软银集团旗下的Infrinia团队近期低调发布了一项重要创新——正式推出了专为下一代AI数据中心设计的软件平台:“Infrinia AI Cloud OS”。
该平台的核心理念在于,借助智能化自动化技术,将整个GPU算力全栈——从底层硬件、中间系统层到顶层应用层——进行全面整合,实现统一管理与调度。其目标非常明确:高效应对生成式AI、智能机器人等前沿领域对GPU资源爆发式增长且高度异构化的需求。简单来说,就是有效解决GPU资源调度难题,让管理更加轻松。
在具体能力方面,Infrinia AI Cloud OS原生集成了Kubernetes即服务(KaaS)能力,全面支持英伟达GB200 NVL72等主流GPU硬件架构。同时,从BIOS固件、操作系统、GPU驱动、高速网络、Kubernetes控制平面,到分布式存储——这些全链路组件均可实现自动部署、配置与运维,真正做到了全方位的自动化管理。
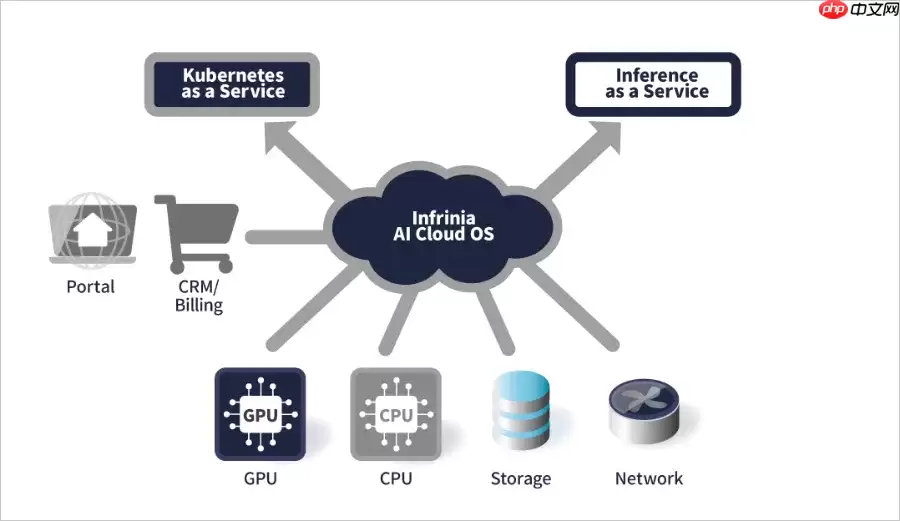
更值得关注的是,该平台具备基于软件定义的动态物理互连与内存虚拟重构能力。具体而言,当你发起集群创建或销毁操作时,系统能够实时重新配置GPU节点间的物理连接拓扑,并动态调整跨节点内存映射关系。此外,它还能结合GPU硬件级的拓扑结构,智能分配节点资源。最终效果是:在保证低通信延迟的前提下,充分释放互联带宽,显著提升大规模分布式AI模型训练的效率。
当然,安全防护同样完善。在多租户运行环境下,Infrinia AI Cloud OS深度融合了零信任安全理念——采用端到端加密通信、强隔离沙箱机制以及细粒度权限管控,确保租户间数据与计算资源的绝对隔离。同时,平台内置智能运维引擎,可自动执行健康监测、异常诊断、故障自愈与无缝切换等关键运维任务。
据悉,该平台将首先部署于软银自营的GPU云基础设施,后续逐步扩展至全球范围内的第三方数据中心与公有云生态。总体而言,这不仅是软银在AI基础设施领域的一次重要战略布局,也标志着行业正朝着“智能运维+异构算力统一调度”方向迈出关键一步。




