探索才能达成目标。
DeepMind这篇论文重点研究了如何在Craftax-classic环境中改进基于Transformer世界模型(TWM)的强化学习方法。研究人员从三个关键角度入手:如何有效使用TWM、如何将图像转换为TWM的输入格式、以及如何高效训练TWM。
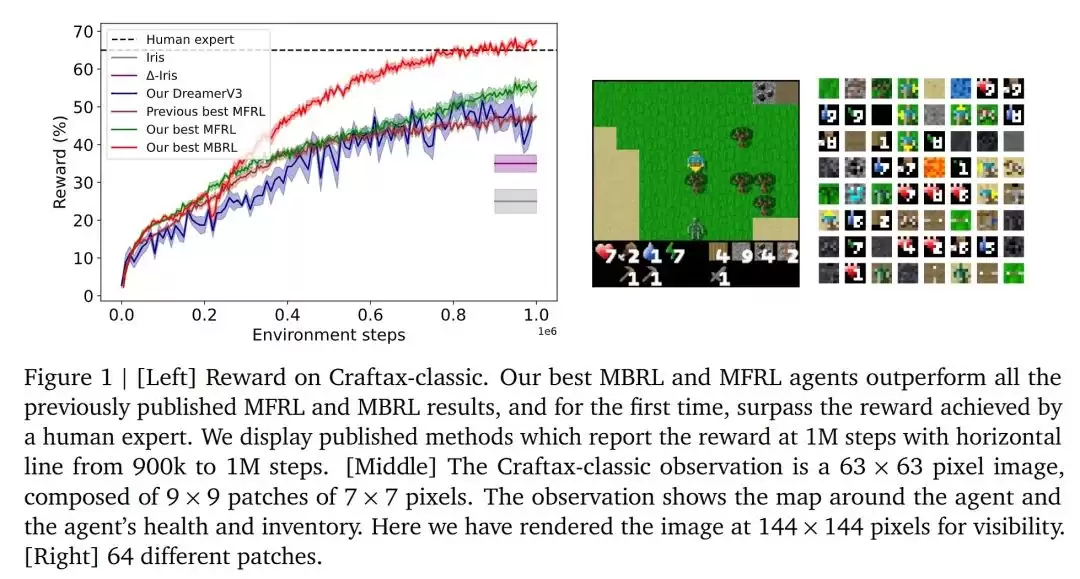
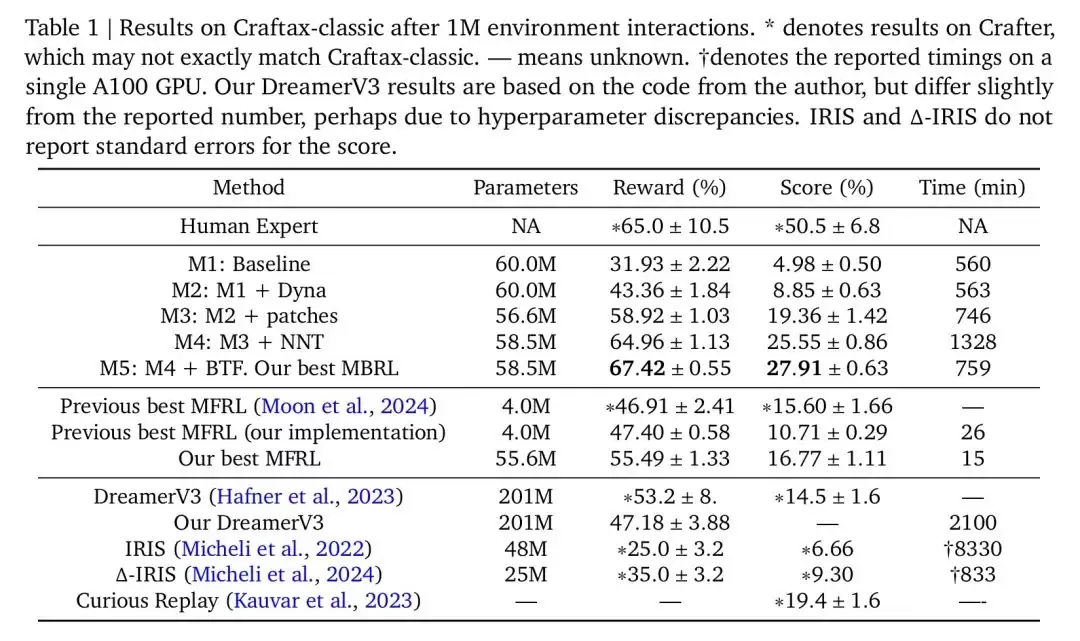
结果令人振奋!研究团队的方法让智能体仅通过100万步环境交互,就在Craftax-classic中取得了67.42%的奖励和27.91%的得分,相比此前最佳研究成果(SOTA)——53.20%的奖励和19.4%的得分——实现了显著提升。智能体的表现甚至超过了人类专家,这一成果相当惊人。
下图1展示了论文提出的MBRL方法在Craftax-classic环境中的性能。左图显示了不同算法随环境交互步骤增加所获得的奖励趋势;中间图是Craftax-classic的游戏画面,一块63×63像素的图像,包含智能体周围的地图以及生命值和物品栏信息;右图显示了NNT(最近邻标记器)提取的64个不同图像块,这些图像块被用作TWM(Transformer世界模型)的输入。
相关工作
基于模型的强化学习(MBRL)通常分为背景规划和决策时规划两种。背景规划在模型外部(即决策发生之前)利用世界模型(WM)生成想象轨迹,从而训练策略。而决策时规划则在做出决策的时刻借助WM进行前瞻搜索。由于决策时规划速度较慢,特别是使用类似Transformer这样的大型世界模型时更为明显,因此论文侧重于背景规划方向。
另一个关键问题是世界模型(WM)本身的设计。世界模型可分为生成式和非生成式两类。生成式世界模型能够生成(或想象)未来的观察结果,并以此辅助策略学习,从而提升强化学习的效率;而非生成式世界模型则仅使用自预测损失进行训练。相比之下,生成式世界模型更适合背景规划,因为它能方便地将真实数据与想象数据结合,用于策略学习。
训练方法
研究团队首先构建了一个基线模型。这个基线模型在环境中训练了100万步后,达到了46.91%的奖励和15.60%的分数。在此基础上,他们进行了两方面的改进:一是扩大模型规模,二是在策略中引入RNN(具体来说是GRU)以提供记忆能力。
有趣的是,他们发现如果只是单纯增大模型规模,反而会导致性能下降。但当更大的模型与精心设计的RNN结合时,性能得到了提升。关于RNN,研究团队认为保持隐藏状态维度足够小至关重要,这样才能让记忆仅关注当前图像无法提取的、真正重要的历史信息。
通过这些结构上的调整,模型的奖励指标提升到了55.49%,得分则达到了16.77%。性能上已经超越了更复杂、运行也更慢的DreamerV3(奖励53.20%,得分14.5%)。在性能提升的同时,成本也降低了——模型在一张A100 GPU上对环境进行100万步训练仅需约15分钟。
使用Dyna方法进行预热
接下来是论文提出的核心改进之一:如何高效地利用真实环境数据和世界模型(WM)生成的虚拟数据来训练智能体。
与通常只使用世界模型生成的轨迹进行策略训练不同,研究者受到Dyna算法的启发,并将其改进后应用于深度强化学习。Dyna方法将真实环境中的轨迹数据和TWM生成的想象轨迹数据混合起来训练智能体,本质上将世界模型当作一种生成式的数据增强手段。
智能体首先与环境交互,收集真实的轨迹数据,并立即用这些数据来更新策略。之后,智能体使用世界模型在想象中生成轨迹,并用这些想象数据来进一步更新策略。这种混合使用真实数据和虚拟数据的机制,可被视为一种生成式数据增强的方式。
论文强调,世界模型的准确性对策略学习至关重要。为了确保世界模型足够准确,避免其不准确的预测“污染”训练数据,研究者提出在开始使用想象轨迹训练策略之前,先让智能体与环境交互一段时间。这个过程被称为“预热(warmup)”。具体来说,只有在智能体与环境交互达到一定步数之后,才开始使用世界模型生成的轨迹来训练。实验表明,移除预热步骤会导致奖励大幅下降,从67.42%降至33.54%。此外,仅仅使用想象数据训练策略也会导致性能下降到55.02%。
图像块最近邻分词器
与传统使用VQ-VAE方法在图像和tokens之间进行转换不同,论文中研究团队提出了一种新的图像标记化(tokenization)方法,用于将图像转换为Transformer世界模型(TWM)可以处理的token输入。
研究团队利用了Craftax-classic环境的一个特性:每个观察图像都是由9×9个7×7大小的图像块组成的。因此,他们首先将图像分解为这些不重叠的图像块(patches),然后独立地将每个图像块编码为token。
在图像块分解的基础上,论文使用了一个更简单的最近邻标记器(Nearest-Neighbor Tokenizer, NNT)来取代传统的VQ-VAE。NNT的编码过程类似于最近邻分类器,它将每个图像块与一个代码本中的条目进行比较。如果图像块与代码本中最近的条目之间的距离小于一个阈值,则将该条目的索引作为token;否则,将该图像块作为一个新的代码添加到代码本中。
与VQ-VAE不同,NNT的代码本一旦添加条目,就不再更新——代码本是静态的,但可以不断增长。解码时,NNT只是简单地返回代码本中与token索引相对应的代码(图像块)。这种静态但不断增长的代码本使得TWM的目标分布更加稳定,大大简化了TWM的在线学习过程。
实验结果显示,在图像块分解的基础上,用NNT替换VQ-VAE可以显著提高智能体的奖励,从58.92%提升到64.96%。不过,NNT对图像块的大小比较敏感,如果图像块大小不合适,可能影响性能;此外,如果图像块内部的视觉变化很大,NNT可能会生成一个非常大的代码本。
块状教师强制
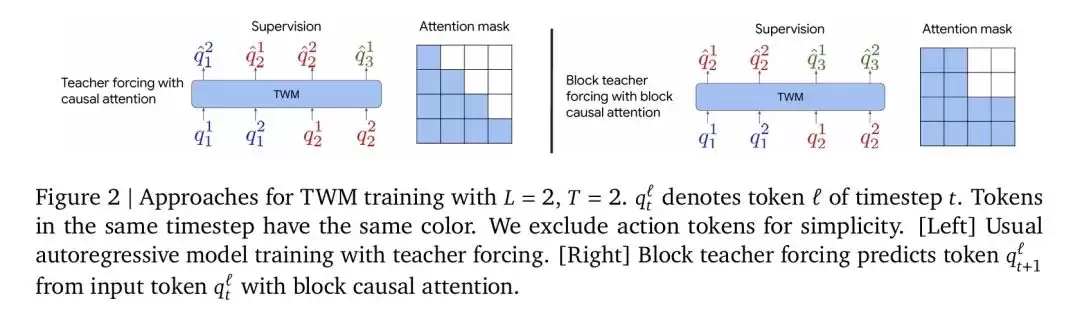
在通常的做法中,TWM通常采用教师强制来训练。论文的研究团队则提出了一种更有效的替代方案,称为块状教师强制(block teacher forcing, BTF)。这个方案同时修改了TWM的监督方式和注意力机制:当给定前面的全部token后,BTF会并行预测下一时间步中的所有潜在token,从而不再依赖当前时间步已生成的token。
下图2清晰地展示了BTF如何通过改变注意力模式和监督方式来改进TWM的训练。传统的教师强制自回归地预测每个token,而BTF则并行预测同一时间步的所有token,从而提高了训练速度和模型准确性。
实验表明,与完全自回归(AR)的方法相比,BTF能得到更准确的TWM。在本实验中,BTF将奖励从64.96%提升到了67.42%,从而获得了表现最优的基于模型的强化学习(MBRL)智能体,一举超越了人类专家的表现。(见表1)
实验结果
性能阶梯
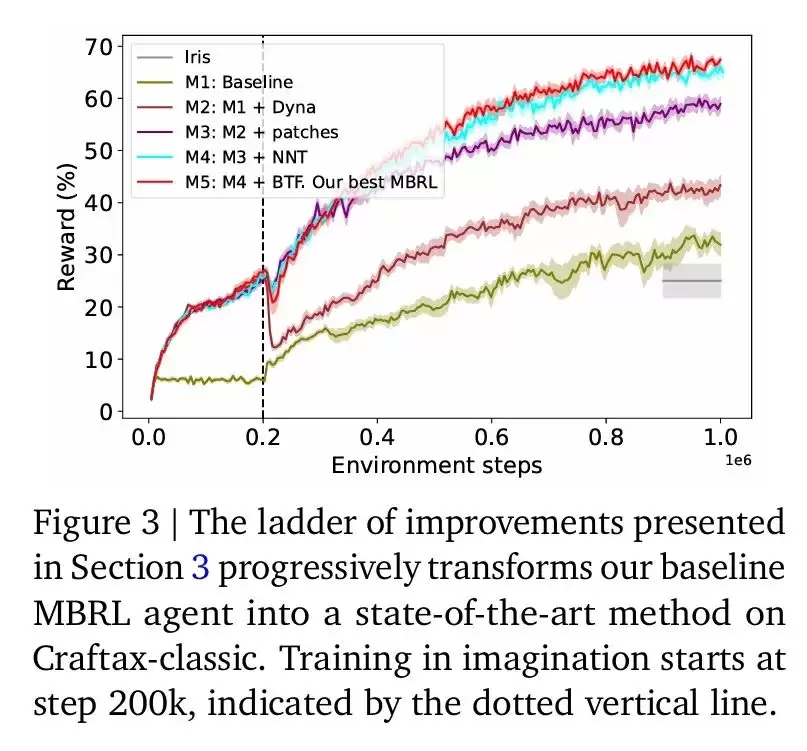
在论文中,智能体按照研究者所采用的改进措施进行排序,形成了一个“MBRL阶梯”,具体如下:
M1: Baseline——基准MBRL智能体,使用了VQ-VAE进行tokenization,奖励31.93%,优于IRIS的25.0%。
M2: M1+Dyna——在M1的基础上,使用Dyna方法,混合真实环境数据和TWM生成的想象数据来训练策略,奖励提升至43.36%。
M3: M2+patches——在M2的基础上,将VQ-VAE的tokenization过程分解到各个图像块(patches)上,奖励进一步提升至58.92%。
M4: M3+NNT——在M3的基础上,用最近邻标记器(NNT)替换VQ-VAE,奖励提升至64.96%。
M5: M4+BTF——在M4的基础上,引入块教师强制(BTF),最终奖励达到67.42%(±0.55),成为论文中最佳的MBRL智能体。
下图3清晰地展示了每一步改进带来的性能提升。
与现有方法比较
研究团队性能最优的模型M5创造了新的SOTA成绩,奖励达到67.42%,得分达到27.91%。这是首次超过人类专家的平均奖励水平(该人类水平基于5名专家玩家玩了100局所测得)。需要指出的是,尽管模型在奖励上已超越了人类专家,但得分仍明显低于人类专家水平。
消融实验
实验表明,当NNT使用7×7大小的图像块时效果最佳,使用较小(5×5)或较大(9×9)的图像块时,性能会有所下降,但仍然具有竞争力。如果不使用量化,而是让TWM重建连续的7×7图像块,性能会大幅下降。
研究者发现,移除“MBRL阶梯”中的任何一个步骤,都会导致模型性能下降,这表明论文提出的每个改进都至关重要。
下图5可视化地展示了消融研究的结果,验证了论文提出的各个改进措施的重要性。
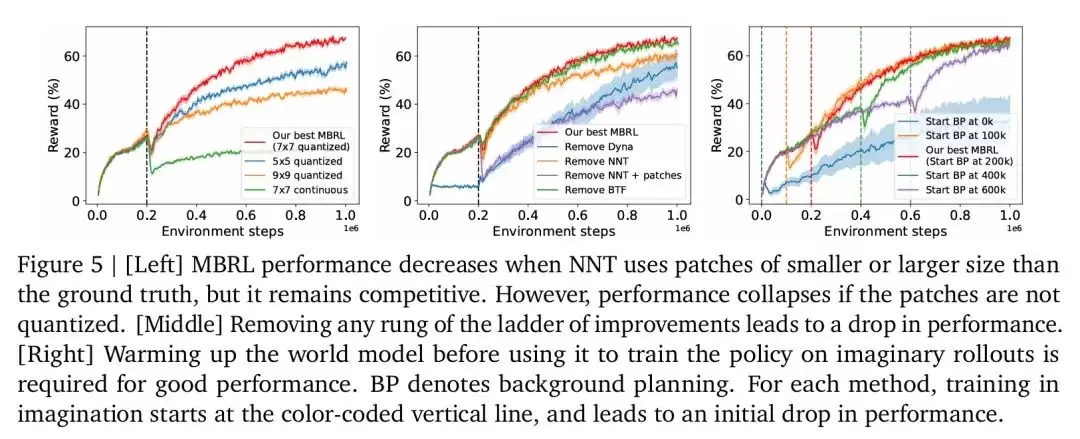
模型如果过早地开始在想象数据上训练,性能会因TWM的不准确而崩溃。只有在智能体与环境交互足够长时间,并获得足够数据来训练可靠的WM后,使用想象数据进行训练才是有效的。
去除MFRL智能体中的RNN或使用较小的模型都会导致模型性能下降。
比较TWM的生成序列
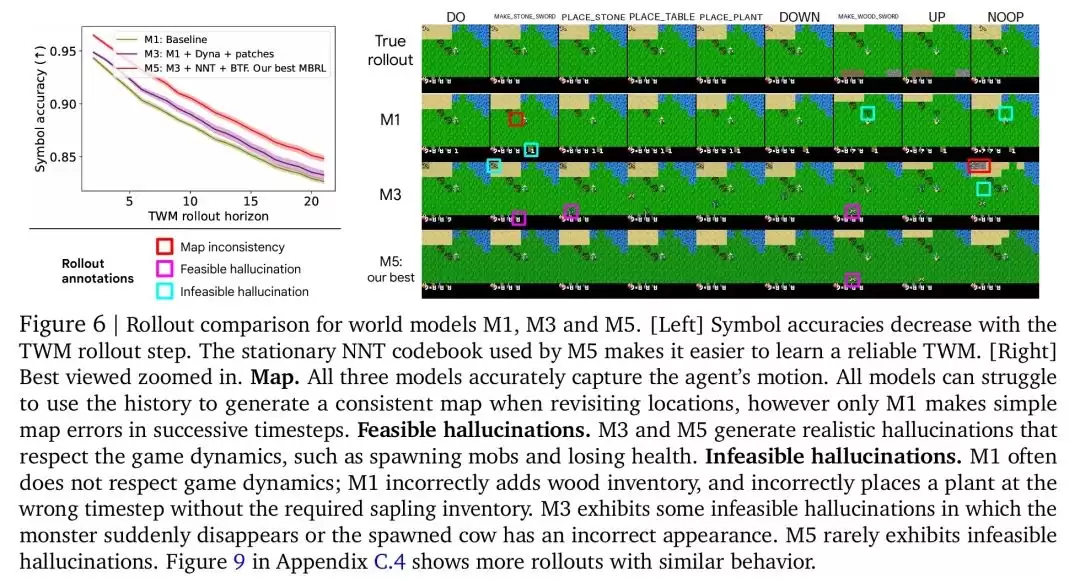
研究者比较了三种不同的世界模型(TWM)的生成轨迹质量:M1(基线模型)、M3(加入了Dyna和图像块分解的模型)以及M5(最佳模型,包含了所有改进)。
为了进行评估,研究者首先构建了一个包含160条轨迹的评估数据集,每条轨迹长度为20。然后,他们使用每个TWM模型,从相同的起始状态和动作序列出发,生成对应的想象轨迹。评估的关键指标是通过训练一个CNN符号提取器,来预测真实轨迹和TWM生成轨迹中的符号,并计算预测的符号准确率。这种方法能深入了解模型在多大程度上捕捉到了游戏的核心动态。
定量评估:通过定量评估,研究团队发现符号准确率随着TWM生成轨迹步数的增加而下降——这种下降是由于误差的累积导致的。M5模型由于其采用了最近邻标记器(NNT),保持了所有时间步中最高的符号准确率,表明其能够更好地捕捉游戏动态,且NNT使用的静态代码本简化了TWM的学习过程。
定性评估与分析:除了定量评估,研究团队还对TWM生成的轨迹进行了定性分析。通过视觉检查,他们观察到了三种现象:地图不一致性、符合游戏规则的幻觉以及不符合游戏规则的幻觉。M1模型在地图和游戏动态方面都存在明显的错误,而M3和M5模型能够生成一些符合游戏规则的幻觉,例如出现怪物和生命值变化。M3模型仍然会产生一些不符合游戏规则的幻觉,例如怪物突然消失或生成的动物外观错误,而M5模型则很少出现这种不合理的幻觉。
定性分析表明,尽管所有模型都存在一定的误差,但M5模型在保持游戏动态一致性方面明显优于其他模型,体现了其学习到的世界模型质量的提升。
下图6表明,NNT和BTF等改进措施对于提高TWM学习效果的重要性,最终促进了MBRL智能体性能的提升。
Craftax完整版本测试结果
研究团队还比较了多种智能体在Craftax的完整版本(Craftax Full)上的性能。相比Craftax-classic,这个完整版在关卡数量和成就设置上都有显著提升,难度更高。此前的最佳智能体只能达到2.3%的奖励,而DeepMind团队的MFRL智能体取得了4.63%的奖励,MBRL智能体则更是将奖励提高到5.44%,再次刷新了SOTA纪录。这些结果表明,DeepMind团队所采用的训练方法能够推广到更具挑战性的环境。
结论与下一步工作
在本论文中,DeepMind研究团队提出了三项针对基于Transformer世界模型(TWM)的视觉MBRL智能体的改进措施:带有预热的Dyna方法、图像块最近邻标记化(NNT)以及块教师强制(BTF)。这些改进结合起来,使得MBRL智能体在Craftax-classic基准测试中取得了显著更高的奖励和分数,首次超越了人类专家的奖励水平。论文提出的技术也成功地推广到了更具挑战性的Craftax(full)环境中,取得了新的SOTA结果。
下一步工作:DeepMind研究团队未来将研究如何将这些技术推广到Craftax之外的其他环境,以验证其通用性;探索使用优先经验回放来加速TWM的训练,以提高数据利用效率;还考虑将大型预训练模型(如SAM和Dino-V2)的能力与当前的标记器结合起来,从而获得更稳定的代码本,并减少对图像块大小和表观变化的敏感性。此外,为探究无法生成未来像素的非重构型世界模型,团队还计划改造策略网络,使其能够直接接收TWM生成的潜变量token,而不是像素。




