在自动语音识别(ASR)领域,大模型技术正从短音频片段处理向长时音频理解方向演进。微软近期开源的 VibeVoice-ASR 模型,正是这一趋势的重要标志。这款拥有 90 亿参数的统一模型,其核心优势在于:一次性处理长达 60 分钟的连续语音流,并在一次推理过程中直接生成包含说话人标识、精确时间戳及对应文本的结构化转录输出。更关键的是,它还允许用户灵活注入特定领域的专属热词,从而显著提升对专业术语和上下文敏感词汇的识别准确率。
该模型最直接的价值体现在它如何解决长音频处理中常见的几大难题:上下文断裂、说话人混淆、输出格式不清晰。VibeVoice-ASR 提供了一套端到端的系统性解决方案。
VibeVoice-ASR 核心特性与能力
- 原生支持最长 60 分钟的端到端音频处理。传统 ASR 模型在处理长音频时往往需要将音频切分为数秒的短片段,这种做法极易导致上下文信息丢失和说话人身份断裂。VibeVoice-ASR 原生适配最大 64K token 的音频序列,能够完整覆盖一小时的语音内容,从而确保跨时段说话人一致性建模以及语义连贯性。简而言之,它无需拼接即可一次性完成整段语音的识别。
- 可配置的热词引导机制。该功能非常实用,用户可通过简洁的接口传入自定义热词列表,例如企业名称、产品型号、学术术语等。模型在解码阶段会动态提升这些相关词元的概率权重。在医疗、法律、金融会议等垂直场景中,这一机制能显著提升识别精度。
- 三位一体结构化输出(Who-When-What)。这是 VibeVoice-ASR 在输出方面的突出亮点。它将语音识别、声纹分割与时间定位深度整合,同步实现说话人分离、起始与结束时间标注以及文本转写。最终输出结果清晰可解析,格式为「谁 在 何时 说了什么」。对于后续的会议纪要生成、访谈整理、内容检索等应用场景,这种结构化数据极为便捷。
模型的整体架构如下:
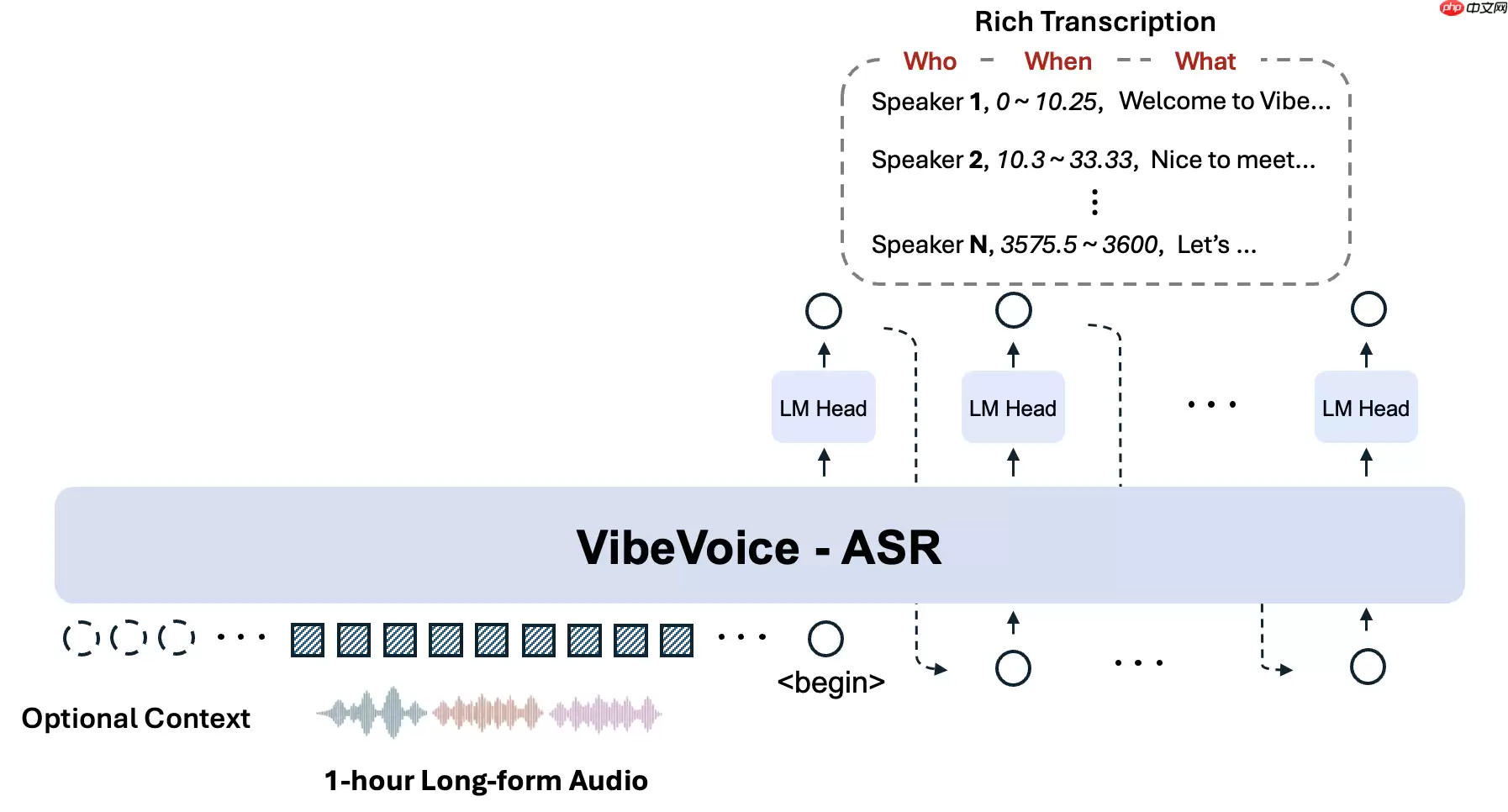
开源地址
https://www.php.cn/link/c165343f46d5946c6f76c58a5ed0f52c
https://www.php.cn/link/4d0d3acf6bc4d8f28d53f73a2879dc3e




