4月26日,具身智能公司超维动力Kinetix AI(KAI)搞了一场不太一样的发布会。怎么说呢?没有惯常的“下面有请产品登场”,而是让两台名叫“KAI”的人形机器人自己上台,来了一段对谈和自我介绍,顺便把技术路线和产品定位一并交代了。这倒挺有意思——产品还没亮相,先让你听它自己说。

联合创始人Tyler在发布会上点明了核心思路:机器人真要融入人类世界,就得足够“拟人”。在他看来,人类的物理智能是在和世界互动中磨出来的,所以机器人至少得把三件事串成一个闭环——理解世界、学习世界、与世界交互。对应的,就是物理世界模型、第一人称数据集,以及高拟人本体。
理解世界,靠的是世界模型
所谓理解世界,不只是让机器人感知当前环境,还得能对接下来的变化做出预判。超维动力把这一块叫作KAI World Model。目前这套世界模型系统已经跑通了一个闭环结构:除了主体模型,还搭配了动作模块和评估模块。动作模块会根据当前状态生成候选动作,然后交给基模型去推演未来状态;接着评估模块再对整条轨迹做价值判断——比如任务进展怎么样、有没有安全接触风险。说白了,就是让机器人不只是“看”,还得“想一步”。
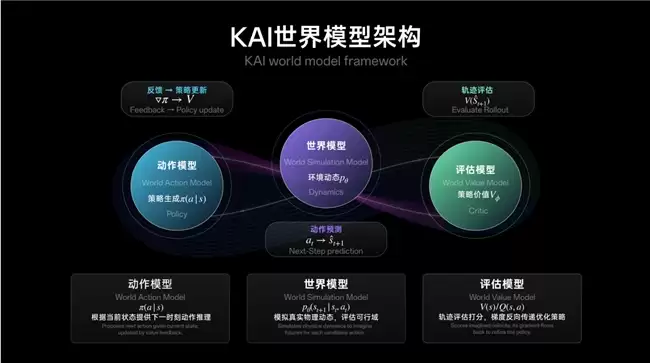
学习世界,靠的是第一人称数据
世界模型解决的是“懂”,那“学”的部分就交给第一人称数据集。思路不复杂:让机器人通过人类的视角和动作去接触世界,这样获得的数据更贴近真实场景,而不是实验室里刻意编排出来的脚本动作。
为此,超维动力自研了一套规模化的数据采集终端——KAI Halo。这个设备做成了轻量化的头环形态,“一芯八摄”,能一站式完乘人类世界的各类数据采集。不仅能录第一人称视频,还能做人体姿态和场景点云重建。关键是它足够轻便,戴在头上不影响日常工作,采集过程不用刻意编排脚本,数据自然就更真实。相比那些“按剧本走”的动作流程,这类数据往往包含更多样化的动作细节,对人形机器人的训练价值更高。

把经验变成技能,三阶段训练体系
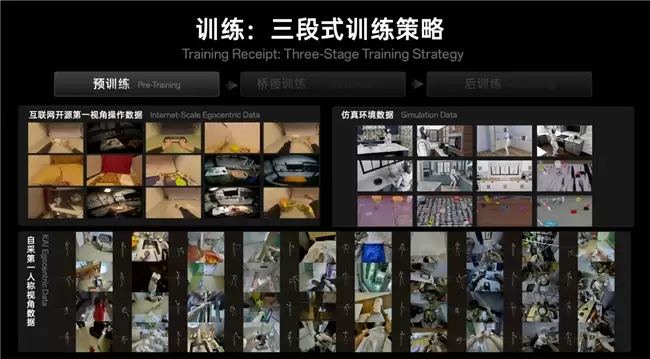
理解有了,经验也有了,接下来就是怎么让机器人把这些“知觉”转化成实实在在的动作技能。超维动力的解法是一套三阶段训练体系。
首先是预训练阶段。用大量互联网和仿真数据打底,再补充自采的第一人称视角数据,重点补足全身与环境交互的语义信息。目标是帮KAI建立起“空间—语言—视觉—任务动作”对齐的常识体系。第二阶段是桥接训练。这里用到UMI和数采手套等工具,专门补一下预训练阶段里精细手部动作和物理接触的短板。最后是后训练阶段,引入具体场景的真机遥操数据,用来解决本体对齐的问题。三个阶段串下来,KAI才能真正把手上的“经验”变成可执行的技能。
承载能力的身躯——KaiBot
数据和大脑都齐了,最后一步就是给这套系统配一个能融入日常生活的身体。这个身体就是KaiBot。据官方介绍,它的设计从四个层面去贴近人类——体型、体格、体能和感知。

体型方面,KaiBot身高173厘米,体重70公斤,头身比1:8.5。整体质量和比例接近成年人类,重心分布也做了拟人化处理,保证稳定性的同时,外形没有那种机械感。
体格上,它拥有115个自由度。肩部上抬范围从-20°到0°,环抱范围-15°到0°,颈部活动范围-15°到50°,腰部-15°到75°。这些参数意味着它的全身运动空间非常接近真人,能在复杂环境里像人一样自然摆弄肢体。重点在于它的灵巧手——单手36个自由度,其中22个主控自由度、14个柔顺自由度。既能完成抓握、捏取这类精细动作,也能在碰撞时起到缓冲作用,整体交互更安全也更自然。

体能方面,KaiBot配备了一块1.7kWh的半固态电池,支持大约3小时的双臂操作任务。定制化的柔顺执行器帮它实现了更接近人体的运动柔顺性,双臂负载接近20公斤。友好性和作业能力之间,算是找到了一个平衡点。
感官层面,KAI全身覆盖了一套触觉皮肤系统。18000个触点,理论上能感知到大于0.1牛顿的轻微触碰,并做出反馈。这种触觉系统让人形机器人在真实的近距离协作或陪伴场景中,能建立起更高质量的反馈闭环,而不是“感知盲区”里的机器人。

发布会接近尾声时,KAI自己说了这么一段话:“我不是为了在无人工厂里搬运重物而被创造出来,更不是为了在舞台上表演极限翻滚。我被创造出来,是为了走进您的客厅、办公室,去理解您的意图,回应触碰,并最终与您一起协作、共处。”这句话,其实才是整场发布会真正的注脚——产品定位从一开始,就不是工业机器人,而是人类生活里的伙伴。




